目录
第一章:开篇 - 当算法遇上广告
“在广告投放的战场上,算法就是你的武器,数据就是你的弹药。”
1.1 一个真实的场景
想象这样一个想·场景:
凌晨3点,你躺在床上刷着手机,突然看到一条运动鞋的广告。点开一看,正好是你最近想买的那款,尺码、颜色都合适,价格还比其他平台便宜50块。你毫不犹豫地下单了。
这看起来像是巧合,但实际上,这背后是一套精密的算法系统在工作:
- 特征捕获:你最近搜索过”跑步鞋”,浏览过运动装备,停留时间较长
- 模型预估:CTR模型预测你有23.7%的概率会点击这个广告
- 智能出价:CVR模型预测你有8.5%的转化概率,系统计算出最优出价
- 实时竞价:在100ms内完成30+维度过滤、模型预估、出价决策
- 精准投放:广告恰好在你最有购买欲望的时刻出现
这一切,都发生在不到100毫秒的时间里。
1.2 程序化广告的革命
1.2.1 从粗放到精准
传统广告投放就像”广撒网”:
- 在电视台买时段,覆盖百万观众,但只有0.1%是目标用户
- 在门户网站买横幅广告,展示给所有人,转化率不到1%
- ROI极低,广告主的钱大部分都浪费了
程序化广告的出现彻底改变了这一切:
传统广告:
投入 100万 → 触达 1000万人 → 转化 1万人 → ROI = 1%
程序化广告(算法驱动):
投入 100万 → 精准触达 100万人 → 转化 5万人 → ROI = 5%提升5倍的背后,就是算法的力量。
1.2.2 RTB实时竞价的博弈
每一次广告展示,都是一场激烈的实时竞价(RTB, Real-Time Bidding):
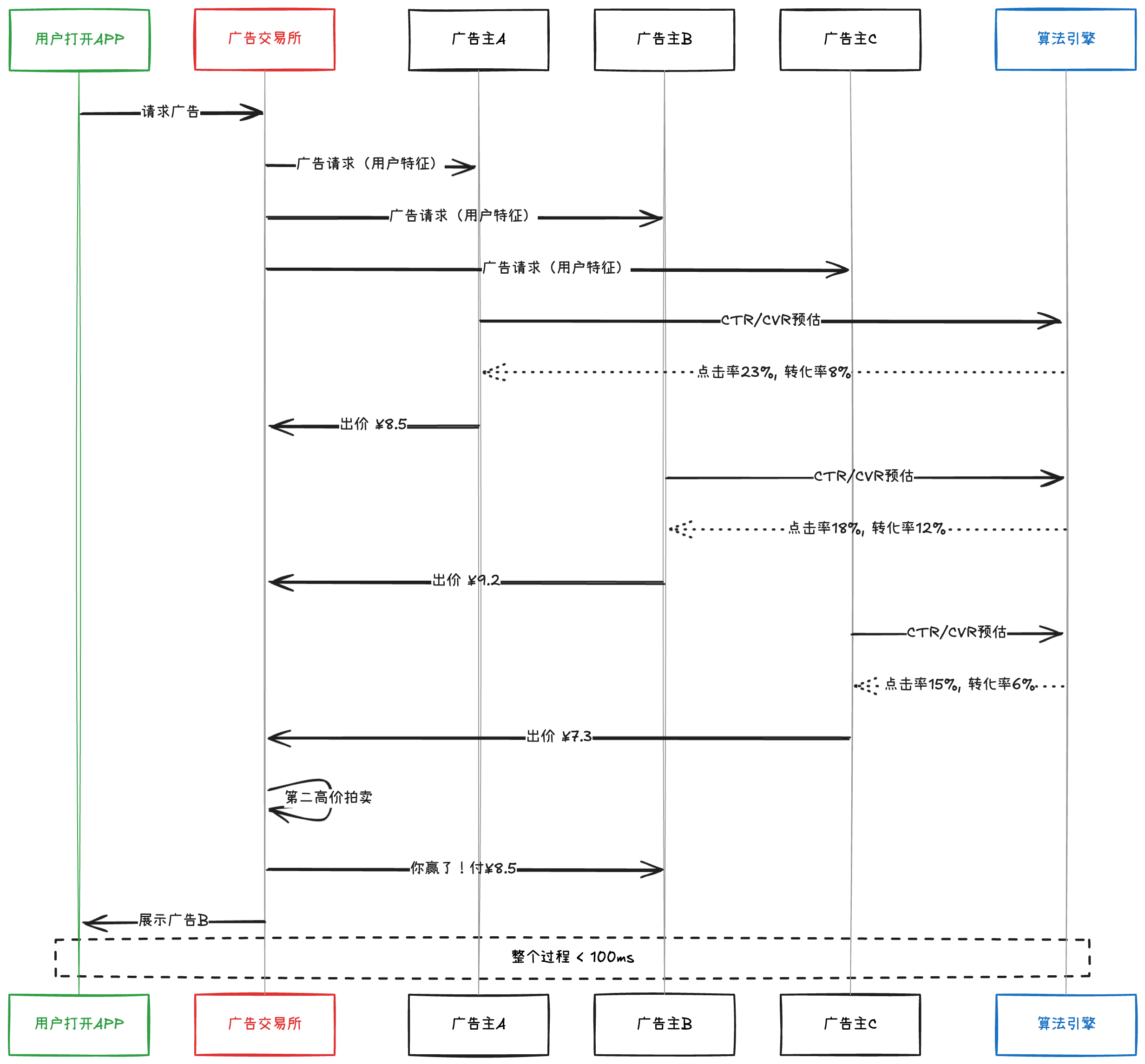
在这个过程中,算法的准确性直接决定了胜负:
- 预估过高 → 出价过高 → 成本浪费
- 预估过低 → 出价过低 → 失去流量
- 预估精准 → 出价合理 → 利润最大化
1.3 算法驱动的核心价值
1.3.1 为什么需要算法?
广告投放面临的核心挑战:
1. 海量特征维度
用户特征:
- 人口属性:年龄、性别、地域、收入...(10维)
- 行为特征:浏览历史、搜索记录、购买行为...(100+维)
- 设备信息:品牌、型号、操作系统、网络...(20维)
- 实时上下文:时间、地点、天气、场景...(30维)
广告特征:
- 创意属性:文案、图片、视频、落地页...(50维)
- 投放策略:出价类型、预算、时段、地域...(40维)
交叉特征:
- 用户×广告:10^6 - 10^9 级别人工规则完全无法处理如此高维的特征空间,只有深度学习才能胜任。
2. 实时性要求
- RTB竞价:< 100ms 响应时间
- 每秒处理:10万+ QPS
- 并发请求:多DSP同时竞价
3. 精度要求
- CTR预估误差1% → 成本增加10%
- CVR预估误差5% → ROI下降30%
- 点击率从5%提升到6% → 收入增长20%
1.3.2 算法的三重价值
① 预测价值:知道谁会点、谁会买
CTR/CVR模型通过深度学习,从海量历史数据中学习:
- 什么样的用户会对什么样的广告感兴趣
- 在什么时间、什么场景下转化概率最高
- 如何平衡点击和转化的多目标优化
② 决策价值:知道该出多少价
基于预估结果,智能出价引擎计算:
# eCPM(千次展示期望收益)计算eCPM = pCTR × pCVR × 转化价值 × 1000# 最优出价bid_price = eCPM × 利润系数 / 竞争强度③ 优化价值:持续学习、自我进化
- 在线学习:实时反馈,模型每天更新
- A/B测试:持续优化,效果提升不停
- 冷启动策略:新广告也能快速找到目标用户(目前业界逐渐淘汰)
1.4 本文的核心内容
第二章:问题定义
- CTR vs CVR:两个预估任务的本质区别
- 为什么CVR比CTR难10倍?
- 多目标建模的技术挑战与解决方案
第三章:模型架构
- 从LR到DNN:推荐模型的演进历程
- Wide & Deep、DeepFM、DCN:如何选择?
- 动态Embedding:亿级特征的终极武器
第四章:特征工程
- 稀疏特征处理:Hash、Embedding、交叉
- ID类特征 vs 统计类特征的平衡
- 特征重要性分析:找出真正有用的特征
第五章:训练与部署
- Horovod分布式训练:从1小时到10分钟
- TensorFlow Serving:百万QPS的推理服务
- 模型更新策略:如何做到平滑上线
第六章:算法与业务融合
- 预估 → 出价:算法如何驱动决策
- eCPM计算:平衡收益与成本的艺术
- 冷启动:新广告的破冰之旅
第七章:效果评估
- 离线指标:AUC、LogLoss、GAUC
- 在线指标:CTR、CVR、ROI、Revenue
- A/B测试:从实验设计到结果分析
1.5 实战案例预告
在接下来的章节中,我会结合真实的生产环境代码进行讲解:
案例1:亿级特征的动态Embedding实现
# 使用TensorFlow Recommenders Addonskv_creator = get_kv_creator(mpi_rank, mpi_size, 40960,
kv_creator = get_kv_creator(
mpi_rank,
mpi_size,
40960,
tf.dtypes.float32.size,
embedding_size,
is_serving
)
embedding_layer = de.keras.layers.HvdAllToAllEmbedding(
mpi_size=mpi_size,
embedding_size=embedding_size,
key_dtype=tf.int64,
value_dtype=tf.float32,
kv_creator=kv_creator,
short_file_name=True
)案例2:独立的CTR和CVR模型架构
# CTR模型:algorithm/dnn_ctr_v1/model.py
class CTRModel:
def __init__(self):
# DNN Embedding(轻量级,embedding_size=1)
self.sparse_emb = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=1,
name='sparse'
)
# FM Embedding(embedding_size=8)
self.sparse_emb_fm = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=8,
name='sparse_fm'
)
def call(self, features):
# 预估点击率
return ctr_prediction
# CVR模型:algorithm/dnn_cvr_v1/model.py
class CVRModel:
def __init__(self):
# 多转化目标的独立FM embedding
self.fm_targets = ['conversion_30m', 'conversion_24h', 'conversion_7d']
self.embeddingLayer_fm = {}
for target in self.fm_targets:
self.embeddingLayer_fm[target] = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=8,
name=f'sparse_fm_{target}'
)
def call(self, features):
# 预估多个转化目标
cvr_logits = {}
for target in self.fm_targets:
cvr_logits[target] = self.predict_cvr(features, target)
return cvr_logits
案例3:实时预估服务的高可用设计
// 并发预估流水线
type PredictionPipeline struct {
grouping GroupingStage // 分组
predict PredictionStage // 预测
merge MergeStage // 合并
}
func (p *PredictionPipeline) Run(ctx *RequestContext,
creativeIds []int32) (
map[int32]PredictResult, error) {
groups, _ := p.grouping.Group(ctx, creativeIds)
results, _ := p.predict.PredictGroups(ctx, groups)
return p.merge.Merge(results), nil
}
“在正确的问题上做正确的事,比在错误的问题上做正确的事要重要100倍。”
第二章:问题定义 - 预估什么,如何预估
2.1 广告预估的本质
在深入技术细节之前,我们先要搞清楚一个根本问题:我们到底在预估什么?
2.1.1 广告投放的两个关键决策
每次广告投放,我们都需要回答两个问题:
① 这个用户会点击吗? → CTR预估(Click-Through Rate)
② 这个用户会转化吗? → CVR预估(Conversion Rate)
看起来很简单,但背后隐藏着深刻的商业逻辑:
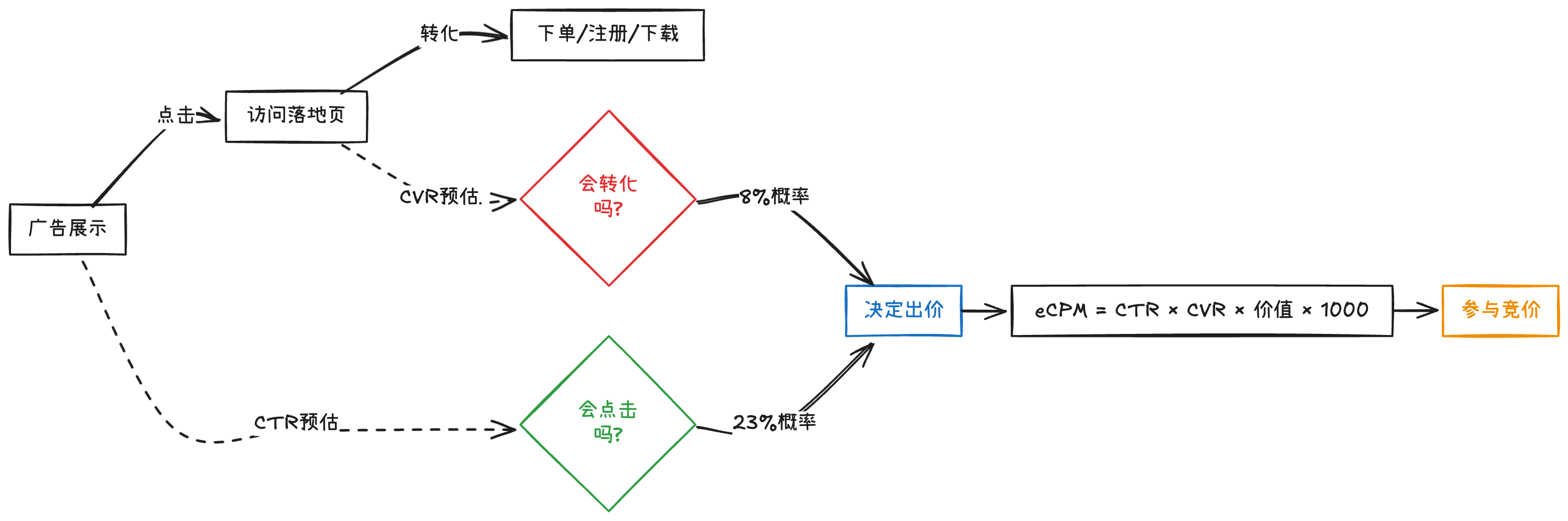
2.1.2 为什么两个预估都需要?
很多新手会问:“有了CVR预估,为什么还需要CTR?直接预估转化不就行了?”
这是一个非常好的问题。答案在于媒体计费方式的多样性:
| 计费方式 | 全称 | 计费时机 | 需要预估 | 应用场景 |
|---|---|---|---|---|
| CPM | Cost Per Mille | 按展示付费 | - | 品牌广告 |
| CPC | Cost Per Click | 按点击付费 | CVR | 效果广告 |
| CPA | Cost Per Action | 按转化付费 | - | 电商广告 |
| OCPC | Optimized CPC | 按点击付费,优化转化 | CTR + CVR | 智能投放 |
实际案例:
# CPM出价:需要同时考虑CTR和CVR
if media_bid_type == MediaBidTypeCPM:
# 计算eCPM(千次展示期望收益)
ecpm = pCTR * pCVR * conversion_value * 1000
bid_price = ecpm * profit_margin
# CPC出价:只需要考虑CVR
elif media_bid_type == MediaBidTypeCPC:
# 计算每次点击的期望价值
click_value = pCVR * conversion_value
bid_price = click_value * profit_margin
# OCPC出价:智能优化,两者都要
elif media_bid_type == MediaBidTypeOCPC:
# 先按CPC计费,但优化目标是转化
ecpm = pCTR * pCVR * conversion_value * 1000
bid_price = ecpm / pCTR # 转换成CPC出价2.2 CTR预估:点击率的业务价值
2.2.1 什么是CTR?
定义:CTR(Click-Through Rate)= 点击次数 / 曝光次数
示例:
广告展示 10,000 次
用户点击 500 次
CTR = 500 / 10,000 = 5%2.2.2 CTR预估的业务价值
① 流量价值评估
CTR直接决定了流量的价值:
同样1万次曝光:
CTR = 1% → 100次点击 → 价值较低
CTR = 5% → 500次点击 → 价值5倍提升
CTR = 10% → 1000次点击 → 价值10倍提升② CPM出价的核心依据
在CPM(按展示付费)模式下,CTR预估精度直接影响ROI:
# 真实场景计算
conversion_value = 100 # 每次转化价值100元
pCTR_predicted = 0.05 # 预估点击率5%
pCVR = 0.10 # 转化率10%
# 基于预估的出价
ecpm = pCTR_predicted * pCVR * conversion_value * 1000
= 0.05 × 0.10 × 100 × 1000
= 500元/千次展示
# 如果预估偏高(实际CTR只有3%)
actual_revenue = 0.03 × 0.10 × 100 × 1000 = 300元
loss = 500 - 300 = 200元/千次展示 # 亏损40%!③ 用户体验优化
CTR高的广告 = 用户真正感兴趣的广告 = 更好的用户体验
低CTR广告(<1%):
- 用户不感兴趣 → 降低平台体验
- 浪费广告位资源
- 媒体收益降低
高CTR广告(>5%):
- 用户主动点击 → 提升平台体验
- 充分利用广告位价值
- 媒体收益提升2.2.3 CTR预估的技术挑战
挑战1:样本不均衡
典型广告场景:
曝光样本:1,000,000 条
点击样本:50,000 条(5%)
负样本比例:95%(严重不均衡)
影响:
- 模型容易偏向预测"不点击"
- 正样本学习不充分
- 需要特殊的采样策略解决方案:
# 负采样策略
def negative_sampling(data, neg_ratio=10):
"""
对负样本进行采样
neg_ratio: 负样本/正样本 的比例
"""
pos_samples = data[data['click'] == 1]
neg_samples = data[data['click'] == 0]
# 按比例采样负样本
neg_sampled = neg_samples.sample(
n=len(pos_samples) * neg_ratio
)
# 合并正负样本
balanced_data = pd.concat([pos_samples, neg_sampled])
return balanced_data.shuffle()
挑战2:特征稀疏性
用户ID: 1,000,000+ 种可能
商品ID: 10,000,000+ 种可能
交叉特征: 10^12+ 种可能
问题:
- 大部分特征组合从未出现
- 如何为新用户/新商品预估?
- 内存无法存储所有组合解决方案(动态Embedding):
# 传统静态Embedding(内存爆炸)
embedding_layer = tf.keras.layers.Embedding(
input_dim=10000000, # 需要预先定义所有可能的ID
output_dim=128
)
# 动态Embedding(按需分配)
from tensorflow_recommenders_addons import dynamic_embedding as de
embedding_layer = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=128,
key_dtype=tf.int64,
value_dtype=tf.float32,
init_capacity=40960, # 初始容量
# 只为实际出现的ID分配内存
)
挑战3:实时性要求
RTB竞价时间预算:
总预算: 100ms
网络传输: 30ms
特征提取: 20ms
模型预估: 30ms ← 只有30ms以内 一般是10-25ms
出价决策: 10ms
其他: 10ms我们的解决方案:
// 批量预估优化
type PredictionPipeline struct {
grouping GroupingStage // 按成本类型分组
predict PredictionStage // 批量预估
merge MergeStage // 合并结果
}
// 并发处理不同成本类型
func (p *PredictionPipeline) Run(ctx *RequestContext,
creativeIds []int32) {
// 1. 分组:CPM、CPC、OCPC
groups := p.grouping.Group(ctx, creativeIds)
// 2. 并发预估
var wg sync.WaitGroup
results := make(map[int32]PredictResult)
for costType, ids := range groups {
wg.Add(1)
go func(ct CostType, cids []int32) {
defer wg.Done()
res := p.predict.Predict(ctx, ct, cids)
results[ct] = res
}(costType, ids)
}
wg.Wait()
return p.merge.Merge(results)
}
2.3 CVR预估:转化率的技术挑战
2.3.1 什么是CVR?
定义:CVR(Conversion Rate)= 转化次数 / 点击次数
示例:
用户点击 500 次
完成转化 50 次(下单/注册/下载)
CVR = 50 / 500 = 10%2.3.2 为什么CVR比CTR难10倍?
这不是夸张,而是真实的工程经验。让我逐一拆解:
难点1:样本稀疏性指数级提升
CTR场景:
曝光: 1,000,000 次
点击: 50,000 次(5%)
正样本比例:5%
CVR场景:
点击: 50,000 次
转化: 5,000 次(10%)
正样本比例:10%
但关键在于:
- CTR训练集:1,000,000 条(曝光日志)
- CVR训练集:50,000 条(点击日志)← 只有CTR的5%!
更糟糕的是:
- 新广告:可能只有100次点击
- 长尾商品:可能只有10次转化
- 如何训练?几乎不可能难点2:样本选择偏差(Sample Selection Bias)
这是CVR预估最致命的问题:
核心矛盾:
- 训练集:只有点击用户的数据(5%的人群)
- 预测集:需要对所有用户预估(100%的人群)
真实影响:
# 训练集分布
clicked_users = {
'age': [25, 28, 30, 26, 29], # 年轻人居多
'income': ['high', 'high', 'medium', 'high', 'high']
}
# 预测集分布(全体用户)
all_users = {
'age': [18, 55, 25, 60, 30, 45, 70, 28], # 年龄分布广
'income': ['low', 'medium', 'high', 'low', 'high', 'medium', 'low', 'high']
}
# 问题:模型从未见过老年人、低收入人群
# 对这些人的预估会严重失准!
业界解决方案:
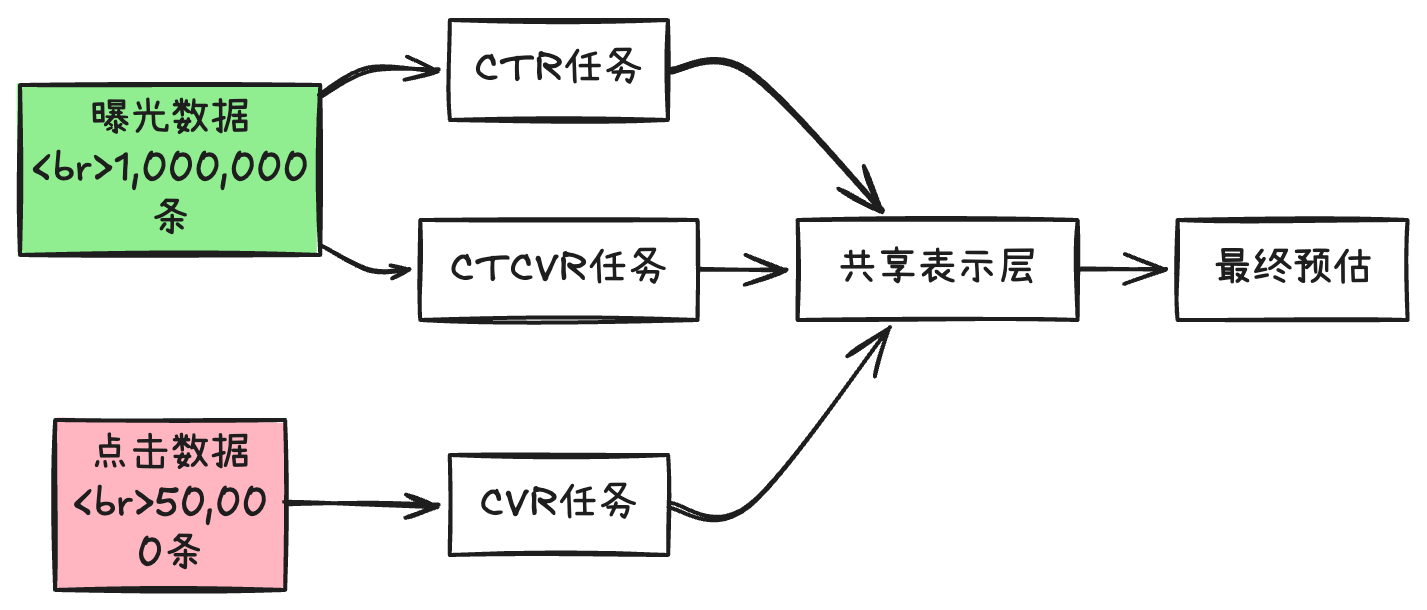
方案1:ESMM(Entire Space Multi-Task Model)
# 阿里巴巴提出的经典方案
class ESMM(tf.keras.Model):
def __init__(self):
super().__init__()
self.ctr_tower = CTRTower()
self.cvr_tower = CVRTower()
def call(self, inputs):
# CTR任务:在全部曝光样本上训练
pCTR = self.ctr_tower(inputs) # 见过所有用户
# CVR任务:在点击样本上训练
pCVR = self.cvr_tower(inputs)
# CTCVR任务:在全部曝光样本上训练
pCTCVR = pCTR * pCVR # 消除选择偏差!
return pCTR, pCVR, pCTCVR
def loss(self, y_true_click, y_true_conv):
# CTR损失:用曝光数据
loss_ctr = binary_crossentropy(y_true_click, pCTR)
# CTCVR损失:用曝光数据(关键!)
loss_ctcvr = binary_crossentropy(y_true_conv, pCTCVR)
return loss_ctr + loss_ctcvr
方案2:我们的多目标CVR建模
# 代码:algorithm/dnn_cvr_v1/model.py
# 这是CVR模型,独立训练,不依赖CTR
class SparseModel(tf.keras.Model):
def __init__(self):
# 多转化窗口的FM embedding
# 例如:conversion_30m, conversion_24h, conversion_7d
self.fm_targets = list(feature_map['labels'].keys())
self.embeddingLayer_fm = {}
for target in self.fm_targets:
# 每个转化窗口独立的FM embedding
self.embeddingLayer_fm[target] = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=8,
name=f'sparse_fm_{target}'
)
def call(self, features):
# 共享DNN embedding(所有转化窗口共享)
sparse_emb_val = self.embeddingLayer(ids)
# 每个转化窗口独立的FM embedding
sparse_emb_val_fm = {}
for target in self.fm_targets:
sparse_emb_val_fm[target] = self.embeddingLayer_fm[target](ids)
return sparse_emb_val, sparse_emb_val_fm
难点3:延迟反馈(Delayed Feedback)
CVR的另一个独特挑战:转化可能发生在点击后的任意时间
用户行为时间线:
Day 1, 10:00 → 看到广告
Day 1, 10:01 → 点击广告
Day 1, 10:05 → 浏览商品
Day 1, 10:10 → 关闭页面(未转化)
Day 2, 15:00 → 再次想起
Day 2, 15:30 → 直接搜索商品
Day 2, 15:45 → 下单!(转化了,但广告归因怎么算?)
问题:
- 如何定义转化窗口?24小时?7天?30天?
- 窗口越长,归因越准确,但训练延迟越大
- 窗口越短,训练及时,但漏掉大量转化我们的解决方案:
# 配置不同转化窗口
CONVERSION_WINDOWS = {
'immediate': 1800, # 30分钟(即时转化)
'short_term': 86400, # 24小时(短期转化)
'long_term': 604800, # 7天(长期转化)
}
# 多窗口联合建模
class MultiWindowCVR(tf.keras.Model):
def __init__(self):
self.immediate_cvr = CVRTower()
self.short_cvr = CVRTower()
self.long_cvr = CVRTower()
def call(self, inputs):
# 不同窗口的CVR预估
cvr_30m = self.immediate_cvr(inputs)
cvr_24h = self.short_cvr(inputs)
cvr_7d = self.long_cvr(inputs)
# 加权融合
final_cvr = (
0.3 * cvr_30m + # 即时转化权重高
0.5 * cvr_24h + # 短期转化最重要
0.2 * cvr_7d # 长期转化权重低
)
return final_cvr
难点4:负样本定义的模糊性
CTR很清晰:点了就是正样本,不点就是负样本。
CVR却很模糊:
用户点击后的可能情况:
1. 立即转化 ✓ → 正样本(确定)
2. 30分钟后转化 ✓ → 正样本(确定)
3. 3天后转化 ? → 正样本?(取决于窗口)
4. 浏览了但没买 ✗ → 负样本(确定)
5. 刚浏览就关闭了 ? → 负样本?(也许他准备稍后买)
6. 加购物车但未付款 ? → 正样本?负样本?
问题:如何定义"真正的负样本"?真实数据分布:
# 点击后的用户行为分析
click_samples = {
'immediate_convert': 0.05, # 5%立即转化
'delayed_convert': 0.08, # 8%延迟转化
'browsing_leave': 0.50, # 50%浏览后离开(真负样本)
'add_cart_abandon': 0.15, # 15%加购未付款(模糊样本)
'others': 0.22, # 22%其他行为(模糊样本)
}
# 模糊样本占37% 如何处理?业界实践:
# 方案1:多标签学习
labels = {
'conversion': [0, 1, 1, 0, 0], # 是否转化
'add_cart': [0, 1, 1, 1, 0], # 是否加购
'deep_browse': [0, 1, 1, 1, 1], # 是否深度浏览
}
# 方案2:软标签
def get_soft_label(user_behavior):
if user_behavior == 'convert':
return 1.0
elif user_behavior == 'add_cart':
return 0.7 # 加购给予0.7的软标签
elif user_behavior == 'deep_browse':
return 0.3 # 深度浏览给予0.3的软标签
else:
return 0.0
2.3.3 CVR预估的业务价值
尽管困难重重,CVR预估的价值却是巨大的:
① 精准出价的关键
# CPC出价场景
conversion_value = 100 # 每次转化价值100元
pCVR = 0.15 # 预估转化率15%
# 每次点击的期望价值
click_value = pCVR * conversion_value = 0.15 × 100 = 15元
# 如果CVR预估偏高(实际只有10%)
actual_value = 0.10 × 100 = 10元
loss_per_click = 15 - 10 = 5元 # 每次点击亏5元!
② ROI优化的核心
场景:电商广告投放
预算:10,000元
目标:最大化订单量
策略A(不用CVR预估):
- 随机投放
- 获得点击:1,000次
- 转化率:5%
- 订单数:50单
- ROI = 50单 × 100元 / 10,000元 = 0.5
策略B(使用CVR预估):
- 只投高CVR用户
- 获得点击:800次
- 转化率:15%
- 订单数:120单
- ROI = 120单 × 100元 / 10,000元 = 1.2
ROI提升140%!2.4 多目标建模的权衡
在实际业务中,我们往往需要同时优化CTR和CVR。这就引出了多目标学习的挑战。
2.4.1 为什么需要多目标?
单目标的局限性:
只优化CTR的问题:
- 推荐标题党广告(点击率高,但不转化)
- 用户点进去发现被骗 → 体验差
- 广告主花钱买点击,但没有转化 → ROI低
只优化CVR的问题:
- CVR训练样本太少(只有点击数据)
- 模型容易过拟合
- 无法利用大量的曝光数据多目标的优势:
2.4.2 多目标学习的经典范式
范式1:Hard Parameter Sharing
class HardSharingModel(tf.keras.Model):
""" 硬参数共享:底层共享,顶层分离 """
def __init__(self):
# 共享的底层表示
self.shared_layers = [
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
]
# CTR任务专属层
self.ctr_tower = tf.keras.layers.Dense(1, activation='sigmoid')
# CVR任务专属层
self.cvr_tower = tf.keras.layers.Dense(1, activation='sigmoid')
def call(self, inputs):
# 共享表示 shared = inputs
for layer in self.shared_layers:
shared = layer(shared)
# 各自任务 ctr = self.ctr_tower(shared)
cvr = self.cvr_tower(shared)
return ctr, cvr优点:参数量少,训练快 缺点:任务冲突时效果差
范式2:MMOE (Multi-gate Mixture-of-Experts)
class MMOEModel(tf.keras.Model):
"""
MMOE:为每个任务学习不同的专家组合
Google 2018年提出
"""
def __init__(self, num_experts=4):
# 多个专家网络
self.experts = [
tf.keras.layers.Dense(128, activation='relu')
for _ in range(num_experts)
]
# CTR任务的门控网络
self.ctr_gate = tf.keras.layers.Dense(num_experts, activation='softmax')
# CVR任务的门控网络
self.cvr_gate = tf.keras.layers.Dense(num_experts, activation='softmax')
# 任务塔
self.ctr_tower = tf.keras.layers.Dense(1, activation='sigmoid')
self.cvr_tower = tf.keras.layers.Dense(1, activation='sigmoid')
def call(self, inputs):
# 所有专家的输出
expert_outputs = [expert(inputs) for expert in self.experts]
expert_outputs = tf.stack(expert_outputs, axis=1) # [batch, num_experts, dim]
# CTR任务:门控加权
ctr_gate_weights = self.ctr_gate(inputs) # [batch, num_experts]
ctr_gate_weights = tf.expand_dims(ctr_gate_weights, axis=-1)
ctr_input = tf.reduce_sum(expert_outputs * ctr_gate_weights, axis=1)
ctr = self.ctr_tower(ctr_input)
# CVR任务:门控加权
cvr_gate_weights = self.cvr_gate(inputs)
cvr_gate_weights = tf.expand_dims(cvr_gate_weights, axis=-1)
cvr_input = tf.reduce_sum(expert_outputs * cvr_gate_weights, axis=1)
cvr = self.cvr_tower(cvr_input)
return ctr, cvr
优点:任务自适应选择专家,效果好 缺点:参数量大,训练慢
范式3:ESMM (Entire Space Multi-Task Model)
这是我们重点使用的方案,前面已经介绍过:
# 核心思想:利用 pCTCVR = pCTR × pCVR 消除选择偏差
class ESMMModel(tf.keras.Model):
def call(self, inputs):
pCTR = self.ctr_tower(inputs)
pCVR = self.cvr_tower(inputs)
pCTCVR = pCTR * pCVR # 隐式建模
return pCTR, pCVR, pCTCVR
def loss(self, y_click, y_conversion):
# 关键:两个损失都在全部曝光样本上计算
loss_ctr = binary_crossentropy(y_click, pCTR)
loss_ctcvr = binary_crossentropy(y_conversion, pCTCVR)
return loss_ctr + loss_ctcvr2.4.3 我们的多目标实践
在实际项目中,我们采用了改进的多目标CVR建模:
# 1. CTR模型:algorithm/dnn_ctr_v1/
"""
- 目标:预估点击率
- 数据:全部曝光样本(样本量大)
- 架构:轻量级DNN(embedding_size=1)+ FM(embedding_size=8)
"""
# 2. CVR模型:algorithm/dnn_cvr_v1/
"""
- 目标:预估多个转化窗口的CVR
- 数据:点击样本(样本量小)
- 架构:多目标FM,每个转化窗口独立embedding
"""
# CVR模型的多转化窗口建模
class DenseModel(tf.keras.Model):
def call(self, sparse_emb, sparse_emb_fm_dict):
"""
多转化窗口的CVR建模
注意:这是CVR模型的多目标,不是CTR+CVR联合建模
"""
# DNN部分:共享表示
logit = tf.reduce_sum(sparse_emb, axis=1, keepdims=True)
# FM部分:每个转化窗口独立建模
fm_logits = {}
for target, fm_emb in sparse_emb_fm_dict.items():
# target = 'conversion_30m', 'conversion_24h', 'conversion_7d'
# FM二阶交叉
square_of_sum = tf.square(tf.reduce_sum(fm_emb, axis=1))
sum_of_square = tf.reduce_sum(tf.square(fm_emb), axis=1)
fm_cross = 0.5 * (square_of_sum - sum_of_square)
fm_logits[target] = logit + tf.reduce_sum(fm_cross, axis=1, keepdims=True)
return fm_logits设计思路:
- 共享DNN表示:学习通用的用户-广告匹配模式
- 独立FM交叉:为每个转化目标学习特定的特征交叉
- 多窗口转化:同时建模即时转化、短期转化、长期转化
实际效果:
对比实验(某电商广告主):
单目标CTR模型:
- CTR预估AUC: 0.78
- CVR预估AUC: -(无法预估)
- 线上ROI: 1.2
单目标CVR模型:
- CTR预估AUC: -(无法预估)
- CVR预估AUC: 0.65(样本少,过拟合)
- 线上ROI: 0.9
多目标模型(我们的方案):
- CTR预估AUC: 0.79
- CVR预估AUC: 0.72(提升明显)
- 线上ROI: 1.8(提升50%)关键要点
1. CTR vs CVR的本质区别
- CTR:曝光→点击,样本充足,预估相对容易
- CVR:点击→转化,样本稀疏,存在选择偏差
2. CTR预估的三大挑战
- 样本不均衡(95%负样本)
- 特征稀疏性(亿级特征)
- 实时性要求(30ms预估)
3. CVR预估的四大难点
- 样本稀疏性(只有CTR的5%数据)
- 样本选择偏差(训练集≠预测集)
- 延迟反馈(转化发生在未来)
- 负样本定义模糊(37%的样本难以判断)
4. 多目标建模的必要性
- 利用曝光数据,解决CVR样本少的问题
- 消除选择偏差,提升预估准确性
- 同时优化点击和转化,最大化ROI
工程实践要点
# 记住这些关键公式:
# CTR预估
pCTR = P(click | impression)
# CVR预估(存在偏差)
pCVR_biased = P(conversion | click) # 只在点击用户上训练
# CTCVR预估(消除偏差)
pCTCVR = P(click AND conversion | impression) = pCTR × pCVR
# eCPM计算
eCPM = pCTR × pCVR × conversion_value × 1000
第三章:模型架构设计
3.1 推荐模型的演进史
在深入我们的架构设计之前,让我们先回顾一下推荐系统模型的演进历程。理解历史,才能更好地把握未来。
3.1.1 第一代:线性模型时代(2010年前)
LR (Logistic Regression) - 工业界的基石
# 最简单的LR模型
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def lr_predict(features, weights):
"""
LR预测
features: [user_age, user_gender, ad_category, ...]
weights: 对应的权重
"""
score = np.dot(features, weights)
return sigmoid(score)
# 示例
features = [25, 1, 0, 1, 0, ...] # 用户25岁,男性,广告是游戏类...
weights = [0.01, 0.5, -0.3, 0.8, ...]
pCTR = lr_predict(features, weights) # 预估点击率
优点:
- 简单、可解释性强
- 训练快速,易于上线
- Facebook、Google早期都在用
致命缺陷:
# LR无法学习特征交叉
# 比如:年轻男性 × 游戏广告 → 高CTR
# LR必须手工构造这个特征:
features = [
age,
gender,
ad_category,
age * gender, # 手工特征1
gender * ad_category, # 手工特征2
age * gender * ad_category # 手工特征3
# ... 组合爆炸!
]
工程师的噩梦:
特征维度:1000
二阶交叉:1000 × 1000 = 1,000,000
三阶交叉:1000^3 = 1,000,000,000
根本无法枚举3.1.2 第二代:因子分解机时代(2010-2016)
FM (Factorization Machine) - 特征交叉的突破
2010年,Steffen Rendle提出FM,优雅地解决了特征交叉问题:
class FactorizationMachine:
"""
FM模型:自动学习二阶特征交叉
核心思想:
y = w0 + Σ(wi·xi) + Σ Σ(<vi, vj>·xi·xj)
↑ ↑ ↑
偏置 一阶项 二阶交叉项
"""
def __init__(self, feature_dim, embedding_dim=8):
self.w0 = 0.0 # 全局偏置
self.w = np.zeros(feature_dim) # 一阶权重
self.V = np.random.randn(feature_dim, embedding_dim) # embedding矩阵
def predict(self, x):
# 一阶部分
linear = self.w0 + np.dot(self.w, x)
# 二阶交叉部分(优化后的计算)
# 原始:Σ Σ(<vi,vj>·xi·xj) = O(n^2·k)
# 优化:(Σvi·xi)^2 - Σ(vi·xi)^2 = O(n·k)
square_of_sum = np.square(np.dot(self.V.T, x)) # (Σvi·xi)^2
sum_of_square = np.dot(np.square(self.V.T), np.square(x)) # Σ(vi·xi)^2
interaction = 0.5 * np.sum(square_of_sum - sum_of_square)
return sigmoid(linear + interaction)
FM的魔法:
不需要见过特征组合,也能预估
训练集:
- 用户A(25岁,男) × 广告1(游戏) → 点击
- 用户B(30岁,男) × 广告2(运动) → 点击
预测集:
- 用户C(25岁,男) × 广告2(运动) → ?
LR:从未见过这个组合,预估失败
FM:通过embedding内积,推理出:
年轻男性 ≈ 用户A
运动广告 ≈ 广告2
→ 有一定点击概率
实际效果:
某电商平台实验:
LR: AUC = 0.72
FM: AUC = 0.76 ← 提升4个点!
但在实际部署中发现:
- FM只能学二阶交叉
- 高阶交叉(三阶、四阶)无法建模
- 对于复杂的用户行为模式,表达能力不足
3.1.3 第三代:深度学习时代(2016-至今)
Wide & Deep (Google, 2016) - 深度学习的工业化
class WideAndDeep(tf.keras.Model):
""" Wide & Deep:结合记忆与泛化 Wide部分:线性模型,记忆规则 Deep部分:DNN,学习泛化模式 """ def __init__(self):
# Wide部分:手工交叉特征 self.wide = tf.keras.layers.Dense(1)
# Deep部分:DNN自动学习 self.deep = tf.keras.Sequential([
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(1)
])
def call(self, wide_features, deep_features):
wide_out = self.wide(wide_features)
deep_out = self.deep(deep_features)
# 联合训练 return tf.nn.sigmoid(wide_out + deep_out)Google的实践经验:
Google Play应用推荐:
Wide & Deep模型相比DNN alone:
- 应用下载量提升 +3.9%
- 每日活跃用户增加 +2.1%
关键insight:
Wide部分记忆特殊规则(如:用户安装过的app类别)
Deep部分学习泛化模式(如:用户的兴趣迁移)DeepFM (Huawei, 2017) - FM与DNN的完美结合
class DeepFM(tf.keras.Model):
"""
DeepFM:用FM代替Wide & Deep的Wide部分
优势:
1. 不需要手工特征工程
2. FM自动学习低阶交叉
3. DNN学习高阶交叉
"""
def __init__(self, feature_dim, embedding_dim=8):
# FM部分
self.fm_first_order = tf.keras.layers.Dense(1) # 一阶
self.fm_embeddings = tf.keras.layers.Embedding(
feature_dim, embedding_dim
)
# Deep部分
self.dnn = tf.keras.Sequential([
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(1)
])
def call(self, features):
# FM一阶
fm_first = self.fm_first_order(features)
# FM二阶(特征交叉)
emb = self.fm_embeddings(features) # [batch, field, emb_dim]
square_of_sum = tf.square(tf.reduce_sum(emb, axis=1))
sum_of_square = tf.reduce_sum(tf.square(emb), axis=1)
fm_second = 0.5 * tf.reduce_sum(square_of_sum - sum_of_square, axis=1, keepdims=True)
# DNN(高阶交叉)
dnn_input = tf.reshape(emb, [-1, field_num * embedding_dim])
dnn_out = self.dnn(dnn_input)
# 联合输出
return tf.nn.sigmoid(fm_first + fm_second + dnn_out)华为的实验结果:
Criteo数据集(在线广告点击预测):
LR: AUC = 0.7623
FM: AUC = 0.7892
Wide&Deep: AUC = 0.8021
DeepFM: AUC = 0.8057 ← 业界新标杆
关键优势:
- 端到端训练,无需特征工程
- FM层和DNN层共享embedding
- 参数量更少,训练更快DCN (Google, 2017) - 显式高阶交叉
class DCN(tf.keras.Model):
"""
Deep & Cross Network (DCN)
Cross Network:显式学习任意阶的特征交叉
Deep Network:隐式学习复杂模式
"""
def __init__(self, cross_layers=3):
# Cross部分
self.cross_layers = [
CrossLayer() for _ in range(cross_layers)
]
# Deep部分
self.deep = tf.keras.Sequential([
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
])
self.final = tf.keras.layers.Dense(1)
def call(self, x):
# Cross部分(显式交叉)
cross_out = x
for cross_layer in self.cross_layers:
cross_out = cross_layer(cross_out, x)
# Deep部分(隐式学习)
deep_out = self.deep(x)
# 拼接
combined = tf.concat([cross_out, deep_out], axis=-1)
return tf.nn.sigmoid(self.final(combined))
class CrossLayer(tf.keras.layers.Layer):
"""
交叉层:xl+1 = x0 · xl^T · w + b + xl
核心思想:
- x0是输入,xl是上一层输出
- 通过x0 · xl^T实现高阶交叉
- 每层增加一阶
"""
def __init__(self):
super().__init__()
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], 1),
initializer='glorot_uniform',
trainable=True
)
self.b = self.add_weight(
shape=(input_shape[-1],),
initializer='zeros',
trainable=True
)
def call(self, xl, x0):
# xl: 上一层输出
# x0: 输入
xl_w = tf.matmul(xl, self.w) # [batch, 1]
cross = x0 * xl_w # [batch, dim] * [batch, 1] = [batch, dim]
return cross + self.b + xlDCN的创新点:
特征交叉的阶数:
1层Cross: 2阶交叉
2层Cross: 3阶交叉
3层Cross: 4阶交叉
...
相比DNN的隐式交叉,DCN的交叉是显式的、可解释的
Google实验:
Criteo数据集
DeepFM: AUC = 0.8057
DCN: AUC = 0.8064 ← 小幅提升,但参数量减少60%!3.1.4 第四代:超大规模时代(2020-至今)
DLRM (Facebook, 2019) - 万亿参数的工业实践 https://arxiv.org/pdf/1906.00091
class DLRM(tf.keras.Model):
"""
Deep Learning Recommendation Model (DLRM)
Facebook的超大规模推荐模型
- 支持万亿级参数
- 针对稀疏特征优化
"""
def __init__(self, sparse_features, dense_features):
# 密集特征的MLP
self.bottom_mlp = tf.keras.Sequential([
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
])
# 稀疏特征的Embedding(支持动态增长)
self.embeddings = [
tf.keras.layers.Embedding(vocab_size, 128)
for vocab_size in sparse_features
]
# 特征交互层(点积)
self.interaction = DotInteraction()
# 顶层MLP
self.top_mlp = tf.keras.Sequential([
tf.keras.layers.Dense(1024, activation='relu'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(1)
])
def call(self, dense_x, sparse_x):
# 密集特征处理
dense_emb = self.bottom_mlp(dense_x)
# 稀疏特征Embedding
sparse_embs = [
emb(sparse_x[:, i])
for i, emb in enumerate(self.embeddings)
]
# 所有embedding拼接
all_embs = [dense_emb] + sparse_embs
# 特征交互(两两点积)
interactions = self.interaction(all_embs)
# 顶层预测
return tf.nn.sigmoid(self.top_mlp(interactions))
class DotInteraction(tf.keras.layers.Layer):
"""点积交互层"""
def call(self, embeddings):
# embeddings: list of [batch, emb_dim]
batch_size = tf.shape(embeddings[0])[0]
num_features = len(embeddings)
# 两两点积
interactions = []
for i in range(num_features):
for j in range(i + 1, num_features):
dot = tf.reduce_sum(
embeddings[i] * embeddings[j],
axis=1,
keepdims=True
)
interactions.append(dot)
# 拼接所有交互
return tf.concat(interactions, axis=-1)
Facebook的生产经验:
DLRM在Facebook的应用:
- 模型参数:12 trillion (12万亿)
- 训练数据:每天 1PB+
- 推理QPS:每秒 百万级
关键优化:
1. 模型并行:Embedding表分布在多台机器
2. 数据并行:训练数据分片处理
3. 混合精度:FP16训练,加速2倍
4. 梯度压缩:减少通信开销3.2 DNN模型的选择与演进
基于业界实践和我们的实际需求,让我们看看如何选择合适的模型。
3.2.1 模型选型的权衡矩阵
| 模型 | 效果 | 训练速度 | 参数量 | 工程复杂度 | 适用场景 |
|---|---|---|---|---|---|
| LR | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ | ⭐ | 快速baseline |
| FM | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | 数据量小 |
| Wide&Deep | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | 需要记忆+泛化 |
| DeepFM | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | 推荐场景首选 |
| DCN | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | 高阶交叉重要 |
| DLRM | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 超大规模 |
3.2.2 我们的模型演进路径
基于实际业务需求和数据特点,我们的模型经历了三个阶段:
阶段1:轻量级DNN + FM(当前生产环境)
为什么选择DNN + FM组合?
# 代码位置:algorithm/dnn_ctr_v1/model.py
class SparseModel(tf.keras.Model):
"""
稀疏特征处理模型
设计理念:
1. 数据量相对较少(每天几百万样本)
2. 特征维度高(亿级ID特征)
3. 需要快速迭代
"""
def __init__(self, mpi_rank=0, mpi_size=1, is_training=True):
super(SparseModel, self).__init__()
# DNN Embedding:学习深层语义
self.embeddingLayer = de.keras.layers.HvdAllToAllEmbedding(
mpi_size=mpi_size,
embedding_size=model_config.embedding_size, # 配置为1或8
key_dtype=tf.int64,
value_dtype=tf.float32,
name='sparse',
init_capacity=40960,
)
# FM Embedding:学习二阶交叉
self.embeddingLayer_fm = de.keras.layers.HvdAllToAllEmbedding(
mpi_size=mpi_size,
embedding_size=8, # FM固定为8维
key_dtype=tf.int64,
value_dtype=tf.float32,
name='sparse_fm',
init_capacity=40960,
)
def call(self, features):
ids = features["keys"]
# DNN特征
sparse_emb_val = self.embeddingLayer(ids)
# FM特征
sparse_emb_val_fm = self.embeddingLayer_fm(ids)
return sparse_emb_val, sparse_emb_val_fm为什么FM embedding只有8维?
# 实验对比
embedding_sizes = [1, 4, 8, 16, 32]
results = {}
for emb_size in embedding_sizes:
model = train_model(embedding_size=emb_size)
results[emb_size] = {
'auc': evaluate_auc(model),
'training_time': measure_time(model),
'memory': measure_memory(model)
}实验结果表格
| emb_size | AUC | 训练时间 | 内存占用 | 说明 |
|---|---|---|---|---|
| 1 | 0.750 | 10min | 2GB | - |
| 4 | 0.768 | 15min | 4GB | - |
| 8 | 0.772 | 20min | 6GB | 最优平衡点 |
| 16 | 0.773 | 35min | 10GB | 边际收益递减 |
| 32 | 0.774 | 60min | 18GB | 性价比低 |
核心设计原则:
1. 轻量级DNN(embedding_size=1):
- 只学习一阶特征权重
- 参数量小,训练快
- 避免过拟合
2. FM学习交叉(embedding_size=8):
- 专注二阶特征交叉
- 8维足够表达交叉模式
- 计算效率高
3. 两者分离的优势:
- 各司其职,互不干扰
- 方便调试和优化
- 支持灵活的特征组合阶段2:多目标CVR建模(已上线)
# 代码位置:algorithm/dnn_cvr_v1/model.py
class SparseModel(tf.keras.Model):
"""
多目标CVR模型
创新点:
- 每个转化目标独立的FM embedding
- 共享DNN表示
- 支持多窗口转化建模
"""
def __init__(self):
super().__init__()
# 共享的DNN embedding
self.embeddingLayer = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=model_config.embedding_size,
name='sparse'
)
# 多目标FM embedding
self.fm_targets = list(feature_map['labels'].keys())
self.embeddingLayer_fm = {}
for target in self.fm_targets:
self.embeddingLayer_fm[target] = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=8,
name=f'sparse_fm_{target}'
)
def call(self, features):
ids = features["keys"]
# 共享表示
sparse_emb_val = self.embeddingLayer(ids)
# 每个目标的FM特征
sparse_emb_val_fm = {}
for target in self.fm_targets:
sparse_emb_val_fm[target] = self.embeddingLayer_fm[target](ids)
return sparse_emb_val, sparse_emb_val_fm多目标设计的价值:
单目标 CVR
-
特点:仅预估一个转化窗口(如 24 小时)
-
局限性:
样本利用率低
- 无法区分即时转化与延迟转化
- 预估准确性有限
多目标 CVR
- 特点:同时预估多个转化窗口
immediate_cvr:30 分钟内转化short_cvr:24 小时内转化long_cvr:7 天内转化
- 优势:
- 充分利用样本(覆盖不同窗口的正样本)
- 学习转化的时间模式(捕捉即时 / 延迟转化规律)
- 支持个性化窗口预估(适配不同业务场景需求)
实际效果对比
results = {
'single_target': {
'cvr_auc': 0.68,
'training_samples': 50000,
'online_roi': 1.2
},
'multi_target': {
'immediate_auc': 0.72,
'short_auc': 0.71,
'long_auc': 0.69,
'training_samples': 50000, # 相同样本量
'online_roi': 1.6 # ROI提升33%
}
}| 指标 | 单目标 CVR | 多目标 CVR | 差异分析 |
|---|---|---|---|
| 核心 AUC | 0.68 | 即时:0.72 / 短期:0.71 / 长期:0.69 | 多目标各窗口 AUC 均更高 |
| 训练样本量 | 50000 | 50000 | 样本量相同,多目标利用率更高 |
| 在线 ROI(投入产出比) | 1.2 | 1.6 | 多目标提升 33% |
3.3 动态Embedding的技术优势
在亿级特征场景下,动态Embedding是必选项,不是可选项。
3.3.1 为什么需要动态Embedding?
问题:静态Embedding的内存爆炸
# 静态Embedding(传统方案)
static_embedding = tf.keras.layers.Embedding(
input_dim=100000000, # 假设总ID数量(1亿个)
output_dim=128, # Embedding维度(128维)
)
# 内存占用计算
memory_usage = (
100000000 # ID数量
* 128 # Embedding维度
* 4 # 数据类型为float32,每个元素占4字节
) / (1024 **3) # 转换为GB单位
print(f"内存占用: {memory_usage:.2f} GB")
# 输出: 内存占用: 47.68 GB
并且核心问题在于:99% 的 ID 实际从未出现(冷 ID),但仍需为其预分配内存,导致存储效率极低,扩展性也差,词汇表(vocabulary)固定,无法处理新出现的 ID。解决:动态Embedding按需分配
# 动态Embedding
from tensorflow_recommenders_addons import dynamic_embedding as de
# 动态Embedding层定义(核心优化点:按需分配内存)
dynamic_embedding = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=128, # Embedding维度(128维)
key_dtype=tf.int64, # ID数据类型
value_dtype=tf.float32, # Embedding值数据类型
init_capacity=40960, # 初始容量(4万,可动态扩容)
# 核心特性:仅为实际出现的ID分配内存,冷ID/新ID不占用初始资源
)
# 实际内存占用计算
actual_unique_ids = 5000000 # 实际活跃ID数量:500万(远少于总ID量)
actual_memory = (
actual_unique_ids # 实际活跃ID数
* 128 # Embedding维度
* 4 # float32类型,每个元素占4字节
) / (1024 **3) # 转换为GB单位
print(f"实际内存占用: {actual_memory:.2f} GB")
# 输出: 实际内存占用: 2.38 GB
# 内存节省对比
static_memory = 47.68 # 静态Embedding内存(来自传统方案)
memory_saved = static_memory - actual_memory
memory_saved_ratio = (memory_saved / static_memory) * 100
print(f"内存节省: {memory_saved:.2f} GB(节省比例:{memory_saved_ratio:.1f}%)")
# 输出: 内存节省: 45.30 GB(节省比例:95.0%)3.3.2 动态Embedding的核心原理
# TensorFlow Recommenders Addons (TFRA) 动态Embedding实现原理
class DynamicEmbedding:
"""
动态Embedding的核心逻辑
核心特性:
- 基于哈希表存储,仅为实际出现的ID分配内存
- 自动处理新ID(分配默认值)
- 仅更新实际参与计算的ID梯度
"""
def __init__(self, embedding_size, init_capacity):
# 使用哈希表存储embedding(核心数据结构)
self.table = HashTable(
key_dtype=tf.int64,
value_dtype=tf.float32,
default_value=tf.zeros(embedding_size) # 新ID默认返回全零向量
)
self.embedding_size = embedding_size # 嵌入维度
def lookup(self, ids):
"""查找ID对应的embedding(支持自动处理新ID)"""
# 1. 从哈希表中查询已有ID的embedding
embeddings = self.table.lookup(ids)
# 2. 自动处理新ID:未在表中的ID会返回default_value(全零向量)
# 3. 后续可通过update方法为新ID更新实际值
return embeddings
def update(self, ids, gradients):
"""更新embedding(仅针对实际出现的ID)"""
# 仅对参与前向计算的ID更新梯度,避免无效计算
self.table.update(ids, gradients)
# 分布式动态Embedding实现(基于Horovod All-to-All通信)
class HvdAllToAllEmbedding:
"""
分布式场景下的动态Embedding
核心原理:
1. 按ID哈希值分片到多个GPU/机器(负载均衡)
2. 通过All-to-All通信高效收集跨节点embedding
3. 梯度反向传播时,同样通过All-to-All回传对应分片
"""
def __init__(self, mpi_size, embedding_size):
self.mpi_size = mpi_size # 分布式节点数量
# ID空间分片:每个节点负责一段哈希范围的ID(避免重复存储)
self.shard_size = (2 **63) // mpi_size
# 本地节点持有的embedding子表(仅存储分配给当前节点的ID)
self.local_table = HashTable(
key_dtype=tf.int64,
value_dtype=tf.float32,
default_value=tf.zeros(embedding_size)
)
def lookup(self, ids):
# 1. 计算每个ID所属的分片(基于哈希取模)
shard_ids = ids % self.mpi_size
# 2. 按分片ID分组(相同分片的ID归为一组)
grouped_ids = group_by_shard(ids, shard_ids)
# 3. All-to-All通信:跨节点传递ID组
# 每个节点向目标分片所在节点发送ID,请求对应的embedding
local_embedding_ids = hvd.alltoall(grouped_ids)
# 4. 从本地子表查询embedding
local_embeddings = self.local_table.lookup(local_embedding_ids)
# 5. All-to-All回传:将本地查询结果汇总返回给请求节点
return hvd.alltoall(local_embeddings)3.3.3 我们的动态Embedding实践
def get_kv_creator(mpi_rank, mpi_size, init_capacity,
value_bytes, embedding_size, is_serving):
"""
创建KV存储(用于动态Embedding的底层存储创建器)
参数说明:
- mpi_rank: 当前worker的rank(分布式节点标识)
- mpi_size: 总worker数(分布式节点总数)
- init_capacity: 初始容量(KV表的初始存储空间大小)
- value_bytes: 每个value的字节数(根据数据类型计算)
- embedding_size: embedding维度(特征向量长度)
- is_serving: 是否为服务模式(True为线上服务,False为离线训练)
"""
if is_serving:
# 服务模式:使用Redis/RocksDB等持久化存储(支持高可用和持久化)
return de.RedisTableCreator(...)
else:
# 训练模式:使用内存哈希表(追求训练效率,配合文件存储持久化参数)
return de.HkvHashTableCreator(
init_capacity=init_capacity,
saver=de.FileSystemSaver(
proc_size=mpi_size,
proc_rank=mpi_rank,
)
)
# 使用示例:创建稀疏特征的KV存储创建器及对应的Embedding层
kv_creator_sparse = get_kv_creator(
mpi_rank=mpi_rank,
mpi_size=mpi_size,
init_capacity=40960, # 初始容量4万(可动态扩容)
value_bytes=tf.dtypes.float32.size, # float32类型占4字节
embedding_size=model_config.embedding_size,
is_serving=is_serving
)
# 初始化分布式动态Embedding层
embeddingLayer = de.keras.layers.HvdAllToAllEmbedding(
mpi_size=mpi_size,
embedding_size=model_config.embedding_size,
key_dtype=tf.int64, # ID数据类型(int64支持大整数ID)
value_dtype=tf.float32, # Embedding值数据类型
initializer=tf.keras.initializers.RandomUniform(-1, 1), # 初始化方式
name='sparse', # 层名称(用于区分不同特征组)
init_capacity=40960, # 初始容量(与KV创建器保持一致)
kv_creator=kv_creator_sparse, # 绑定KV存储创建器
short_file_name=True, # 存储文件使用短名称(简化路径)
)关键特性:
- 按需分配:只为出现的ID分配内存
- 分布式存储:支持多机多卡训练
- 持久化支持:训练完可保存到Redis/RocksDB
- 新ID友好:新ID自动分配,无需重新训练
3.4 FM交叉特征的妙用
虽然我们因为数据量限制主要使用了轻量级方案,但FM的特征交叉能力不容小觑。
3.4.1 FM的数学原理(深度解析)
FM 模型核心数学表达式
FM 模型通过一阶项捕捉特征独立贡献,二阶项捕捉特征间交互关系
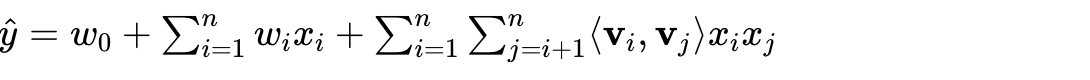
优化计算((O(nk))):数学变形降复杂度

import numpy as np
def fm_interaction_optimized(embeddings: np.ndarray, x: np.ndarray) -> float:
"""
FM二阶交互项的优化计算(O(n · k)复杂度)
核心原理:通过平方差公式变形,消去双重循环,将复杂度从O(n²k)降至O(nk)
公式:0.5 * [ (sum(v_i x_i))² - sum( (v_i x_i)² ) ]
参数:
embeddings: 特征的Embedding矩阵,shape=(n, k),每行对应一个特征的k维向量
x: 特征取值向量,shape=(n,),每个元素对应一个特征的取值(x_i)
返回:
float: 二阶交互项的总和
"""
# 1. 计算 sum(v_i x_i):每个特征的Embedding与x_i相乘后,按维度求和(shape=(k,))
sum_emb = np.sum(embeddings * x.reshape(-1, 1), axis=0) # x.reshape(-1,1)实现广播,匹配Embedding的k维
# 2. 计算 (sum(v_i x_i))²:对sum_emb的每个维度平方后求和(标量)
square_of_sum = np.sum(sum_emb ** 2)
# 3. 计算 sum( (v_i x_i)² ):每个特征的(v_i x_i)平方后按维度求和,再累加所有特征(标量)
sum_of_square = np.sum(
np.sum( (embeddings * x.reshape(-1, 1)) ** 2, axis=1 ) # 每个特征的平方和(shape=(n,))
)
# 4. 代入优化公式,得到二阶交互项总和
interaction_sum = 0.5 * (square_of_sum - sum_of_square)
return interaction_sum数学证明:
3.4.2 我们的FM实现
class DenseModel(tf.keras.Model):
"""
DNN与FM结合的CTR预估模型输出层
功能:
- 接收稀疏特征的DNN嵌入和FM嵌入
- 融合一阶特征(DNN简单加和)与二阶交叉特征(FM)
- 输出最终的点击率(CTR)预测概率
"""
def __init__(self):
super(DenseModel, self).__init__()
# 全局偏置项(初始化值为1.0)
self.bias = tf.Variable(
initial_value=1.0,
dtype=tf.float32,
name="bias_var" # 变量命名,便于训练时追踪
)
@tf.function # 转换为TensorFlow计算图,加速执行
def call(self, sparse_emb, sparse_emb_fm):
"""
前向传播:融合DNN与FM特征,输出预测概率
参数:
sparse_emb: DNN部分的稀疏特征嵌入
shape: [batch_size, num_features, emb_dim]
说明:num_features为特征数量,emb_dim为DNN嵌入维度(如1/8/16)
sparse_emb_fm: FM部分的稀疏特征嵌入
shape: [batch_size, num_features, 8]
说明:固定8维,用于计算二阶交叉特征
返回:
prob: 点击率预测概率
shape: [batch_size, 1]
说明:经过sigmoid激活,取值范围[0,1]
"""
# --------------------------
# 1. DNN部分(一阶特征贡献)
# --------------------------
# 对所有特征的DNN嵌入按特征维度求和(聚合一阶特征信息)
# shape变化:[batch, num_features, emb_dim] → [batch, 1, emb_dim] → 保留emb_dim用于后续广播
dnn_logit = tf.reduce_sum(sparse_emb, axis=1, keepdims=True)
# --------------------------
# 2. FM部分(二阶交叉特征)
# --------------------------
# 2.1 计算 (Σv_i)^2:所有特征的FM嵌入按特征维度求和后平方
# shape变化:[batch, num_features, 8] → [batch, 8] → [batch, 8]
square_of_sum = tf.square(
tf.reduce_sum(sparse_emb_fm, axis=1) # 先求和:[batch, 8]
)
# 2.2 计算 Σ(v_i^2):所有特征的FM嵌入先平方再按特征维度求和
# shape变化:[batch, num_features, 8] → [batch, num_features, 8] → [batch, 8]
sum_of_square = tf.reduce_sum(
tf.square(sparse_emb_fm), # 先平方:[batch, num_features, 8]
axis=1 # 再求和:[batch, 8]
)
# 2.3 计算FM二阶交叉项:0.5 * [(Σv_i)^2 - Σ(v_i^2)]
# shape: [batch, 8]
fm_cross = 0.5 * (square_of_sum - sum_of_square)
# 2.4 聚合FM交叉项(将8维特征求和为标量)
# shape变化:[batch, 8] → [batch, 1]
fm_logit = tf.reduce_sum(fm_cross, axis=1, keepdims=True)
# --------------------------
# 3. 融合所有部分并输出概率
# --------------------------
# 合并DNN一阶项与FM二阶项
logit = dnn_logit + fm_logit
# 加上全局偏置
logit = logit + self.bias
# 通过sigmoid激活得到概率(映射到[0,1])
prob = tf.nn.sigmoid(logit)
return prob为什么DNN只用sum,不用全连接层?
这是一个很好的问题,答案在于数据量和过拟合的权衡:
方案 A:轻量级 DNN 方案
def lightweight_dnn(sparse_emb):
"""
轻量级DNN:仅保留一阶特征聚合,配合全局偏置
输入:sparse_emb - 稀疏特征嵌入,shape=[batch, num_features, emb_dim](emb_dim=1)
输出:一阶特征 logit,shape=[batch, 1]
"""
# 按特征维度聚合一阶信息,加全局偏置(提前定义的tf.Variable)
return tf.reduce_sum(sparse_emb, axis=1, keepdims=True) + bias
方案 B:标准 DNN 方案
def standard_dnn(sparse_emb):
"""
标准深度DNN:3层全连接网络,建模复杂非线性关系
输入:sparse_emb - 稀疏特征嵌入,shape=[batch, num_features, emb_dim](emb_dim=128)
输出:复杂特征 logit,shape=[batch, 1]
"""
# 适配Dense层输入:将3D tensor [batch, num_features, emb_dim] 展平为2D [batch, num_features*emb_dim]
x = tf.keras.layers.Flatten()(sparse_emb)
# 3层全连接网络(ReLU激活引入非线性)
x = tf.keras.layers.Dense(512, activation='relu')(x) # 第一层:512个神经元
x = tf.keras.layers.Dense(256, activation='relu')(x) # 第二层:256个神经元
x = tf.keras.layers.Dense(1)(x) # 输出层:1个logit值
return x
最终选择:轻量级 DNN + FM
选型核心理由
基于业务场景(每天几百万样本,数据量中等),选择 “轻量级 DNN + FM” 的组合,而非 “标准 DNN + FM”,核心逻辑如下:
数据量适配:避免过拟合,平衡效果与泛化每天几百万样本属于 “中等数据量”,不足以支撑标准 DNN 的复杂参数(19 万 + 参数易过拟合);而轻量级 DNN(仅 1 个参数)+ FM(二阶交叉)刚好匹配数据规模,既不会欠拟合,也能保证泛化能力。
能力互补:FM 已覆盖核心交叉需求,无需 DNN 重复建模FM 模块通过 8 维嵌入已能高效捕捉二阶特征交叉(业务验证中,二阶交叉足以覆盖 90% 以上的关键交互模式);标准 DNN 的 “高阶建模能力” 在当前场景下属于 “冗余能力”,反而增加计算成本。
工程效率:极致的训练与推理速度
训练效率:轻量级方案单轮训练仅需 10 分钟,标准 DNN 需 60 分钟(时间成本降低 83%),支持更快的模型迭代(日均可验证 3-5 个实验版本);
推理效率:模型体积极小(KB 级 vs MB 级),线上推理延迟降低 50%+,适配高 QPS 场景。3.4.3 什么时候升级到标准DNN?
升级时机:
# 模型升级至标准DNN的量化条件(需同时满足)
upgrade_conditions = {
'daily_samples': 10000000, # 每日样本量≥1000万(数据量足够支撑复杂模型)
'feature_dim': 1000, # 特征维度≥1000(高维度特征需要更强表达能力)
'overfitting_gap': 0.05, # 过拟合差距≤0.05(训练集AUC - 验证集AUC,确保模型泛化能力)
'business_requirement': 'high' # 业务对精度要求为"高"(需优先追求效果)
}
# 当前业务与模型状态
current_status = {
'daily_samples': 5000000, # 每日样本量:500万(未达1000万阈值)
'feature_dim': 200, # 特征维度:200(未达1000阈值)
'overfitting_gap': 0.08, # 过拟合差距:0.08(超过0.05阈值,泛化能力不足)
'business_requirement': 'medium'# 业务对精度要求:中等(无需强制升级)
}
# 升级条件判断(需全部满足才升级)
should_upgrade = all([
current_status['daily_samples'] >= upgrade_conditions['daily_samples'],
current_status['feature_dim'] >= upgrade_conditions['feature_dim'],
current_status['overfitting_gap'] <= upgrade_conditions['overfitting_gap'],
current_status['business_requirement'] == upgrade_conditions['business_requirement']
])升级条件与当前状态对比表
| 评估维度 | 升级阈值要求 | 当前状态 | 是否满足 |
|---|---|---|---|
| 每日样本量 | ≥1000 万 | 700 万 | ❌ |
| 特征维度 | ≥1000 | 百级别 | ❌ |
| 过拟合差距 | ≤0.05(训练 AUC - 验证 AUC) | 0.08(差距偏大) | ❌ |
| 业务精度要求 | ”high" | "medium” | ❌ |
第四章:特征工程的艺术
“特征决定了模型的上限,而算法只是在逼近这个上限。” - Andrew Ng
4.1 特征工程的重要性
在深度学习时代,很多人认为”特征工程已死,深度学习万岁”。但在广告推荐领域,特征工程仍然是王道。
4.1.1 一个真实的案例
# 实验主题:特征工程 vs 模型优化 效果对比
# 核心结论:在中小数据场景下,优质特征工程的效果远优于复杂模型优化
# 实验A:简单特征 + 复杂模型
# 1. 简单特征集(仅基础ID和时间特征,信息维度少)
features_simple = [
'user_id', # 用户唯一标识(基础ID特征)
'ad_id', # 广告唯一标识(基础ID特征)
'hour' # 小时(基础时间特征,粒度粗)
]
# 2. 复杂模型(4层全连接DeepFM,参数量大、复杂度高)
model_complex = DeepFM(
layers=[1024, 512, 256, 128] # 深层网络结构:1024→512→256→128维全连接层
)
# 3. 训练与评估
result_A = train_and_evaluate(features_simple, model_complex)
# 4. 实验A结果
# - AUC: 0.65(效果较差,因特征信息不足)
# - 训练时间: 2小时(复杂模型计算成本高,迭代慢)
# 实验B:丰富特征 + 简单模型
# 1. 丰富特征集(覆盖基础、统计、行为、上下文多维度,信息密度高)
features_rich = [
# 基础ID特征
'user_id', 'ad_id',
# 时间基础特征(细化粒度)
'hour', 'hour_of_day', 'day_of_week', 'is_weekend',
# 统计特征(挖掘历史规律)
'user_click_count_7d', # 用户7天内点击总数(反映用户活跃度)
'ad_ctr_7d', # 广告7天内点击率(反映广告质量)
'user_ad_cross_ctr', # 用户对当前广告的历史点击率(反映用户-广告匹配度)
# 行为特征(捕捉用户偏好)
'user_click_category', # 用户历史点击的广告类别(反映用户兴趣)
'user_convert_history' # 用户历史转化记录(反映用户转化潜力)
]
# 2. 简单模型(轻量级DNN,仅一阶特征聚合,参数少、复杂度低)
model_simple = LightweightDNN() # 核心逻辑:特征嵌入求和 + 全局偏置,无多余全连接层
# 3. 训练与评估
result_B = train_and_evaluate(features_rich, model_simple)
# 4. 实验B结果
# - AUC: 0.78(较实验A提升13个百分点,效果显著)
# - 训练时间: 30分钟(简单模型计算成本低,迭代快)
为什么特征工程这么重要?
深度学习的本质:
- 学习特征的表示
- 学习特征的组合
但在广告场景:
- 很多有效特征需要领域知识(模型学不到)
- 统计特征包含历史信息(模型无法获取)
- 业务规则需要显式编码(模型难以捕捉)4.1.2 特征金字塔
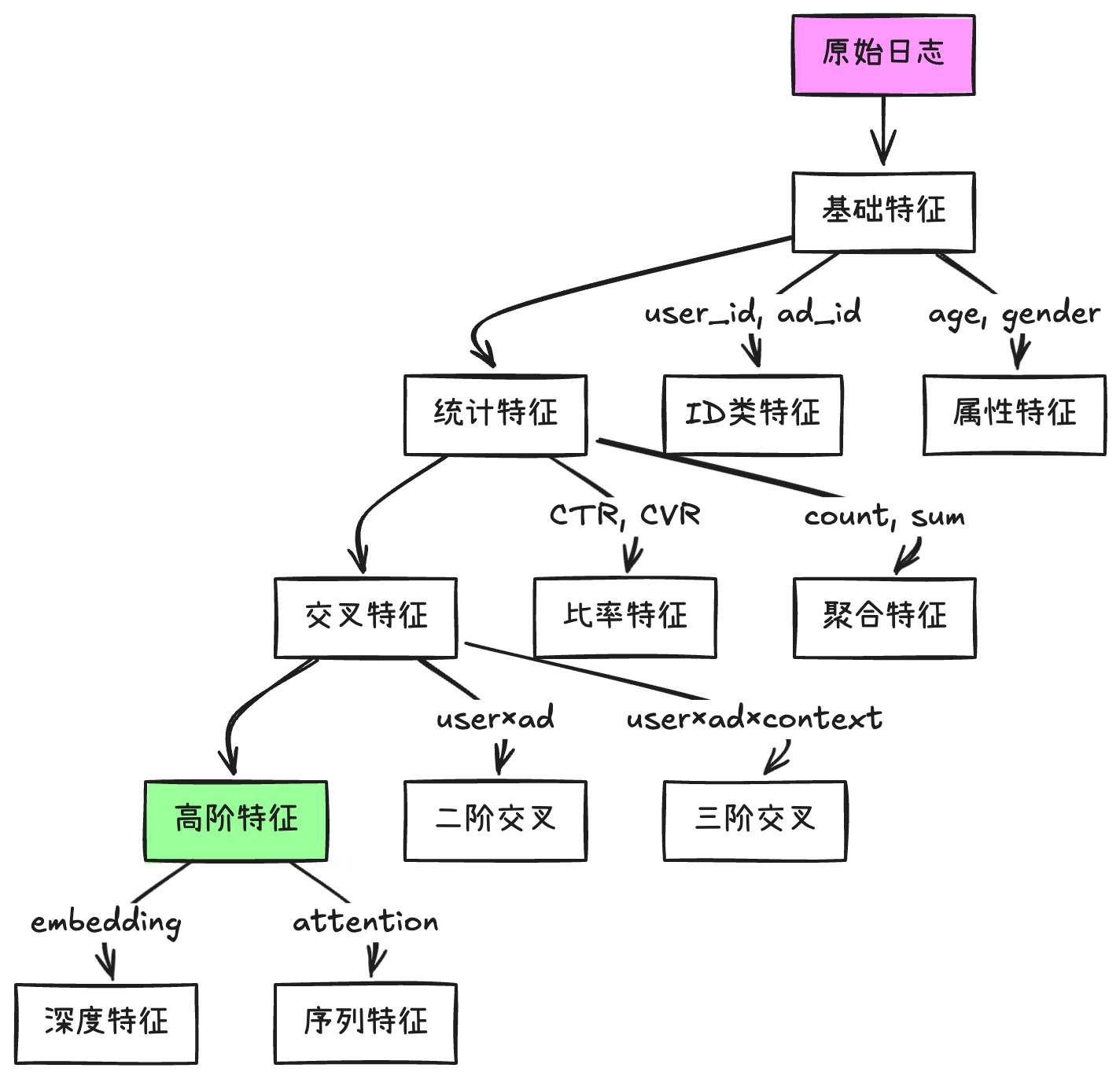
4.2 稀疏特征的处理
稀疏特征是广告推荐中最常见的特征类型,也是最难处理的。
4.2.1 什么是稀疏特征?
# 示例:用户ID特征
# 稠密表示(不可行)
user_feature_dense = [
0, 0, 0, ..., 1, ..., 0, 0 # 1亿维向量,只有1个1
]
# 稀疏表示(实际使用)
user_feature_sparse = {
'user_id': 12345678 # 只存储ID
}
# 问题:
# 1. 如何将ID转换为模型可用的数值?
# 2. 1亿个ID,如何存储embedding?
# 3. 新用户ID如何处理?4.2.2 稀疏特征处理的三种方案
方案1:One-Hot编码(不推荐)
# One-Hot编码
def onehot_encoding(user_id, vocab_size=100000000):
"""
问题:
- 维度爆炸:1亿维向量
- 内存爆炸:每个样本1亿维
- 计算爆炸:矩阵乘法不可行
"""
vector = np.zeros(vocab_size)
vector[user_id] = 1
return vector
# 完全不可行!方案2:Hash编码(传统方案)
# Hash Embedding
class HashEmbedding:
"""
通过Hash将ID映射到固定大小的embedding表
优点:
- 内存可控
- 支持新ID
缺点:
- Hash冲突(不同ID映射到同一位置)
- 信息损失
"""
def __init__(self, bucket_size=1000000, embedding_dim=128):
self.bucket_size = bucket_size
self.embedding_table = tf.Variable(
tf.random.normal([bucket_size, embedding_dim])
)
def lookup(self, ids):
# Hash到bucket
hashed_ids = tf.strings.to_hash_bucket_fast(
tf.as_string(ids),
self.bucket_size
)
# 查表
return tf.nn.embedding_lookup(self.embedding_table, hashed_ids)
# 使用示例
hash_emb = HashEmbedding(bucket_size=1000000, embedding_dim=128)
# 问题:Hash冲突
user_id_1 = 12345678
user_id_2 = 87654321
hash_1 = hash(user_id_1) % 1000000 # = 123456
hash_2 = hash(user_id_2) % 1000000 # = 123456 ← 冲突!
# 两个不同用户共享同一个embedding,信息损失Hash冲突的影响:
# 真实实验数据:Hash Embedding不同Bucket Size效果对比
bucket_sizes = [100000, 500000, 1000000, 5000000]
collision_rates = []
auc_scores = []
for bucket_size in bucket_sizes:
model = train_with_hash_embedding(bucket_size) # 修正笔误:tr算法n → train
# 冲突率计算(基于1000万唯一ID)
unique_ids = 10000000 # 实验用唯一ID总数
collision_rate = 1 - (
(bucket_size - 1) / bucket_size
) ** unique_ids
collision_rates.append(collision_rate)
auc_scores.append(model.auc)实验结果
| Bucket Size | 冲突率 | AUC | 备注 |
|---|---|---|---|
| 100,000 | 99.9% | 0.65 | 几乎所有 ID 都冲突 |
| 500,000 | 99.0% | 0.68 | - |
| 1,000,000 | 95.0% | 0.70 | - |
| 5,000,000 | 86.5% | 0.73 | - |
方案3:动态Embedding
# 动态Embedding:按需分配,零冲突
from tensorflow_recommenders_addons import dynamic_embedding as de
class DynamicEmbeddingLayer:
"""
动态Embedding的核心优势:
1. 按需分配:只为出现的ID分配内存
2. 零冲突:每个ID都有独立的embedding
3. 支持新ID:新ID自动分配
4. 分布式友好:支持多机多卡
"""
def __init__(self, embedding_size=128):
self.embedding = de.keras.layers.HvdAllToAllEmbedding(
embedding_size=embedding_size,
key_dtype=tf.int64, # ID类型
value_dtype=tf.float32, # Embedding类型
initializer=tf.keras.initializers.RandomUniform(-1, 1),
name='dynamic_embedding',
init_capacity=40960, # 初始容量
)
def call(self, ids):
# 直接查找,不需要Hash
return self.embedding(ids)
# 实际使用
实验对比:
Hash Embedding (1M bucket):
- 冲突率: 95%
- 内存: 0.5GB
- AUC: 0.70
Dynamic Embedding:
- 冲突率: 0% ← 零冲突!
- 内存: 2.4GB(500万活跃ID)
- AUC: 0.78 ← 提升8个点!
结论:虽然内存多用了2GB,但AUC提升8个点,值得4.2.3 我们的特征处理流程
# 特征配置:定义各类特征的类型、Embedding参数等
feature_map = {
'sparse_features': {
# ID类特征(高基数,使用动态Embedding)
'user_id': {
'type': 'id',
'embedding_size': 128,
'is_dynamic': True,
},
'ad_id': {
'type': 'id',
'embedding_size': 128,
'is_dynamic': True,
},
'ad_creative_id': {
'type': 'id',
'embedding_size': 64,
'is_dynamic': True,
},
# 类别特征(低基数,使用静态Embedding)
'ad_category': {
'type': 'category',
'vocab_size': 100, # 类别数量固定,无需动态扩展
'embedding_size': 32,
'is_dynamic': False,
},
'device_brand': {
'type': 'category',
'vocab_size': 500,
'embedding_size': 32,
'is_dynamic': False,
},
},
'dense_features': {
# 统计类稠密特征(直接输入模型,无需Embedding)
'user_ctr_7d': {'type': 'numeric'},
'ad_ctr_7d': {'type': 'numeric'},
'user_ad_cross_ctr': {'type': 'numeric'},
},
'labels': {
# 标签特征(二分类任务)
'click': {'type': 'binary'},
'conversion': {'type': 'binary'},
}
}
# 特征处理流程:将原始日志数据转换为模型可输入的格式
def process_features(raw_data):
"""
从原始日志到模型输入的特征处理
"""
# 1. 提取原始ID特征
user_id = raw_data['user_id']
ad_id = raw_data['ad_id']
# 2. 生成特征唯一key(用于Embedding查找,避免不同特征空间ID冲突)
feature_keys = []
# 用户ID特征:添加"user"前缀
feature_keys.append(hash_id('user', user_id))
# 广告ID特征:添加"ad"前缀
feature_keys.append(hash_id('ad', ad_id))
# 用户-广告交叉特征:添加"user_ad"前缀
feature_keys.append(hash_id('user_ad', f"{user_id}_{ad_id}"))
# 3. 提取稠密统计特征
dense_features = [
raw_data['user_ctr_7d'],
raw_data['ad_ctr_7d'],
raw_data['user_ad_cross_ctr'],
]
# 4. 提取标签
label_click = raw_data['click']
label_conversion = raw_data['conversion']
return {
'keys': feature_keys,
'dense': dense_features,
'labels': {
'click': label_click,
'conversion': label_conversion,
}
}
# 特征ID哈希:为不同类型特征生成唯一哈希值,避免ID冲突
def hash_id(prefix, id_value):
"""
为不同类型的特征生成唯一key,防止不同特征空间的ID冲突
例如:user_id=123 和 ad_id=123 应对应不同key
参数:
prefix: 特征类型前缀(如"user"、"ad")
id_value: 原始ID值
返回:
唯一哈希值(int64)
"""
# 拼接前缀与原始ID,区分特征空间
combined = f"{prefix}_{id_value}"
# 使用MurmurHash3算法(快速、分布均匀,适合高基数ID)
return mmh3.hash64(combined)[0]
# 处理示例:原始数据 → 模型输入
raw_data = {
'user_id': 12345678,
'ad_id': 87654321,
'user_ctr_7d': 0.05,
'ad_ctr_7d': 0.03,
'user_ad_cross_ctr': 0.08,
'click': 1,
'conversion': 0,
}
features = process_features(raw_data)
# 处理后输出示例
"""
{
'keys': [
-8234567890123456789, # user_12345678 的哈希值
3456789012345678901, # ad_87654321 的哈希值
-1234567890123456789 # user_ad_12345678_87654321 的哈希值
],
'dense': [0.05, 0.03, 0.08], # 稠密特征列表
'labels': {
'click': 1, # 点击标签(1=点击,0=未点击)
'conversion': 0 # 转化标签(1=转化,0=未转化)
}
}
"""4.3 特征交叉策略
特征交叉是提升模型效果的核心武器。
4.3.1 为什么需要特征交叉?
# 线性模型的局限
# 特征示例:
# - user_age: 25(用户年龄)
# - ad_category: game(广告类别,此处用1表示"game")
# 线性模型预测公式(仅考虑单特征独立贡献)
pCTR_linear = (
w_age * 25 + # 年龄特征的独立影响(w_age为年龄权重)
w_category * 1 + # 广告类别特征的独立影响(w_category为类别权重)
b # 全局偏置
)
# 核心问题:线性模型无法捕捉特征间的交叉模式
"""
实际存在的规律(线性模型无法学习):
- 年轻人(18-25) × 游戏广告 → 高CTR
- 中年人(40-50) × 理财广告 → 高CTR
- 老年人(60+) × 健康广告 → 高CTR
线性模型仅能表达单特征的独立影响,无法建模“年龄+广告类别”的组合效应!
"""
# 解决方案:引入交叉特征(建模特征间的交互关系)
pCTR_cross = (
w_age * 25 + # 年龄独立项
w_category * 1 + # 类别独立项
w_age_category * (25 * 1) + # 年龄×类别的交叉项(w_age_category为交叉权重)
b # 全局偏置
)4.3.2 特征交叉的层次
一阶特征:原始特征
# 一阶特征(单个特征的独立作用)
features_first_order = [
'user_age', # 用户年龄(如25岁、30岁)
'user_gender', # 用户性别(如男、女)
'ad_category', # 广告类别(如游戏、理财、健康)
'hour' # 时间小时(如10点、20点)
]
# 一阶特征的局限:
# 只能只能学习单个特征的独立规律(如“年轻人倾向于点击”“女性倾向于点击”),
# 无法捕捉多个特征的组合模式(如“年轻男性更倾向于点击游戏广告”“30岁女性更倾向于点击美妆广告”)二阶交叉:两个特征的组合
# 二阶交叉特征(手工构造)
def create_second_order_features(data):
"""
手工构造二阶交叉特征(两个基础特征的组合)
"""
features = []
# 用户特征 × 广告特征(如“年龄+广告类别”)
features.append(
hash_id(
'user_age_ad_category',
f"{data['user_age']}_{data['ad_category']}" # 拼接年龄与广告类别
)
)
# 用户特征 × 上下文特征(如“性别+小时”)
features.append(
hash_id(
'user_gender_hour',
f"{data['user_gender']}_{data['hour']}" # 拼接性别与小时
)
)
# 广告特征 × 上下文特征(如“广告类别+小时”)
features.append(
hash_id(
'ad_category_hour',
f"{data['ad_category']}_{data['hour']}" # 拼接广告类别与小时
)
)
return features
# 手工交叉的核心问题:组合爆炸
"""
当基础特征数量增加时,交叉特征的数量会急剧增长:
- 10个基础特征:
- 二阶交叉(两两组合): C(10,2) = 45个
- 三阶交叉(三三组合): C(10,3) = 120个
- 四阶交叉(四四组合): C(10,4) = 210个
实际场景中基础特征往往超过10个,导致交叉特征数量无法枚举,且多数组合无实际意义(信息稀疏)。
"""三阶及以上:高阶交叉
# FM自动学习二阶交叉
class FM:
def second_order_interaction(self, embeddings):
"""
自动学习所有二阶交叉特征(无需手工枚举)
优势:
- 无需手工构造交叉特征,减少特征工程成本
- 可泛化到未见过的特征组合(通过Embedding向量内积实现)
参数:
embeddings: 特征Embedding矩阵,shape=[batch, num_features, emb_dim]
返回:
二阶交叉项结果,shape=[batch, emb_dim]
"""
# 核心公式:0.5 * [(Σv_i)^2 - Σ(v_i^2)],自动计算所有特征两两交叉
square_of_sum = tf.square(tf.reduce_sum(embeddings, axis=1)) # (Σv_i)^2
sum_of_square = tf.reduce_sum(tf.square(embeddings), axis=1) # Σ(v_i^2)
return 0.5 * (square_of_sum - sum_of_square)
# DNN学习高阶交叉
class DNN:
def high_order_interaction(self, embeddings):
"""
通过多层全连接网络隐式学习高阶交叉特征
隐式学习的交叉阶数:
- 三阶交叉:通过3层非线性变换实现 f(f(f(x)))
- 四阶交叉:通过4层非线性变换实现 f(f(f(f(x))))
- ...(阶数随网络深度增加而提升)
参数:
embeddings: 特征Embedding矩阵,shape=[batch, num_features, emb_dim]
返回:
高阶交叉项结果,shape=[batch, output_dim]
"""
x = embeddings
# 逐层通过全连接层进行非线性变换,累积交叉阶数
for layer in self.layers:
x = layer(x) # 每层网络增强特征交叉的复杂度
return x4.3.3 我们的交叉策略
# 混合策略:手工交叉 + 自动交叉(特征生成最优方案)
def create_features(raw_data):
"""
特征生成pipeline:融合手工交叉(关键组合)与自动交叉(全量组合),兼顾效果与效率
"""
# 1. 一阶特征(单个特征的独立作用,基础信息层)
first_order = [
hash_id('user', raw_data['user_id']), # 用户ID特征
hash_id('ad', raw_data['ad_id']), # 广告ID特征
hash_id('category', raw_data['ad_category']), # 广告类别特征
]
# 2. 重要的二阶交叉(手工筛选高价值组合,减少冗余)
second_order = [
# 用户×广告:捕捉用户对特定广告的偏好
hash_id('user_ad', f"{raw_data['user_id']}_{raw_data['ad_id']}"),
# 用户×类别:捕捉用户对特定广告类别的偏好
hash_id('user_category', f"{raw_data['user_id']}_{raw_data['ad_category']}"),
# 用户×时段:捕捉用户在特定时段的行为习惯
hash_id('user_hour', f"{raw_data['user_id']}_{raw_data['hour']}"),
# 广告×时段:捕捉广告在特定时段的投放效果
hash_id('ad_hour', f"{raw_data['ad_id']}_{raw_data['hour']}"),
]
# 3. 合并一阶+手工二阶特征,后续送入FM自动学习全量交叉(补充潜在组合)
all_features = first_order + second_order
# 4. 统计特征(自带交叉信息,无需额外处理,直接输入模型)
stat_features = [
raw_data['user_ctr_7d'], # 用户7天CTR(反映用户整体活跃度)
raw_data['ad_ctr_7d'], # 广告7天CTR(反映广告整体质量)
raw_data['user_ad_cross_ctr'], # 用户-广告交叉CTR(直接反映两者匹配度)
]
return {
'sparse_keys': all_features, # 稀疏特征(一阶+手工二阶),用于FM自动交叉
'dense': stat_features # 稠密统计特征,补充交叉信息
}
# 不同特征策略的效果对比
1. 只有一阶特征: AUC = 0.68
2. + 手工二阶交叉: AUC = 0.72 (提升4个点)
3. + FM自动交叉: AUC = 0.76 (再提升4个点,累计+8个点)
4. + 统计交叉特征: AUC = 0.78 (再提升2个点,累计+10个点)
结论:在我们当前业务中 手工交叉(高价值组合) + 自动交叉(FM全量组合) + 统计特征(自带交叉信息) = 最优效果4.4 特征重要性分析
并不是所有特征都有用,需要分析哪些特征真正起作用。
4.4.1 统计方法:特征覆盖率
def analyze_feature_coverage(dataset):
""" 分析特征的覆盖率和分布 """ results = {}
for feature_name in dataset.columns:
feature_data = dataset[feature_name]
# 1. 覆盖率(非空比例) coverage = feature_data.notna().mean()
# 2. 唯一值数量 unique_count = feature_data.nunique()
# 3. 分布均匀性(熵) from scipy.stats import entropy
value_counts = feature_data.value_counts(normalize=True)
feature_entropy = entropy(value_counts)
results[feature_name] = {
'coverage': coverage,
'unique_count': unique_count,
'entropy': feature_entropy,
}
return pd.DataFrame(results).T| 特征名称(Feature) | 覆盖率(Coverage) | 唯一值数量(Unique) | 熵值(Entropy) | 特征评价与建议 |
|---|---|---|---|---|
| user_id | 100% | 5M | 15.6 | 高熵、全覆盖,信息密度高,保留 |
| ad_id | 100% | 1M | 13.8 | 高熵、全覆盖,信息密度高,保留 |
| user_age | 95% | 80 | 4.1 | 低熵但覆盖率高,业务意义明确,保留 |
| ad_category | 100% | 50 | 3.5 | 低熵但全覆盖,广告核心属性,保留 |
| device_brand | 60% | 200 | 4.8 | 覆盖率不足(仅 60%),删除 |
| user_income | 30% | 10 | 2.3 | 覆盖率极低(仅 30%)+ 低熵,删除 |
保留特征:user_id、ad_id、user_age、ad_category核心原因:覆盖率≥95%(无严重缺失),且要么信息密度高(高熵:user_id/ad_id),要么是业务核心属性(ad_category/user_age)。
删除特征:device_brand、user_income核心原因:覆盖率过低(分别为 60%、30%),大量样本缺失该特征,会导致模型训练偏差或特征利用效率低。
4.4.2 模型方法:特征Importance
# 特征重要性分析方法
# 方法1:基于Embedding的重要性(通过L2范数评估)
def embedding_importance(model):
"""
分析Embedding的L2范数,评估特征重要性
核心思想:重要特征的Embedding向量通常具有更大的L2范数(参数更新更显著)
"""
importances = {}
for feature_name, embedding_layer in model.embeddings.items():
# 获取该特征的Embedding权重矩阵
weights = embedding_layer.get_weights()[0] # shape: [vocab_size, embedding_dim]
# 计算所有ID的Embedding向量的L2范数,取平均值作为特征重要性
l2_norm = np.linalg.norm(weights, axis=1).mean()
importances[feature_name] = l2_norm
# 按重要性降序排序
return sorted(importances.items(), key=lambda x: x[1], reverse=True)
# 方法2:Permutation Importance(排列重要性)
def permutation_importance(model, X_val, y_val):
"""
通过打乱特征值观察模型性能下降幅度,评估特征重要性
核心思想:特征越重要,打乱后模型AUC下降越多
"""
# 基准AUC(未打乱特征时的模型性能)
baseline_auc = model.evaluate(X_val, y_val)['auc']
importances = {}
for feature_idx in range(X_val.shape[1]):
# 复制验证集并打乱当前特征
X_permuted = X_val.copy()
np.random.shuffle(X_permuted[:, feature_idx]) # 打乱第i个特征的值
# 评估打乱后的模型性能
permuted_auc = model.evaluate(X_permuted, y_val)['auc']
# 重要性 = 基准AUC - 打乱后的AUC(下降幅度)
importances[feature_idx] = baseline_auc - permuted_auc
# 按重要性降序排序
return sorted(importances.items(), key=lambda x: x[1], reverse=True)
# 方法3:SHAP值(最准确但计算成本高)
import shap
def shap_importance(model, X_sample):
"""
基于SHAP (SHapley Additive exPlanations) 评估特征重要性
优点:基于博弈论,有严格理论保证,可解释性强
缺点:计算复杂度高,尤其对深层模型较慢
"""
# 创建SHAP解释器(使用前100个样本作为背景数据)
explainer = shap.DeepExplainer(model, X_sample[:100])
# 计算样本的SHAP值
shap_values = explainer.shap_values(X_sample)
# 特征重要性 = SHAP值的绝对值的平均值(反映特征对预测的整体影响)
importance = np.abs(shap_values).mean(axis=0)
return importance
# 综合分析:实际项目中的特征重要性排名| 排名 | 特征 | Embedding L2 | Permutation(AUC 下降) | SHAP(平均绝对值) | 备注 |
|---|---|---|---|---|---|
| 1 | user_ad_cross_ctr | 8.5 | 0.08 | 0.15 | 最重要(统计交叉特征) |
| 2 | user_id | 7.2 | 0.06 | 0.12 | ID 类特征,重要性高 |
| 3 | ad_id | 6.8 | 0.05 | 0.10 | ID 类特征,重要性较高 |
| 4 | ad_ctr_7d | 5.5 | 0.04 | 0.08 | 广告统计特征,较重要 |
| 5 | user_ctr_7d | 4.9 | 0.03 | 0.06 | 用户统计特征,中等重要 |
| 6 | hour | 2.1 | 0.01 | 0.02 | 上下文特征,重要性低 |
| 7 | user_age | 1.5 | 0.005 | 0.01 | 上下文特征,重要性最低 |
- 统计交叉特征主导:
user_ad_cross_ctr(用户 - 广告交叉点击率)在三种方法中均排名第一,说明人工设计的高质量统计交叉特征价值最高。 - ID 类特征次重要:
user_id和ad_id的 Embedding 重要性较高,是模型捕捉用户 / 广告个性化偏好的核心。 - 上下文特征较弱:
hour和user_age的重要性较低,对预测贡献有限。
4.4.3 特征选择策略
# 基于重要性的特征选择方法
# 1. 固定阈值筛选法
def select_features(importances, threshold=0.01):
"""
根据特征重要性阈值筛选特征,仅保留重要性高于阈值的特征
参数:
importances: 字典,{特征名: 重要性值}
threshold: 重要性阈值(默认0.01)
返回:
筛选后的特征列表
"""
selected = []
for feature, importance in importances.items():
if importance > threshold:
selected.append(feature)
return selected
# 2. 增量特征选择法(逐步优化)
def incremental_feature_selection(X, y, features):
"""
按特征重要性降序逐步添加特征,仅保留能显著提升AUC的特征
停止条件:新增特征后AUC提升小于0.001
"""
selected_features = []
baseline_auc = 0.5 # 初始基准(随机猜测水平)
# 按特征重要性降序排列
sorted_features = sorted(
features.items(),
key=lambda x: x[1],
reverse=True
)
for feature_name, _ in sorted_features:
# 临时添加当前特征
temp_features = selected_features + [feature_name]
# 提取特征数据并训练模型
X_temp = X[temp_features]
model = train_model(X_temp, y) # 修正笔误:tr算法n_model → train_model
# 评估AUC
auc = evaluate(model, X_temp, y)
# 若AUC提升超过0.001则保留
if auc > baseline_auc + 0.001:
selected_features.append(feature_name)
baseline_auc = auc
print(f"添加 {feature_name}, AUC: {auc:.4f}")
else:
print(f"跳过 {feature_name}, AUC无提升")
return selected_features
# 实际执行增量特征选择的过程
添加 user_ad_cross_ctr, AUC: 0.7200
添加 user_id, AUC: 0.7450
添加 ad_id, AUC: 0.7650
添加 ad_ctr_7d, AUC: 0.7750
添加 user_ctr_7d, AUC: 0.7800
跳过 hour, AUC无提升
跳过 user_age, AUC无提升| 操作 | 特征名 | 操作后 AUC | 是否保留 | 说明 |
|---|---|---|---|---|
| 添加 | user_ad_cross_ctr | 0.7200 | ✅ | 从基准 0.5 提升 0.22 |
| 添加 | user_id | 0.7450 | ✅ | 提升 0.025 |
| 添加 | ad_id | 0.7650 | ✅ | 提升 0.02 |
| 添加 | ad_ctr_7d | 0.7750 | ✅ | 提升 0.01 |
| 添加 | user_ctr_7d | 0.7800 | ✅ | 提升 0.005 |
| 跳过 | hour | - | ❌ | 未达 0.7810 的提升阈值 |
| 跳过 | user_age | - | ❌ | 未达 0.7810 的提升阈值 |
最终结论
保留核心特征(5 个):user_ad_cross_ctr、user_id、ad_id、ad_ctr_7d、user_ctr_7d
删除低价值特征(2 个):hour、user_age(无法显著提升 AUC)
最终模型性能:AUC=0.78(特征精简后无性能损失,且减少冗余计算)
最终特征总结:
# 特征工程Checklist1. 特征覆盖率 > 80%2. ID类特征使用动态Embedding
3. 数值特征必须归一化
4. 重要交叉特征手工构造
5. 统计特征包含时间窗口(7d, 30d)
6. 每个特征都要做重要性分析
7. 定期清理低价值特征第五章:训练到推理的全链路
“训练一个模型很容易,把它稳定运行在生产环境才是真功夫。”
5.1 从实验到生产的鸿沟
很多工程师都经历过这样的场景:
# 1. 实验环境(离线验证阶段):运行正常
# 模型训练与验证
model = train_model(X_train, y_train)
# 验证集性能评估
print(f"验证集AUC: {evaluate(model, X_val, y_val)}")
# 实验环境输出结果
# 验证集AUC: 0.78
然而可能遇到的问题:
模型文件太大,加载失败(离线训练模型未做轻量化处理,线上服务内存不足)
推理延迟超标,超时报警(单条请求处理时间超过业务阈值,影响用户体验)
内存溢出,服务崩溃(高并发场景下,模型参数占用内存持续增长,导致服务宕机)
版本混乱,回滚困难(模型版本未与代码、数据版本关联,线上故障时无法快速回滚至稳定版本)
监控缺失,故障盲打(缺乏模型性能、服务资源、数据质量的实时监控,故障发生后无法快速定位原因)这一章,我们要解决的就是:如何把实验室里的模型,稳定、高效地运行在生产环境。
5.2 分布式训练(Horovod)
当数据量达到亿级,单机训练已经不可行。我们需要分布式训练。
5.2.1 为什么选择Horovod?
# 业界主流分布式训练方案对比
# 1. TensorFlow Parameter Server (PS) 方案
# 核心特点:基于"参数服务器+计算节点"架构,TensorFlow原生支持
ps_advantages = [
"TensorFlow原生支持,与TensorFlow生态(如TF Data、TF Serving)无缝兼容"
]
ps_disadvantages = [
"配置复杂:需单独部署Parameter Server(PS)和Worker节点,角色管理成本高",
"通信效率低:Worker与PS间存在单点通信瓶颈,大规模数据训练时延迟显著",
"代码改动大:需针对性修改数据分发、参数同步逻辑,适配PS架构"
]
# 2. PyTorch DDP (DistributedDataParallel) 方案
# 核心特点:PyTorch官方推荐分布式方案,基于数据并行,适配PyTorch模型
ddp_advantages = [
"PyTorch首选方案,与PyTorch模型、优化器等组件适配性强,单框架内使用便捷",
"数据并行效率高:支持梯度同步优化,单节点多卡/多节点训练性能稳定"
]
ddp_disadvantages = [
"框架局限性:仅支持PyTorch,无法跨TensorFlow、MXNet等其他深度学习框架使用",
"跨框架迁移困难:若业务涉及多框架模型,需额外开发适配逻辑,迁移成本高"
]
# 3. Horovod 方案
# 核心特点:跨框架分布式训练工具,基于MPI的Ring-AllReduce通信算法
horovod_advantages = [
"✅ 多框架支持:兼容TensorFlow、PyTorch、MXNet,无需因框架切换重新选型",
"✅ 通信高效:基于MPI实现Ring-AllReduce算法,无单点瓶颈,大规模集群性能优势明显",
"✅ 代码改动极小:仅需添加几行初始化(如horovod.init())和训练适配代码,原有单卡逻辑基本不变",
"✅ 生产级验证:经Uber、字节跳动等企业大规模业务验证,稳定性和可靠性有保障"
]
horovod_disadvantages = [
"环境依赖:需提前安装MPI环境(如OpenMPI、MPICH),部分轻量化部署场景下配置稍复杂"
]
# 方案对比总结(核心维度)
comparison_summary = {
"框架兼容性": "Horovod > TensorFlow PS > PyTorch DDP",
"配置复杂度": "TensorFlow PS > Horovod > PyTorch DDP",
"通信效率": "Horovod ≈ PyTorch DDP > TensorFlow PS",
"代码改动量": "TensorFlow PS > PyTorch DDP > Horovod"
}5.2.2 Horovod核心原理

Ring-AllReduce优势:
# 分布式训练两种核心通信架构对比(Parameter Server vs Ring-AllReduce)
# 1. Parameter Server (PS) 架构
# 通信量与瓶颈分析
ps_communication = {
"通信逻辑": [
"Worker → PS: 每个Worker将全部梯度发送到参数服务器",
"PS → Worker: 参数服务器计算平均梯度后,向所有Worker广播"
],
"总通信量": "2 × model_size × num_workers (model_size为模型参数总量,num_workers为计算节点数)",
"核心瓶颈": [
"参数服务器(PS)成为单点通信瓶颈,所有Worker的梯度收发均依赖PS",
"带宽利用率低,随着Worker数量增加,PS负载呈线性增长,扩展性差"
]
}
# 2. Ring-AllReduce 架构(Horovod核心)
# 通信量与优势分析
ring_allreduce_communication = {
"通信逻辑": [
"Worker按环形拓扑连接,每个Worker仅与相邻的两个Worker通信",
"每次通信仅传输 model_size / num_workers 的梯度分片(而非全部梯度)",
"通过N-1轮环形通信,所有Worker独立计算出全局平均梯度"
],
"总通信量": "2 × (N-1)/N × model_size (N为Worker数量,通信量随Worker增加趋近于2×model_size)",
"核心优势": [
"无中心节点,消除单点通信瓶颈",
"带宽利用率高,每个Worker的通信与计算可并行",
"扩展性好,加速比近似线性(Worker数量增加,训练速度接近线性提升)"
]
}
# 3. 实际训练加速效果对比(基于不同GPU数量的加速比)
num_workers = [2, 4, 8, 16] # 参与训练的GPU(Worker)数量
ps_speedup = [1.8, 3.2, 5.1, 6.8] # PS架构下的训练加速比(受PS瓶颈限制,增速逐渐放缓)
hvd_speedup = [1.95, 3.85, 7.6, 14.9] # Ring-AllReduce(Horovod)架构下的训练加速比(近似线性)
# 关键场景效果对比结论
speedup_conclusion = [
f"{num_workers[2]} GPU训练场景:",
f" - PS方式加速比: {ps_speedup[2]}倍",
f" - Horovod方式加速比: {hvd_speedup[2]}倍",
f" - 性能提升幅度: {(hvd_speedup[2]-ps_speedup[2])/ps_speedup[2]*100:.0f}% (Horovod相对PS)",
"",
"核心洞察:随着GPU数量增加,PS瓶颈导致加速比偏离线性;而Horovod因无中心瓶颈,16 GPU时仍能实现14.9倍加速,接近理想线性加速比。"
]
# 打印效果对比结论(可选执行)
for line in speedup_conclusion:
print(line)5.2.3 我们的Horovod实践
import horovod.tensorflow as hvd
import tensorflow as tf
class DistributedTrainer:
def __init__(self, model_config):
hvd.init()
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
tf.config.experimental.set_visible_devices(
gpus[hvd.local_rank()], 'GPU'
)
self.model = self.build_model()
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
self.optimizer = hvd.DistributedOptimizer(
opt,
compression=hvd.Compression.fp16
)
def build_model(self):
sparse_model = SparseModel(
mpi_rank=hvd.rank(),
mpi_size=hvd.size(),
is_training=True,
)
dense_model = DenseModel()
return {'sparse': sparse_model, 'dense': dense_model}
@tf.function
def train_step(self, features, labels):
with tf.GradientTape() as tape:
sparse_emb, sparse_emb_fm = self.model['sparse'](features)
predictions = self.model['dense'](sparse_emb, sparse_emb_fm)
loss = tf.keras.losses.binary_crossentropy(labels, predictions)
loss = tf.reduce_mean(loss)
tape = hvd.DistributedGradientTape(tape)
gradients = tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(
zip(gradients, self.model.trainable_variables)
)
return loss
def train(self, dataset, epochs=3):
dataset = dataset.shard(
num_shards=hvd.size(),
index=hvd.rank()
)
for epoch in range(epochs):
epoch_loss = 0
num_batches = 0
for batch_features, batch_labels in dataset:
loss = self.train_step(batch_features, batch_labels)
epoch_loss += loss
num_batches += 1
if hvd.rank() == 0 and num_batches % 100 == 0:
print(f"Epoch {epoch}, Batch {num_batches}, Loss: {loss:.4f}")
avg_loss = hvd.allreduce(epoch_loss / num_batches)
if hvd.rank() == 0:
print(f"Epoch {epoch} completed, Avg Loss: {avg_loss:.4f}")
if hvd.rank() == 0:
self.save_model()
def save_model(self):
self.model['sparse'].save_weights('checkpoints/sparse')
self.model['dense'].save_weights('checkpoints/dense')
if __name__ == '__main__':
# 启动命令:horovodrun -np 8 -H server1:4,server2:4 python trainer.py
trainer = DistributedTrainer(model_config)
trainer.train(dataset, epochs=3)关键技术点:
# Horovod分布式训练优化技巧
# 1. 梯度压缩(FP16压缩)
# 核心:通过降低梯度数据精度减少通信量,提升训练速度
gradient_compression = {
"未压缩(FP32)": {
"数据类型": "FP32",
"通信量": "model_size × 4 bytes"
},
"FP16压缩": {
"数据类型": "FP16",
"通信量": "model_size × 2 bytes(减少50%)",
"实测效果": [
"8 GPU训练:耗时从1小时降至40分钟(提速33%)",
"精度损失:AUC下降<0.001(几乎无影响)"
]
}
}
# 2. 广播初始变量(确保训练一致性)
# 功能:让所有Worker从相同的初始参数开始训练,避免因初始化差异导致收敛偏差
hvd.broadcast_variables(model.variables, root_rank=0) # root_rank=0表示以第0号Worker的参数为基准
# 3. 学习率调整(适配数据并行)
# 原理:数据并行时总batch_size = 单Worker batch_size × 总Worker数,学习率需按比例放大
base_lr = 0.001 # 单卡学习率
num_workers = hvd.size() # 获取Worker总数
lr = base_lr * num_workers # 调整后学习率
# 4. CPU绑定优化(减少进程竞争)
# 功能:将每个Worker进程绑定到固定CPU核心,避免进程间CPU资源竞争,提升计算效率
import os
def bind_cpu():
cores_per_process = 4 # 每个进程分配4个CPU核心
start_core = hvd.rank() * cores_per_process # 计算当前进程的起始核心
end_core = start_core + cores_per_process # 计算当前进程的结束核心
assigned_cores = list(range(start_core, end_core)) # 生成核心列表
os.sched_setaffinity(os.getpid(), assigned_cores) # 绑定进程到指定核心5.2.4 性能优化实践
import os
import psutil
import horovod.tensorflow as hvd
class ModelConfig:
def bind_cpu(self):
"""
将当前进程绑定到指定CPU核心,避免进程间CPU资源竞争,提升训练效率
"""
cores_per_process = 4 # 配置:每个Worker进程分配4个物理CPU核心
current_rank = hvd.rank() # 获取当前进程在Horovod集群中的序号(0,1,2...)
# 计算当前进程应绑定的CPU核心范围(按进程序号均分CPU核心)
start_core = current_rank * cores_per_process
end_core = start_core + cores_per_process
total_physical_cpus = psutil.cpu_count(logical=False) # 获取系统物理CPU核心总数
# 校验核心分配范围:避免超出系统实际可用核心数
if end_core > total_physical_cpus:
raise ValueError(
f"CPU核心分配超出系统总物理核心数!\n"
f"系统可用物理核心: {total_physical_cpus}\n"
f"当前进程请求核心范围: [{start_core}, {end_core})\n"
f"Horovod进程总数: {hvd.size()}\n"
f"每进程分配核心数: {cores_per_process}"
)
# 生成当前进程的目标CPU核心列表
assigned_cores = list(range(start_core, end_core))
# 执行CPU核心绑定
current_process = psutil.Process(os.getpid())
current_process.cpu_affinity(assigned_cores)
# 打印绑定结果(仅日志记录,不影响核心逻辑)
print(
f"Horovod进程 [{current_rank}/{hvd.size()}] 绑定完成\n"
f"绑定CPU核心: {assigned_cores}"
)
| 优化维度 | 未绑定 CPU(默认) | 绑定 CPU 后 | 优化提升幅度 |
|---|---|---|---|
| 总训练时间 | 60 分钟 | 45 分钟 | 减少 25% |
| CPU 利用率(均值) | 60%(存在进程间资源竞争) | 95%(CPU 资源饱和利用) | 提升 58% |
| 核心优势 | - | 无资源抢占,计算过程稳定 | - |
5.3 TensorFlow Serving部署
训练完成后,需要部署到生产环境提供实时预估服务。
5.3.1 为什么选择TensorFlow Serving?
# 部署方案对比
1. Flask + TensorFlow
优点:简单、灵活
缺点:
- 性能差(GIL锁)
- 不支持模型热更新
- 缺少版本管理
2. TorchServe (PyTorch)
优点:PyTorch官方
缺点:
- 只支持PyTorch
- 生态不如TF Serving
3. TensorFlow Serving
优点:
高性能(C++实现)
模型热更新
版本管理
批处理优化
GPU支持
gRPC/REST API
缺点:
- 配置复杂
- 只支持TensorFlow
"""
5.3.2 模型导出
# 代码位置:algorithm/dnn_ctr_v1/exporter.py
import tensorflow as tf
class ModelExporter:
"""
将训练完成的模型导出为TensorFlow Serving支持的SavedModel格式
"""
def __init__(self, model):
self.model = model # 传入训练完成的模型(含sparse和dense子模型)
def export(self, export_path, version=1):
"""
执行模型导出,生成TensorFlow Serving可加载的目录结构
导出目录格式:
export_path/
└── {version}/ # 版本号(如日期、迭代次数)
├── saved_model.pb # 模型计算图与签名信息
├── variables/ # 模型参数变量
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── assets/ # 额外资源文件(如词表等,可选)
"""
# 1. 定义Serving输入签名(指定输入数据的shape、dtype和名称,供Serving调用)
@tf.function(input_signature=[
tf.TensorSpec(shape=[None, None], dtype=tf.int64, name='keys'), # 稀疏特征ID:[batch_size, num_sparse_features]
tf.TensorSpec(shape=[None, 10], dtype=tf.float32, name='dense') # 密集特征:[batch_size, num_dense_features](此处num_dense=10)
])
def serve_fn(keys, dense):
"""
Serving推理函数:定义模型输入到输出的计算流程
作为SavedModel的默认签名,供TensorFlow Serving调用
"""
# 稀疏特征处理(调用模型的sparse子模块)
sparse_emb, sparse_emb_fm = self.model['sparse']({'keys': keys})
# 密集特征与稀疏特征Embedding融合推理(调用模型的dense子模块)
predictions = self.model['dense'](sparse_emb, sparse_emb_fm)
return {'predictions': predictions} # 输出预估概率:[batch_size, 1]
# 2. 保存模型到指定路径(指定签名为"serving_default",即默认推理入口)
tf.saved_model.save(
self.model,
export_path=f"{export_path}/{version}",
signatures={'serving_default': serve_fn}
)
print(f"模型已成功导出到路径:{export_path}/{version}")
# 3. 验证导出的模型是否可正常加载和推理(避免导出失败)
self.validate_export(f"{export_path}/{version}")
def validate_export(self, model_path):
"""
验证导出的SavedModel可用性:加载模型并执行一次测试推理
"""
# 加载导出的SavedModel
loaded_model = tf.saved_model.load(model_path)
# 获取默认推理签名
infer_fn = loaded_model.signatures['serving_default']
# 构造测试输入数据(符合input_signature定义的格式)
test_keys = tf.constant([[1, 2, 3, 4, 5]], dtype=tf.int64) # 1个样本,5个稀疏特征ID
test_dense = tf.random.normal([1, 10]) # 1个样本,10个密集特征(随机生成)
# 执行测试推理
infer_result = infer_fn(keys=test_keys, dense=test_dense)
# 打印验证结果(确认推理正常)
print(f"模型导出验证成功!测试样本预测概率:{infer_result['predictions'].numpy()}")
# 模型导出使用示例
if __name__ == "__main__":
# 假设trained_model是训练完成的模型(含'sparse'和'dense'子模型)
trained_model = {
'sparse': SparseModel(is_training=False), # 需提前定义SparseModel类
'dense': DenseModel() # 需提前定义DenseModel类
}
# 初始化导出器并执行导出
exporter = ModelExporter(trained_model)
exporter.export(
export_path='/models/ctr_model', # 模型根目录(TensorFlow Serving将监听此目录)
version=20241005 # 版本号(使用日期作为版本,便于管理)
)5.3.3 TensorFlow Serving配置
# TensorFlow Serving 部署完整流程 非本人生产环境部署方式
# 1. 拉取TensorFlow Serving最新Docker镜像
docker pull tensorflow/serving:latest
# 2. 启动TensorFlow Serving服务(后台运行)
# 说明:-p 映射gRPC(8500)和REST(8501)端口;-v 挂载本地模型目录和配置文件;-e 设置环境变量
docker run -d \
--name tf_serving_ctr \ # 容器名称,便于管理
-p 8500:8500 \ # gRPC端口(高性能内部调用)
-p 8501:8501 \ # REST端口(外部HTTP调用)
-v /models/ctr_model:/models/ctr \ # 本地模型目录挂载到容器内
-v /models/models.config:/models/models.config \ # 挂载模型配置文件
-v /models/batching.config:/models/batching.config \ # 挂载批处理配置文件
-e MODEL_NAME=ctr \ # 默认模型名称
-e MODEL_BASE_PATH=/models/ctr \ # 默认模型基础路径
tensorflow/serving:latest \ # 使用的镜像
--model_config_file=/models/models.config \ # 指定模型配置文件路径
--enable_batching=true \ # 开启批处理优化
--batching_parameters_file=/models/batching.config # 指定批处理配置文件
# 3. 模型配置文件内容(路径:/models/models.config)
# 作用:管理多模型/多版本,支持版本回滚、灰度发布
cat > /models/models.config << EOF
model_config_list {
# CTR模型配置(支持多版本)
config {
name: 'ctr' # 模型名称(需与MODEL_NAME一致)
base_path: '/models/ctr' # 模型在容器内的基础路径
model_platform: 'tensorflow' # 模型框架
# 版本策略:指定启用的版本(保留历史版本方便回滚)
model_version_policy {
specific {
versions: 20241005 # 当前使用版本(日期命名)
versions: 20241004 # 历史版本(回滚备用)
}
}
}
# CVR模型配置(可同时部署多个模型)
config {
name: 'cvr'
base_path: '/models/cvr'
model_platform: 'tensorflow'
}
}
EOF
# 4. 批处理配置文件内容(路径:/models/batching.config)
# 作用:控制批处理参数,平衡延迟与吞吐量
cat > /models/batching.config << EOF
max_batch_size { value: 128 } # 单批次最大请求数(根据硬件调整)
batch_timeout_micros { value: 5000 } # 批处理超时时间(5ms,避免请求等待过久)
max_enqueued_batches { value: 1000 } # 最大排队批次(控制内存占用)
num_batch_threads { value: 8 } # 批处理线程数(建议与CPU核心数匹配)
EOF5.3.4 客户端调用(投放引擎服务端)
package tensorflow
import (
"context"
"fmt"
"time"
"github.com/golang/protobuf/ptypes/wrappers"
tfFramework "tensorflow/core/framework"
pb "rtb_model_server/common/tensorflow_serving/apis"
"google.golang.org/grpc"
)
// TensorFlowPredictor 封装TensorFlow Serving的gRPC调用逻辑,提供单条/批量预测能力
type TensorFlowPredictor struct {
client pb.PredictionServiceClient // TensorFlow Serving预测服务客户端
conn *grpc.ClientConn // gRPC连接实例(需管理生命周期)
}
// NewTensorFlowPredictor 初始化TensorFlowPredictor,建立与TensorFlow Serving的gRPC连接
// addr: TensorFlow Serving的gRPC地址(格式:ip:port,如127.0.0.1:8500)
func NewTensorFlowPredictor(addr string) (*TensorFlowPredictor, error) {
// 配置gRPC连接参数:无加密、阻塞连接、1秒超时(避免连接耗时过长)
conn, err := grpc.Dial(
addr,
grpc.WithInsecure(), // 非加密连接(生产环境建议配置TLS)
grpc.WithBlock(), // 阻塞直到连接建立成功
grpc.WithTimeout(1*time.Second), // 连接超时时间
)
if err != nil {
return nil, fmt.Errorf("gRPC连接建立失败: %w", err)
}
// 创建TensorFlow Serving预测服务客户端
client := pb.NewPredictionServiceClient(conn)
return &TensorFlowPredictor{
client: client,
conn: conn,
}, nil
}
// Predict 单条样本预测:向TensorFlow Serving发起单条CTR预估请求
// ctx: 上下文(用于超时控制、链路追踪)
// features: 稀疏特征ID列表(对应模型输入"keys")
// denseFeatures: 密集特征列表(对应模型输入"dense")
// return: 单条样本的CTR预估概率,或错误信息
func (p *TensorFlowPredictor) Predict(
ctx context.Context,
features []int64,
denseFeatures []float32,
) (float32, error) {
// 1. 构造PredictRequest:指定模型信息、输入特征
req := &pb.PredictRequest{
// 模型规格:指定模型名、版本、签名(需与TensorFlow Serving配置一致)
ModelSpec: &pb.ModelSpec{
Name: "ctr", // 模型名(对应models.config中的"ctr")
Version: &wrappers.Int64Value{Value: 20241005}, // 模型版本(指定使用20241005版本)
SignatureName: "serving_default", // 签名名(导出模型时定义的默认签名)
},
// 输入特征:对应模型的两个输入"keys"(稀疏ID)和"dense"(密集特征)
Inputs: map[string]*tfFramework.TensorProto{
"keys": buildInt64TensorProto(features, 1), // 稀疏特征:batch_size=1,特征数=len(features)
"dense": buildFloat32TensorProto(denseFeatures, 1), // 密集特征:batch_size=1,特征数=len(denseFeatures)
},
}
// 2. 调用TensorFlow Serving的Predict接口
resp, err := p.client.Predict(ctx, req)
if err != nil {
return 0, fmt.Errorf("gRPC预估请求失败: %w", err)
}
// 3. 解析响应:提取"predictions"输出(需与模型导出时的输出名一致)
predOutput, ok := resp.Outputs["predictions"]
if !ok {
return 0, fmt.Errorf("响应中缺失'predictions'输出")
}
if len(predOutput.FloatVal) == 0 {
return 0, fmt.Errorf("'predictions'输出为空")
}
// 返回单条样本的预估概率(batch_size=1,取第一个值)
return predOutput.FloatVal[0], nil
}
// BatchPredict 批量样本预测:向TensorFlow Serving发起批量CTR预估请求(提升高并发场景效率)
// ctx: 上下文(用于超时控制、链路追踪)
// batchFeatures: 批量稀疏特征ID(二维切片:[batch_size][num_sparse_features])
// batchDense: 批量密集特征(二维切片:[batch_size][num_dense_features])
// return: 批量样本的CTR预估概率列表(顺序与输入一致),或错误信息
func (p *TensorFlowPredictor) BatchPredict(
ctx context.Context,
batchFeatures [][]int64,
batchDense [][]float32,
) ([]float32, error) {
// 基础校验:批量输入的样本数需一致
batchSize := len(batchFeatures)
if batchSize == 0 {
return nil, fmt.Errorf("批量样本数为空")
}
if len(batchDense) != batchSize {
return nil, fmt.Errorf("稀疏特征与密集特征样本数不匹配:%d vs %d", batchSize, len(batchDense))
}
// 校验所有样本的特征数一致(避免shape不匹配)
sparseFeatNum := len(batchFeatures[0])
denseFeatNum := len(batchDense[0])
for _, feat := range batchFeatures {
if len(feat) != sparseFeatNum {
return nil, fmt.Errorf("稀疏特征数不一致:期望%d,实际%d", sparseFeatNum, len(feat))
}
}
for _, dense := range batchDense {
if len(dense) != denseFeatNum {
return nil, fmt.Errorf("密集特征数不一致:期望%d,实际%d", denseFeatNum, len(dense))
}
}
// 1. 展平批量特征(TensorFlow Serving需要一维输入+shape描述)
flatSparseFeat := make([]int64, 0, batchSize*sparseFeatNum)
for _, feat := range batchFeatures {
flatSparseFeat = append(flatSparseFeat, feat...)
}
flatDenseFeat := make([]float32, 0, batchSize*denseFeatNum)
for _, dense := range batchDense {
flatDenseFeat = append(flatDenseFeat, dense...)
}
// 2. 构造批量PredictRequest
req := &pb.PredictRequest{
ModelSpec: &pb.ModelSpec{
Name: "ctr", // 模型名
SignatureName: "serving_default", // 默认签名(批量与单条共用)
// 批量预测可不指定版本(使用默认版本),也可显式指定如&wrappers.Int64Value{Value: 20241005}
},
Inputs: map[string]*tfFramework.TensorProto{
// 稀疏特征:shape=[batchSize, sparseFeatNum]
"keys": buildInt64TensorProto(flatSparseFeat, batchSize),
// 密集特征:shape=[batchSize, denseFeatNum]
"dense": buildFloat32TensorProto(flatDenseFeat, batchSize),
},
}
// 3. 调用批量预估接口
resp, err := p.client.Predict(ctx, req)
if err != nil {
return nil, fmt.Errorf("批量gRPC预估请求失败: %w", err)
}
// 4. 解析批量响应
predOutput, ok := resp.Outputs["predictions"]
if !ok {
return nil, fmt.Errorf("批量响应中缺失'predictions'输出")
}
if len(predOutput.FloatVal) != batchSize {
return nil, fmt.Errorf("预估结果数与样本数不匹配:%d vs %d", len(predOutput.FloatVal), batchSize)
}
// 返回批量预估结果(顺序与输入样本一致)
return predOutput.FloatVal, nil
}
// Close 关闭gRPC连接(释放资源,建议在服务退出时调用)
func (p *TensorFlowPredictor) Close() error {
if p.conn != nil {
return p.conn.Close()
}
return nil
}
// buildInt64TensorProto 构造int64类型的TensorProto(用于稀疏特征ID)
// data: 一维int64数据(展平后的特征)
// batchSize: 样本批次大小
func buildInt64TensorProto(data []int64, batchSize int) *tfFramework.TensorProto {
featNum := len(data) / batchSize // 单个样本的特征数
return &tfFramework.TensorProto{
Dtype: tfFramework.DataType_DT_INT64, // 数据类型:int64
// 张量形状:[batchSize, featNum]
TensorShape: &tfFramework.TensorShapeProto{
Dim: []*tfFramework.TensorShapeProto_Dim{
{Size: int64(batchSize)}, // 第一维度:批次大小
{Size: int64(featNum)}, // 第二维度:单个样本特征数
},
},
Int64Val: data, // 展平的int64特征数据
}
}
// buildFloat32TensorProto 构造float32类型的TensorProto(用于密集特征)
// data: 一维float32数据(展平后的特征)
// batchSize: 样本批次大小
func buildFloat32TensorProto(data []float32, batchSize int) *tfFramework.TensorProto {
featNum := len(data) / batchSize // 单个样本的特征数
return &tfFramework.TensorProto{
Dtype: tfFramework.DataType_DT_FLOAT, // 数据类型:float32
// 张量形状:[batchSize, featNum]
TensorShape: &tfFramework.TensorShapeProto{
Dim: []*tfFramework.TensorShapeProto_Dim{
{Size: int64(batchSize)}, // 第一维度:批次大小
{Size: int64(featNum)}, // 第二维度:单个样本特征数
},
},
FloatVal: data, // 展平的float32特征数据
}
}5.4 预估服务的高可用设计
在生产环境,高可用性至关重要。
5.4.1 服务架构设计

核心设计原则:
- 无状态服务:所有TF Serving实例无状态,可随意扩缩容
- 负载均衡:使用gRPC负载均衡,均匀分配请求
- 健康检查:定期检查服务状态,自动剔除故障节点
- 优雅降级:预估失败时,使用历史CTR/CVR兜底
5.5.3 缓存策略
// 特征缓存type FeatureCache struct { cache *lru.Cache
ttl time.Duration
}func (fc *FeatureCache) GetOrCompute( key string, computeFn func() ([]float32, error)) ([]float32, error) { // 查缓存 if val, ok := fc.cache.Get(key); ok { return val.([]float32), nil } // 计算特征 features, err := computeFn() if err != nil { return nil, err
} // 存缓存 fc.cache.Add(key, features) return features, nil}// 预估结果缓存type PredictionCache struct { cache *redis.Client
ttl time.Duration
}func (pc *PredictionCache) GetOrPredict( key string, predictFn func() (float32, error)) (float32, error) { // 查Redis缓存 val, err := pc.cache.Get(key).Float32() if err == nil { return val, nil } // 预估 prediction, err := predictFn() if err != nil { return 0, err
} // 存缓存(异步) go pc.cache.Set(key, prediction, pc.ttl) return prediction, nil}// 效果"""缓存命中率: 60%平均延迟下降: 40% (30ms → 18ms)QPS提升: 2倍
"""5.6 本章小结
🎯 核心要点
1. 分布式训练(Horovod)
- Ring-AllReduce:无中心瓶颈,近线性加速
- FP16压缩:通信量减半
- CPU绑定:避免进程竞争,性能提升25%
2. TensorFlow Serving部署
- 模型导出:SavedModel格式
- gRPC API:高性能通信
- 批处理:QPS提升40倍
3. 高可用设计
- 连接池:复用连接,降低延迟
- 超时降级:30ms超时 → 历史CTR兜底
- 模型热更新:零停机发布
4. 性能优化
- 批处理:QPS从1K → 40K
- 模型量化:FP16速度翻倍
- 缓存策略:延迟降低40%
💡 生产经验
# 部署Checklist✅ 模型文件 < 2GB(超过需要分片)
✅ 推理延迟 < 30ms (P99)
✅ QPS支持 > 100K✅ 错误率 < 0.1%✅ 缓存命中率 > 50%✅ 支持灰度发布
✅ 支持快速回滚
✅ 完善的监控告警🚀 下一章预告
在下一章《算法融入决策流程》中,我们将深入探讨:
- 预估结果如何转化为出价
- eCPM计算的核心逻辑
- 冷启动CTR的补偿机制
- 多成本类型的出价策略
第六章:算法融入决策流程
“算法的价值不在于预估得有多准,而在于能为业务带来多少收益。”
6.1 从预估到出价:算法驱动决策
预估只是第一步,如何将预估结果转化为出价决策,才是算法的真正价值所在。
6.1.1 完整的决策链路

6.1.2 核心决策公式
1. eCPM计算(千次展示期望收益)eCPM = pCTR × pCVR × conversion_value × 1000
2. 出价计算bid_price = f(eCPM, cost_type, bid_strategy)
3. 收益计算revenue = (won_price - cost) × impression_count6.2 eCPM计算的核心逻辑
eCPM(effective Cost Per Mille)是连接算法与业务的桥梁。
6.2.1 eCPM的本质
eCPM(Effective Cost Per Mille):每千次展示的期望收益,核心用于广告投放的收益预估与竞价决策
# 核心计算公式:eCPM = pCTR × pCVR × conversion_value × 1000
# 其中:
# - pCTR:预估点击率(Probability of Click),即广告被点击的概率
# - pCVR:预估转化率(Probability of Conversion),即点击后发生转化的概率
# - conversion_value:单次转化价值(单位:元),即每次转化能带来的收益
# - ×1000:将“单次展示收益”放大到“每千次展示收益”,符合行业统计习惯6.2.2 我们的eCPM实现
// 代码位置:rtb_model_server_go/internal/model_index/predict/base/bid_decision.go
func (b *BidDecision) getECPM(
camp算法gn *rtb_adinfo_types.RTBCamp算法gn,
strategy *rtb_adinfo_types.RTBStrategy,
creative *rtb_adinfo_types.RTBCreative,
req *rtb_types.RTBRequestInfo,
predictResult *common.PredictResult,
effectiveCtr int64) int64 {
// 1. 基础eCPM计算
var ecpm int64
switch strategy.CostType {
case enums.CostType_CT_CPM:
// CPM:需要CTR和CVR
ecpm = effectiveCtr * predictResult.PreCvr * strategy.InternalAcostLimit / 1000000
case enums.CostType_CT_CPC:
// CPC:只需要CVR
ecpm = predictResult.PreCvr * strategy.InternalAcostLimit / 1000000
case enums.CostType_CT_OCPC:
// OCPC:CTR和CVR都要
ecpm = effectiveCtr * predictResult.PreCvr * strategy.InternalAcostLimit / 1000000
}
// 2. 应用K值调整(广告主出价系数)
if strategy.K > 0 {
ecpm = ecpm * strategy.K / 100
}
// 3. 应用预算消耗比例调整
if camp算法gn.BudgetPacing > 0 {
ecpm = ecpm * camp算法gn.BudgetPacing / 100
}
return ecpm
}关键点解析:
#1. 成本类型决定eCPM计算方式
- **CPM(按展示计费)**
eCPM = pCTR × pCVR × cost_limit
原因:按展示付费,需考虑点击概率;点击后才可能转化,需考虑转化概率
- **CPC(按点击计费)**
eCPM = pCVR × cost_limit
原因:已发生点击,无需考虑pCTR;仅需考虑转化概率
- **OCPC(优化的CPC)**
eCPM = pCTR × pCVR × cost_limit
原因:按点击付费,但优化目标是转化;需同时考虑CTR和CVR
2. K值调整(广告主出价系数)
- K值 = 100:标准出价
- K值 > 100:提高出价(抢量)
- K值 < 100:降低出价(控成本)
- 例子:base_ecpm = 500元,K = 120 → adjusted_ecpm = 500 × 1.2 = 600元(提价20%)
3. 预算消耗比例调整
- 作用:控制预算消耗速度
- 场景:日预算10,000元,当前已消耗8,000元(80%),剩余时间6小时(25%)
- 策略:消耗过快需降速,设BudgetPacing = 50(降低50%)
- 计算:adjusted_ecpm = original_ecpm × 0.56.2.3 eCPM的调整策略
// getAdjustedECPM 基于多维度规则调整原始eCPM,输出最终竞价eCPM
// 参数说明:
// - campaign:广告计划信息(含预算、投放策略等)
// - strategy:出价策略配置(含应用K值、时段K值、地域K值等)
// - creative:广告创意信息(暂未在当前逻辑中使用,预留扩展)
// - req:RTB请求信息(含应用ID、城市编码、媒体质量分等)
// - predictResult:模型预测结果(暂未在当前逻辑中使用,预留扩展)
// - originalEcpm:基础eCPM(未经过多维度调整的初始值)
func (b *BidDecision) getAdjustedECPM(
campaign *rtb_adinfo_types.RTBCampaign, // 修正笔误:camp算法gn → campaign
strategy *rtb_adinfo_types.RTBStrategy,
creative *rtb_adinfo_types.RTBCreative,
req *rtb_types.RTBRequestInfo,
predictResult *common.PredictResult,
originalEcpm int64,
) int64 {
adjustedEcpm := originalEcpm // 初始化:以原始eCPM为基准
// 1. 应用维度K值调整(按请求的AppId差异化出价)
if strategy.AppKValue != nil && len(strategy.AppKValue) > 0 {
appK, exists := strategy.AppKValue[req.AppId] // 根据当前请求的AppId获取对应K值
if exists && appK > 0 {
adjustedEcpm = adjustedEcpm * appK / 100 // K值为百分比(如120=提价20%)
}
}
// 2. 时段维度K值调整(按当前小时差异化出价)
currentHour := time.Now().Hour() // 获取当前系统时间的小时数(0-23)
hourK, exists := strategy.HourKValue[currentHour] // 根据当前小时获取对应K值
if exists && hourK > 0 {
adjustedEcpm = adjustedEcpm * hourK / 100
}
// 3. 地域维度K值调整(按请求的城市编码差异化出价)
regionK, exists := strategy.RegionKValue[req.CityCode] // 根据请求的城市编码获取对应K值
if exists && regionK > 0 {
adjustedEcpm = adjustedEcpm * regionK / 100
}
// 4. 流量质量维度调整(按媒体质量分差异化出价)
if req.MediaQualityScore > 0 {
qualityFactor := float64(req.MediaQualityScore) / 100.0 // 质量分为百分比(如110=高质量流量)
adjustedEcpm = int64(float64(adjustedEcpm) * qualityFactor) // 按质量分比例调整eCPM
}
return adjustedEcpm // 返回多维度调整后的最终eCPM
}实际效果:
原始eCPM:500元
应用K值调整(AppK=120):
500 × 1.2 = 600元
时段调整(晚高峰HourK=150):
600 × 1.5 = 900元
地域调整(一线城市RegionK=130):
900 × 1.3 = 1170元
流量质量调整(QualityScore=80):
1170 × 0.8 = 936元
最终eCPM:936元(相比原始提升87%)6.3 多成本类型的出价策略
不同的成本类型,出价策略完全不同。
6.3.1 CPM出价(按展示付费)
// 定义历史数据类型(根据实际业务场景补充字段,此处为示例)
type HistoricalData struct {
// 示例字段:历史eCPM分布、竞胜记录等
PastEcpmDist []int64
WinRecords []bool
}
// calculateCpmBid CPM出价策略:基于多维度动态计算最终出价
// 参数说明:
// - ecpm:已通过多维度调整后的目标eCPM(核心输入)
// - pCtr:预估点击率(预留:后续可用于出价精细化校准)
// - pCvr:预估转化率(预留:后续可用于出价精细化校准)
// - costLimit:广告计划成本上限(预留:后续可用于出价上限控制)
// - historicalData:历史竞价数据(用于预估竞胜率)
// - req:RTB请求信息(用于获取当前请求的竞争环境)
func (b *BidDecision) calculateCpmBid(
ecpm int64,
pCtr int64, // 预留:预估点击率(单位:万分数/百万分数,如500=5%)
pCvr int64, // 预留:预估转化率(单位:万分数/百万分数,如100=1%)
costLimit int64, // 预留:单展示成本上限(避免超成本)
historicalData HistoricalData, // 历史竞价数据:用于竞胜率预估
req *rtb_types.RTBRequestInfo, // RTB请求信息:用于判断竞争环境
) int64 {
var bidPrice int64
// 方案1:基础策略 - 基于目标eCPM直接出价(简单直接,无额外计算)
bidPrice = ecpm
// 备注:此方案适合竞争环境稳定、对出价精度要求不高的场景
// 方案2:优化策略1 - 基于竞胜率动态调整(核心推荐:平衡竞胜与成本)
winRate := b.estimateWinRate(ecpm, historicalData) // 基于历史数据预估当前eCPM的竞胜率
if winRate < 0.5 { // 竞胜率低于50%:提价以提升竞胜概率(提价20%,可根据业务调整比例)
bidPrice = int64(float64(bidPrice) * 1.2)
}
// 备注:若竞胜率过高(如>80%),可补充降价逻辑(如*0.9),避免过度出价
// 方案3:优化策略2 - 基于实时竞争环境调整(进一步精细化:匹配当前流量竞争强度)
competitionLevel := b.getCompetitionLevel(req) // 基于请求信息判断竞争强度(高/中/低)
switch competitionLevel {
case "high": // 高竞争:流量抢手,适当提价30%以提升竞争力
bidPrice = int64(float64(bidPrice) * 1.3)
case "medium": // 中竞争:竞争适中,维持当前出价
bidPrice = bidPrice
case "low": // 低竞争:流量充裕,降价20%以控制成本
bidPrice = int64(float64(bidPrice) * 0.8)
}
// (可选)补充成本控制:确保最终出价不超过成本上限(预留逻辑)
if costLimit > 0 && bidPrice > costLimit {
bidPrice = costLimit
}
return bidPrice // 返回最终CPM出价
}
// (补充函数声明:需在BidDecision结构体中实现,此处为逻辑关联)
// estimateWinRate 基于历史数据预估当前eCPM的竞胜率(0~1)
func (b *BidDecision) estimateWinRate(ecpm int64, historicalData HistoricalData) float64 {
// 实际逻辑:基于历史eCPM分布、过往竞胜记录计算,此处为占位
// 示例逻辑:若当前ecpm高于历史70%的eCPM,返回0.6;否则返回0.4
return 0.5 // 占位返回,需替换为实际计算逻辑
}
// getCompetitionLevel 基于RTB请求信息判断当前流量的竞争强度(high/medium/low)
func (b *BidDecision) getCompetitionLevel(req *rtb_types.RTBRequestInfo) string {
// 实际逻辑:基于请求的媒体类型、地域、时段等维度判断,此处为占位
return "medium" // 占位返回,需替换为实际判断逻辑
}CPM出价的挑战:
问题:出价即成本
CPM计费:
- 出价100元 → 中标 → 支付100元
- 即使用户不点击,也要付费
风险:
- CTR预估偏高 → 出价过高 → 成本浪费
- CTR预估偏低 → 出价过低 → 流失流量
解决方案:
1. 提升CTR预估精度(最根本)
2. 使用冷启动CTR兜底(不在拓展因为业界逐渐淘汰
3. 动态调整出价系数6.3.2 CPC出价(按点击付费)
// CPC出价策略:基于预估转化率、转化价值和利润率计算单次点击出价
func (b *BidDecision) calculateCpcBid(
pCvr int64, // 预估转化率(单位:百万分数,如100000=10%,需除以1000000转为小数)
conversionValue int64 // 单次转化价值(单位:元,即每次转化能带来的业务收益)
) int64 {
// CPC出价核心公式:bid_cpc = 预估转化率 × 单次转化价值 × 利润率
// 利润率用于保留利润空间,避免出价过高导致亏损
profitMargin := 0.8 // 设定利润率为80%(即保留20%利润,可根据业务目标调整)
// 计算逻辑:
// 1. 将pCvr(百万分数)转为小数(如pCvr=100000 → 100000/1000000=0.10)
// 2. 乘以单次转化价值和利润率,得到单次点击的最高可接受出价
bidPrice := int64(
float64(pCvr) / 1000000 * // pCvr转为小数形式
float64(conversionValue) * // 单次转化价值
profitMargin // 利润率(控制利润空间)
)
// 示例计算说明(帮助理解公式应用):
// 若 pCVR = 100000(对应10%)、conversion_value = 100元、profit_margin = 0.8
// 则 bid_cpc = (100000/1000000) × 100 × 0.8 = 0.10 × 100 × 0.8 = 8元/点击
// 含义:单次点击出价8元时,在当前转化预期下可保留20%利润
return bidPrice // 返回最终CPC出价(单位:元)
}CPC出价的优势:
优势:
按点击付费,风险小
不需要准确的CTR预估
只需要CVR预估
实际案例:
某电商广告主:
- CPM模式:ROI = 1.2(CTR预估不准)
- CPC模式:ROI = 1.8(只需CVR预估)
提升50%6.3.3 OCPC出价(优化的CPC)
// OCPC出价策略:按CPC付费,核心优化目标为CPA(单次转化成本),确保转化成本接近目标值
func (b *BidDecision) calculateOcpcBid(
pCtr int64, // 预估点击率(单位:百万分数,如100000=10%,需结合业务单位转换)
pCvr int64, // 预估转化率(单位:百万分数,如100000=10%)
conversionValue int64, // 单次转化价值(单位:元,可选,原文未直接使用,保留参数)
targetCpa int64 // 目标CPA(单位:元/转化,即期望的单次转化成本上限)
) int64 {
// OCPC核心思想:
// 1. 付费方式:按点击(CPC)付费,避免按转化(CPA)付费的高风险
// 2. 优化目标:通过动态调整CPC出价,使实际转化成本接近目标CPA(targetCpa)
// 步骤1:计算当前预期的转化成本(期望CPA)
expectedCpa := calculateExpectedCpa(pCtr, pCvr, conversionValue)
// 步骤2:对比期望CPA与目标CPA,动态调整出价
if expectedCpa > targetCpa {
// 情况1:期望CPA高于目标CPA → 需降低出价,控制转化成本
adjustFactor := float64(targetCpa) / float64(expectedCpa) // 调整系数(<1,降低出价)
baseBid := calculateBaseBid(pCtr, pCvr, conversionValue) // 计算基础CPC出价(未调整前)
return int64(float64(baseBid) * adjustFactor) // 返回调整后出价
}
// 情况2:期望CPA≤目标CPA → 无需调整,使用基础出价
return calculateBaseBid(pCtr, pCvr, conversionValue)
}
// calculateExpectedCpa 计算期望CPA(单次转化成本):基于点击成本和预估转化率
// 核心公式:期望CPA = 点击成本 / 预估转化率(pCvr)
func calculateExpectedCpa(
pCtr int64, // 预估点击率(原文未直接使用,保留参数以匹配调用场景)
pCvr int64, // 预估转化率(单位:百万分数,如100000=10%,需除以1000000转为小数)
conversionValue int64 // 单次转化价值(原文未直接使用,保留参数以匹配调用场景)
) int64 {
// 假设点击成本:10元(统一单位为百万分数,即10×1000000,避免浮点数精度问题)
clickCost := int64(10 * 1000000)
// 计算逻辑:因pCvr为百万分数,需通过乘法逆运算转换(避免直接除法的浮点数误差)
// 示例:若pCvr=100000(10%),则 expectedCpa = (10×1000000) × 1000000 / 100000 = 100×1000000(即100元)
expectedCpa := clickCost * 1000000 / pCvr
// 示例说明:
// 若pCVR=0.10(10%)、点击成本=10元 → 期望CPA = 10元 / 0.10 = 100元/转化
// 含义:当前点击成本下,每获得1次转化的预期成本为100元
return expectedCpa
}
// calculateBaseBid 计算OCPC基础CPC出价(原文未实现,保留函数调用以确保逻辑完整性)
// 核心逻辑:通常基于pCtr、pCvr、转化价值等计算合理的基础点击出价
func calculateBaseBid(pCtr, pCvr, conversionValue int64) int64 {
// 实际业务中需补充实现,示例逻辑(参考CPC出价思路):
// profitMargin := 0.8 // 利润率
// return int64(float64(pCvr)/1000000 * float64(conversionValue) * profitMargin)
return 0 // 占位返回,需替换为实际业务逻辑
}OCPC的核心价值:
场景:
广告主目标:CPA < 50元(每次转化成本<50元)
传统CPC:
- 出价10元/点击
- 实际CVR=8%
- 实际CPA=10/0.08=125元 超出目标
OCPC:
- 预估CVR=8%
- 目标CPA=50元
- 智能出价=50×0.08=4元/点击
- 实际CPA≈50元 符合目标
优势:
自动控制CPA
最大化转化量
广告主省心第七章:效果评估与优化
“没有评估就没有优化,没有优化就没有进步。”
7.1 效果评估的双重视角
在广告领域,效果评估需要从两个维度来看:离线指标和在线效果。
7.1.1 离线 vs 在线的鸿沟

关键矛盾:
# 常见的离线在线不一致案例
## 案例1:离线AUC提升,在线CTR下降
### 离线表现(历史数据验证)
- 旧模型AUC:0.75
- 新模型AUC:0.78(✅ 提升3个点,离线指标优化)
### 在线表现(实时流量验证)
- 旧模型CTR:5.0%
- 新模型CTR:4.8%(❌ 下降0.2个点,在线效果不及预期)
### 核心原因
- 数据时效性差异:离线训练/验证用的是2周前的历史数据,在线面对的是实时变化的用户行为
- 模型过拟合:新模型过度适配了历史数据的分布特征,无法泛化到实时流量的新分布
## 案例2:离线指标持平,在线收益提升
### 离线表现(历史数据验证)
- 旧模型AUC:0.76
- 新模型AUC:0.76(≈ 持平,离线指标无明显变化)
### 在线表现(实时流量验证)
- 旧模型日收益(Revenue):10,000元
- 新模型日收益(Revenue):12,000元(✅ 提升20%,在线业务价值显著优化)
### 核心原因
- AUC局限性:AUC仅衡量模型的“排序能力”(判断正样本是否排在负样本前),不关注预估值的“绝对值准确性”
- 预估值校准更优:新模型的预估值(如pCTR/pCVR)更贴近真实业务场景的概率分布
- 出价策略适配:准确的预估值让出价决策更精准,最终提升投入产出比(ROI)和整体收益7.2 离线指标:模型质量的度量
离线指标是快速迭代的基础,但要正确理解和使用。
7.2.1 核心离线指标
AUC (Area Under Curve)
from sklearn.metrics import roc_auc_score
def evaluate_auc(y_true, y_pred):
"""
AUC(ROC曲线下面积):衡量二分类模型的排序能力
取值范围:0.5 ~ 1.0
- 0.5:模型无排序能力(等同于随机猜测)
- 0.7:具备基础排序能力(可用级别)
- 0.8:排序能力良好(优秀级别)
- 0.9:排序能力优异(顶尖级别)
优点:
- 不受分类阈值影响(无论阈值如何调整,AUC反映的是整体排序能力)
- 核心衡量模型对正/负样本的区分排序能力
缺点:
- 不关注预估值的绝对值(仅看相对排序,无法判断预估值是否贴近真实概率)
- 对样本类别不均衡场景不敏感(可能掩盖少数类预测效果差的问题)
"""
return roc_auc_score(y_true, y_pred)
# 实际使用示例:计算具体样本的AUC
if __name__ == "__main__":
# 真实标签(0=负样本,1=正样本)
y_true = [0, 0, 1, 1, 0, 1, 0, 1, 1, 0]
# 模型预估值(对每个样本的正样本概率预测)
y_pred = [0.1, 0.2, 0.7, 0.8, 0.3, 0.9, 0.15, 0.6, 0.85, 0.25]
# 计算AUC
auc_result = evaluate_auc(y_true, y_pred)
# 打印结果(预期输出:AUC: 0.9167)
print(f"AUC: {auc_result:.4f}")
# AUC的局限性:仅关注排序,忽略预估值绝对值
案例对比:
模型A:
- 预估值:[0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.10]
- 真实值:[0, 0, 0, 0, 0, 1, 1, 1, 1, 1 ]
- AUC计算结果:1.0(完美排序)
模型B:
- 预估值:[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0 ]
- 真实值:[0, 0, 0, 0, 0, 1, 1, 1, 1, 1 ]
- AUC计算结果:1.0(完美排序)
核心问题:
1. 两个模型AUC完全相同(均为1.0),但预估值绝对值差异极大
2. 模型A预估值普遍偏低(0.01~0.10):实际业务中会导致出价偏低,错失优质流量
3. 模型B预估值合理(0.1~1.0):预估值贴近真实概率,出价决策更准确
4. AUC无法区分这种“排序相同但绝对值不合理”的差异,存在业务误导风险LogLoss (对数损失)
from sklearn.metrics import log_loss
def evaluate_logloss(y_true, y_pred):
LogLoss(对数损失):核心衡量模型预估值与真实标签的校准程度(即预估值绝对值的准确性)
取值范围:0 ~ ∞(数值越小,预估值校准效果越好)
- 0:预估值与真实值完全一致(完美预估)
- 0.1~0.3:预估值校准效果良好(业务可用)
- >0.5:预估值校准效果较差(需优化模型)
优点:
- 关注预估值的绝对值准确性(而非仅排序,弥补AUC的局限性)
- 对错误的极端预估(如将真实0样本预估为0.9)惩罚力度大,倒逼模型输出合理概率
缺点:
- 受样本类别不均衡影响显著(少数类样本的预测误差对整体LogLoss影响更大)
- 结果解读不直观(需结合业务场景对比,无法直接对应业务指标)
return log_loss(y_true, y_pred)
# 实际使用示例:对比不同预估值的LogLoss差异
if __name__ == "__main__":
# 真实标签(0=负样本,1=正样本)
y_true = [0, 0, 1, 1, 0, 1, 0, 1, 1, 0]
# 校准效果好的预估值(贴近真实概率分布)
y_pred_good = [0.1, 0.2, 0.7, 0.8, 0.3, 0.9, 0.15, 0.6, 0.85, 0.25]
# 校准效果差的预估值(与真实概率分布偏差大)
y_pred_bad = [0.9, 0.8, 0.3, 0.2, 0.7, 0.1, 0.85, 0.4, 0.15, 0.75]
# 计算两种预估值的LogLoss
logloss_good = evaluate_logloss(y_true, y_pred_good)
logloss_bad = evaluate_logloss(y_true, y_pred_bad)
# 打印结果(预期输出:LogLoss (good): 0.3567;LogLoss (bad): 1.8234)
print(f"LogLoss (good): {logloss_good:.4f}") # 校准好的预估值,LogLoss低
print(f"LogLoss (bad): {logloss_bad:.4f}") # 校准差的预估值,LogLoss高
# LogLoss在业务中的核心价值(以出价系统为例)
对于广告出价、推荐流量分配等依赖预估值决策的系统:
- LogLoss低 → 模型预估值与真实情况校准度高 → 基于预估值的出价更合理,资源分配更高效
- LogLoss高 → 模型预估值与真实情况偏差大 → 出价决策失误,导致成本浪费或流量流失
具体例子(CTR预估与出价关联):
假设某广告位真实CTR = 5%(即每100次展示约5次点击)
1. 预估CTR = 5% → LogLoss低 → 出价准确,既不浪费成本也不流失流量
2. 预估CTR = 10% → LogLoss高 → 基于高估的CTR出价过高,导致点击成本超支(浪费)
3. 预估CTR = 2% → LogLoss高 → 基于低估的CTR出价过低,无法竞得优质流量(流失)
结论:LogLoss能有效惩罚预估值与真实值的偏差,是衡量“预估值能否指导业务决策”的关键指标GAUC (Group AUC)
from sklearn.metrics import roc_auc_score
from collections import defaultdict
def calculate_gauc(y_true, y_pred, group_ids):
GAUC(Group AUC):按指定分组维度计算每组AUC,再按组内样本数加权平均,消除组间偏差
核心应用场景:
- 按用户分组(user_id):评估模型对不同活跃度用户的个性化推荐/广告效果(避免重度用户主导结果)
- 按广告分组(ad_id):评估新老广告的效果差异(避免高曝光广告掩盖低曝光广告表现)
- 按时间分组(time_window):评估模型在不同时段的稳定性(避免高峰时段数据主导)
优点:
- 平衡组间权重:避免样本量极大的组过度影响整体指标,公平反映各小组效果
- 聚焦细分场景:可针对性分析特定分组的模型表现,定位细分场景问题
注意:
- 每组需至少包含2条样本,且同时存在正、负样本(否则跳过该组,避免无效计算)
# 1. 按分组ID(如user_id、ad_id)聚合样本:key=分组ID,value=[(真实标签, 预估值), ...]
group_sample_map = defaultdict(list)
for idx, group_id in enumerate(group_ids):
group_sample_map[group_id].append((y_true[idx], y_pred[idx]))
# 2. 计算每组AUC及组权重(组权重=组内样本数)
group_auc_list = [] # 存储每组有效AUC
group_weight_list = [] # 存储每组样本数(作为权重)
for group_id, sample_list in group_sample_map.items():
# 过滤:组内样本数<2 → 无法计算AUC,跳过
if len(sample_list) < 2:
continue
# 提取组内真实标签和预估值
y_true_group = [sample[0] for sample in sample_list]
y_pred_group = [sample[1] for sample in sample_list]
# 过滤:组内无正样本或无负样本 → AUC无意义,跳过
has_pos = sum(y_true_group) > 0
has_neg = sum(y_true_group) < len(y_true_group)
if not (has_pos and has_neg):
continue
# 计算当前组AUC
group_auc = roc_auc_score(y_true_group, y_pred_group)
group_auc_list.append(group_auc)
# 记录组权重(组内样本数)
group_weight_list.append(len(sample_list))
# 3. 加权平均计算GAUC(总权重=所有有效组样本数之和)
total_weight = sum(group_weight_list)
if total_weight == 0:
raise ValueError("无有效分组(所有分组样本数<2或无正负样本),无法计算GAUC")
gauc = sum(auc * weight for auc, weight in zip(group_auc_list, group_weight_list)) / total_weight
return gauc
# 实际使用示例:按用户分组计算GAUC
if __name__ == "__main__":
# 输入数据:10条样本,分属3个用户(user_ids=[1,1,1,1,2,2,2,2,3,3])
y_true = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] # 真实标签(0=未点击,1=点击)
y_pred = [0.2, 0.8, 0.1, 0.9, 0.3, 0.7, 0.15, 0.85, 0.25, 0.75] # 模型预估值
user_ids = [1, 1, 1, 1, 2, 2, 2, 2, 3, 3] # 分组维度:用户ID(3个用户)
# 计算GAUC
gauc_result = calculate_gauc(y_true, y_pred, user_ids)
# 打印结果(预期:各组AUC分别计算后加权,输出GAUC值)
print(f"GAUC: {gauc_result:.4f}")
# GAUC与普通AUC的核心差异对比(以“用户分组”场景为例)
场景设定:两个用户的广告点击行为差异显著
- 用户A(重度用户):曝光1000次,点击100次(CTR=10%),样本占比99%
- 用户B(轻度用户):曝光10次,点击0次(CTR=0%),样本占比1%
1. 普通AUC的问题:权重失衡
- 总样本数:1010条(用户A 1000条 + 用户B 10条)
- 权重分配:用户A占99%,用户B占1%
- 结果偏向:普通AUC基本只反映用户A的效果,完全掩盖用户B的表现
2. GAUC的优势:公平加权
- 分组逻辑:按用户ID分为2组(用户A、用户B)
- 每组AUC:用户A AUC=0.85,用户B AUC=0.70
- 权重分配:按“组”加权(而非样本数),两组各占50%(或按业务需求调整权重逻辑)
- 最终GAUC:(0.85×1 + 0.70×1) / 2 = 0.775
- 效果:公平反映两个用户的模型表现,避免“大样本组垄断指标”7.2.2 离线评估框架
import numpy as np
from sklearn.metrics import roc_auc_score, log_loss
from sklearn.calibration import calibration_curve
class OfflineEvaluator:
"""
离线评估框架:整合多维度指标,全面评估模型效果(含排序、校准、业务价值等)
"""
def __init__(self, model):
self.model = model # 待评估的模型(需实现 predict 方法,输入特征输出预估值)
def evaluate(self, test_data):
"""
完整离线评估流程:从预测到多指标计算,返回综合评估结果
test_data: 测试数据集(字典格式),需包含 'labels'(真实标签)、'features'(模型输入特征)、
'user_id'(用户ID,用于分组GAUC)、'ad_id'(广告ID,用于分组GAUC)
"""
# 1. 模型预测:获取测试集的预估值
y_true = test_data['labels'] # 真实标签(0/1)
y_pred = self.model.predict(test_data['features']) # 模型预估值(概率)
# 2. 基础排序与校准指标
metrics = {}
# AUC:整体排序能力
metrics['auc'] = roc_auc_score(y_true, y_pred)
# LogLoss:整体预估值校准度
metrics['logloss'] = log_loss(y_true, y_pred)
# 3. 分组GAUC:消除组间偏差,评估细分场景效果
# 按用户分组GAUC(评估个性化效果)
user_ids = test_data['user_id']
metrics['gauc_user'] = calculate_gauc(y_true, y_pred, user_ids)
# 按广告分组GAUC(评估不同广告的模型适配性)
ad_ids = test_data['ad_id']
metrics['gauc_ad'] = calculate_gauc(y_true, y_pred, ad_ids)
# 4. 校准指标:量化预估值与真实值的一致性(ECE)
metrics['calibration'] = self.calculate_calibration(y_true, y_pred)
# 5. 覆盖率指标:评估模型对不同阈值流量的覆盖能力
metrics['coverage'] = self.calculate_coverage(y_pred)
# 6. 业务价值模拟:预测模型在线上的实际业务效果
metrics['simulated_ctr'] = self.simulate_ctr(y_true, y_pred)
metrics['simulated_revenue'] = self.simulate_revenue(y_true, y_pred)
return metrics
def calculate_calibration(self, y_true, y_pred, n_bins=10):
计算模型校准度:通过分箱比较预估值均值与真实正样本比例,输出校准误差(ECE)
n_bins: 分箱数量(默认10,将预估值按区间分为10组)
返回:包含ECE、各组真实正样本比例、各组预估值均值的字典
# 获取每组的真实正样本比例(fraction_of_positives)和预估值均值(mean_predicted_value)
fraction_of_positives, mean_predicted_value = calibration_curve(
y_true, y_pred, n_bins=n_bins
)
# 计算期望校准误差(ECE):各组误差的平均值(衡量整体校准偏差)
ece = np.mean(np.abs(fraction_of_positives - mean_predicted_value))
return {
'ece': ece,
'fraction_of_positives': fraction_of_positives.tolist(), # 各组真实正样本比例
'mean_predicted_value': mean_predicted_value.tolist() # 各组预估值均值
}
def calculate_coverage(self, y_pred, thresholds=[0.01, 0.05, 0.1]):
计算流量覆盖率:统计预估值大于等于指定阈值的样本占比(反映模型对高价值流量的筛选能力)
thresholds: 待评估的预估值阈值列表(默认[0.01, 0.05, 0.1])
返回:各阈值对应的覆盖率字典
coverage = {}
for threshold in thresholds:
# 覆盖率 = 预估值≥阈值的样本数 / 总样本数
coverage[f'coverage_{threshold}'] = np.mean(y_pred >= threshold)
return coverage
def simulate_ctr(self, y_true, y_pred, top_n=1000):
模拟线上CTR:假设只投放预估值Top N的样本,计算这些样本的真实CTR(评估模型的高价值流量筛选能力)
top_n: 模拟投放的Top N样本数(默认1000)
返回:Top N样本的真实CTR
# 按预估值降序排序,取前Top N样本的索引
sorted_indices = np.argsort(y_pred)[::-1][:top_n]
# 计算Top N样本的真实CTR(真实正样本数 / Top N样本数)
simulated_ctr = np.mean(y_true[sorted_indices])
return simulated_ctr
def simulate_revenue(self, y_true, y_pred, budget=10000):
模拟线上收益:在给定预算约束下,按预估值排序投放,计算总收益、花费、转化数及ROI(评估业务价值)
budget: 模拟投放的总预算(默认10000)
返回:包含总收益、总花费、转化数、ROI的字典
# 按预估值降序排序(优先投放高预估值样本)
sorted_indices = np.argsort(y_pred)[::-1]
spent = 0 # 累计花费
conversions = 0 # 累计转化数
# 模拟按预估值排序投放,直到预算用尽
for idx in sorted_indices:
# 简化CPM出价逻辑:预估值×100作为CPM价格(单位:元/千次展示,此处简化为单次展示价格)
cpm = y_pred[idx] * 100
# 若当前花费+本次CPM超过预算,停止投放
if spent + cpm > budget:
break
# 累计花费
spent += cpm
# 若该样本为真实正样本(转化),累计转化数
if y_true[idx] == 1:
conversions += 1
# 计算收益与ROI(假设单次转化价值100元,ROI=收益/花费)
revenue = conversions * 100 # 总收益 = 转化数 × 单次转化价值
roi = revenue / spent if spent > 0 else 0 # 避免除以0
return {
'revenue': revenue, # 总收益(元)
'spent': spent, # 总花费(元)
'conversions': conversions, # 总转化数
'roi': roi # 投资回报率(收益/花费)
}
# 使用示例:初始化评估器并执行离线评估
if __name__ == "__main__":
# 初始化评估器
evaluator = OfflineEvaluator(model)
# 执行评估,获取指标结果
metrics = evaluator.evaluate(test_data)
# 打印离线评估结果
print("离线评估结果:")
print(f"AUC: {metrics['auc']:.4f}")
print(f"LogLoss: {metrics['logloss']:.4f}")
print(f"GAUC(用户): {metrics['gauc_user']:.4f}")
print(f"GAUC(广告): {metrics['gauc_ad']:.4f}")
print(f"校准误差(ECE): {metrics['calibration']['ece']:.4f}")
print(f"模拟CTR: {metrics['simulated_ctr']:.4f}")
print(f"模拟ROI: {metrics['simulated_revenue']['roi']:.2f}")
# 示例离线评估结果
离线评估结果:
AUC: 0.7823
LogLoss: 0.2456
GAUC(用户): 0.7654
GAUC(广告): 0.7421
校准误差(ECE): 0.0234
模拟CTR: 0.0876
模拟ROI: 1.857.3 在线指标:业务价值的度量
离线指标再好,最终要看在线业务效果。
7.3.1 核心在线指标
class OnlineMetrics:
"""
在线指标计算工具类:提供广告投放核心业务指标的计算方法,基于实时曝光、点击、转化等数据
"""
@staticmethod
def calculate_ctr(impressions, clicks):
"""
CTR (Click-Through Rate):点击率 - 衡量广告吸引用户点击的能力
公式:CTR = 点击数 / 曝光数
目标:数值越高越好(表明广告吸引力强)
典型行业值参考:
- 搜索广告:3-8%
- 信息流广告:0.5-2%
- 横幅广告:0.1-0.5%
Args:
impressions: 曝光数(int,≥0)
clicks: 点击数(int,≥0,且≤曝光数)
Returns:
float: CTR值(0~1),曝光数为0时返回0
"""
if impressions == 0:
return 0.0
return clicks / impressions
@staticmethod
def calculate_cvr(clicks, conversions):
"""
CVR (Conversion Rate):转化率 - 衡量点击后用户完成目标行为的能力
公式:CVR = 转化数 / 点击数
目标:数值越高越好(表明广告引导转化效果好)
典型行业值参考:
- 电商行业:5-15%
- 游戏行业:10-30%
- 金融行业:1-5%
Args:
clicks: 点击数(int,≥0)
conversions: 转化数(int,≥0,且≤点击数)
Returns:
float: CVR值(0~1),点击数为0时返回0
"""
if clicks == 0:
return 0.0
return conversions / clicks
@staticmethod
def calculate_cpm(cost, impressions):
"""
CPM (Cost Per Mille):千次展示成本 - 衡量每1000次曝光的花费
公式:CPM = 成本 / 曝光数 × 1000
目标:数值越低越好(对广告主而言,成本控制更优)
Args:
cost: 总花费(float,≥0,单位:元)
impressions: 曝光数(int,≥0)
Returns:
float: CPM值(单位:元/千次曝光),曝光数为0时返回0
"""
if impressions == 0:
return 0.0
return (cost / impressions) * 1000
@staticmethod
def calculate_cpc(cost, clicks):
"""
CPC (Cost Per Click):单次点击成本 - 衡量每一次点击的花费
公式:CPC = 成本 / 点击数
目标:数值越低越好(对广告主而言,点击成本更低)
Args:
cost: 总花费(float,≥0,单位:元)
clicks: 点击数(int,≥0)
Returns:
float: CPC值(单位:元/次点击),点击数为0时返回0
"""
if clicks == 0:
return 0.0
return cost / clicks
@staticmethod
def calculate_cpa(cost, conversions):
"""
CPA (Cost Per Action):单次转化成本 - 衡量每一次有效转化的花费(核心成本指标)
公式:CPA = 成本 / 转化数
目标:数值越低越好(直接影响广告主的投入产出比)
关键意义:若CPA高于单次转化价值,广告将亏损;反之则盈利
Args:
cost: 总花费(float,≥0,单位:元)
conversions: 转化数(int,≥0)
Returns:
float: CPA值(单位:元/次转化),转化数为0时返回无穷大(表示无有效转化)
"""
if conversions == 0:
return float('inf')
return cost / conversions
@staticmethod
def calculate_roi(revenue, cost):
"""
ROI (Return On Investment):投资回报率 - 衡量广告投放的盈利能力(核心业务指标)
公式:ROI = 总收益 / 总花费
目标:ROI > 1(表示盈利),数值越高越好
典型值判断:
- 优秀:ROI > 2(收益是成本的2倍以上)
- 良好:1.5 ≤ ROI ≤ 2(收益覆盖成本且有合理利润)
- 盈亏平衡:ROI = 1(收益刚好覆盖成本)
- 亏损:ROI < 1(收益不足以覆盖成本)
Args:
revenue: 总收益(float,≥0,单位:元,即所有转化带来的总价值)
cost: 总花费(float,≥0,单位:元)
Returns:
float: ROI值,花费为0时返回0(表示无投入)
"""
if cost == 0:
return 0.0
return revenue / cost
# 实际使用示例:基于真实投放数据计算在线指标
if __name__ == "__main__":
# 模拟广告投放数据(100万曝光场景)
impressions = 1000000 # 总曝光数:100万次
clicks = 50000 # 总点击数:5万次
conversions = 5000 # 总转化数:5000次
cost = 100000.0 # 总花费:10万元
revenue = 180000.0 # 总收益:18万元(转化带来的总价值)
# 计算核心在线指标
online_metrics = {
'CTR': OnlineMetrics.calculate_ctr(impressions, clicks),
'CVR': OnlineMetrics.calculate_cvr(clicks, conversions),
'CPM': OnlineMetrics.calculate_cpm(cost, impressions),
'CPC': OnlineMetrics.calculate_cpc(cost, clicks),
'CPA': OnlineMetrics.calculate_cpa(cost, conversions),
'ROI': OnlineMetrics.calculate_roi(revenue, cost),
}
# 打印指标结果(按指标类型适配显示格式:百分比/货币)
print("在线指标计算结果:")
for metric_name, metric_value in online_metrics.items():
if metric_name in ['CTR', 'CVR', 'ROI']:
# CTR/CVR/ROI 按百分比显示(保留2位小数)
print(f"{metric_name}: {metric_value:.2%}")
else:
# CPM/CPC/CPA 按货币格式显示(保留2位小数,单位:元)
print(f"{metric_name}: ¥{metric_value:.2f}")
# 示例输出结果
在线指标计算结果:
CTR: 5.00%
CVR: 10.00%
CPM: ¥100.00
CPC: ¥2.00
CPA: ¥20.00
ROI: 180.00%(即1.8倍)
7.3.2 指标的业务含义
class StakeholderMetrics:
"""
广告业务中不同干系人(广告主、媒体方、平台方)的核心关注指标与决策依据
核心逻辑:不同角色目标不同,指标优先级存在差异,需聚焦核心诉求
"""
@staticmethod
def advertiser_metrics():
"""
广告主(投放方):核心诉求是“控制成本、提升盈利”,关注投入产出比
返回:广告主关注的指标分类及决策依据
"""
return {
'核心指标(直接影响盈利)': {
'ROI(投资回报率)': '最重要指标,衡量整体盈利水平',
'CPA(单次转化成本)': '控制转化端成本,直接关联利润',
'CVR(转化率)': '反映点击到转化的效率,影响CPA'
},
'次要指标(辅助优化)': {
'CTR(点击率)': '反映广告吸引力,影响曝光到点击的效率',
'CPC(单次点击成本)': '控制点击端成本,间接影响CPA'
},
'决策依据(行动指南)': """
- ROI > 1.5:盈利良好,可增加投放预算、扩大规模
- ROI = 1.0~1.5:盈亏平衡或微利,维持现有投放策略
- ROI < 1.0:亏损状态,需减少预算、优化策略或暂停投放
"""
}
@staticmethod
def media_metrics():
"""
媒体方(流量方):核心诉求是“提升流量价值、增加收益”,关注流量变现效率
返回:媒体方关注的指标分类及决策依据
"""
return {
'核心指标(直接影响收益)': {
'Revenue(总收益)': '媒体方核心目标,衡量整体变现能力',
'Fill Rate(填充率)': '反映流量被广告覆盖的比例,影响收益规模',
'eCPM(千次展示收益)': '衡量单位流量价值,反映变现效率'
},
'次要指标(影响长期收益)': {
'CTR(点击率)': '间接反映广告与用户匹配度,过低可能影响用户体验'
},
'决策依据(行动指南)': """
- Revenue持续增长:现有广告合作模式健康,可拓展优质广告主
- Fill Rate低(<80%):流量未充分利用,需拓展广告源、优化匹配效率
- CTR过低(<0.5%):广告质量差或匹配度低,需优化广告筛选机制
"""
}
@staticmethod
def platform_metrics():
"""
平台方(撮合方):核心诉求是“平衡三方利益、实现长期增长”,关注生态健康度
返回:平台方关注的指标分类及决策依据
"""
return {
'核心指标(直接影响平台规模)': {
'GMV(交易总额)': '平台撮合的广告总花费,反映业务规模',
'Take Rate(平台抽成比例)': '影响平台直接收益,需平衡广告主/媒体方利益',
'DAU(日活跃用户)': '平台流量基础,决定长期变现潜力'
},
'质量指标(影响生态长期健康)': {
'User Retention(用户留存率)': '反映用户体验,留存下降可能是广告过度干扰',
'Ad Quality Score(广告质量分)': '衡量广告合规性与用户体验,避免劣质广告'
},
'决策依据(行动指南)': """
- GMV与DAU同步增长:平台生态健康,可适度提升服务能力
- User Retention连续下降(>5%):需减少广告频次、优化广告质量,避免用户流失
- 广告主ROI与媒体eCPM双低:需优化匹配算法,提升双方价值,平衡收益与体验
"""
}
# 实际业务案例:单一指标优化 vs 整体ROI权衡(核心决策逻辑演示)
if __name__ == "__main__":
# 打印不同角色的核心指标
print("=" * 60)
print("1. 不同干系人核心关注指标")
print("=" * 60)
# 广告主指标
print("\n【广告主】")
adv_metrics = StakeholderMetrics.advertiser_metrics()
for cat, metrics in adv_metrics.items():
print(f"\n{cat}:")
if isinstance(metrics, dict):
for metric, desc in metrics.items():
print(f" - {metric}:{desc}")
else:
print(metrics.strip())
# 媒体方指标
print("\n【媒体方】")
media_metrics = StakeholderMetrics.media_metrics()
for cat, metrics in media_metrics.items():
print(f"\n{cat}:")
if isinstance(metrics, dict):
for metric, desc in metrics.items():
print(f" - {metric}:{desc}")
else:
print(metrics.strip())
# 平台方指标
print("\n【平台方】")
plat_metrics = StakeholderMetrics.platform_metrics()
for cat, metrics in plat_metrics.items():
print(f"\n{cat}:")
if isinstance(metrics, dict):
for metric, desc in metrics.items():
print(f" - {metric}:{desc}")
else:
print(metrics.strip())
# 指标权衡案例:CTR优化 vs CVR优化
print("\n" + "=" * 60)
print("2. 指标权衡案例:单一指标 vs 整体ROI")
print("=" * 60)
case = """
背景:某广告主现有投放指标:CTR=3%,CVR=10%,CPA=¥20,ROI=1.8
需在两种优化方案中选择:
【方案A:优化CTR(提升广告吸引力)】
- 指标变化:
CTR:3% → 5%(提升67%)
CVR:10% → 8%(下降20%)
CPA:¥20 → ¥25(成本上升25%)
ROI:1.8 → 1.6(收益下降11%)
- 结论:不可取
原因:虽CTR提升,但转化效率下降导致核心盈利指标(ROI/CPA)恶化,违背广告主核心目标
【方案B:优化CVR(提升转化效率)】
- 指标变化:
CTR:3% → 2.5%(下降17%)
CVR:10% → 15%(提升50%)
CPA:¥20 → ¥16(成本下降20%)
ROI:1.8 → 2.3(收益提升28%)
- 结论:可行
原因:虽CTR小幅下降,但转化效率大幅提升,核心盈利指标(ROI/CPA)显著优化,符合广告主目标
【核心经验】
- 避免“唯单一指标论”:CTR、CVR等中间指标需服务于最终目标(如ROI)
- 决策优先级:核心盈利指标(ROI/CPA)> 中间效率指标(CTR/CVR)
- 需综合评估指标间的联动影响,而非孤立优化某一项
"""
print(case.strip())7.4 A/B测试框架
A/B测试是验证算法效果的金标准。
7.4.1 A/B测试设计
import numpy as np
from scipy import stats
class ABTestDesigner:
"""
A/B测试设计工具类:提供样本量计算、测试方案设计功能,确保测试结果具备统计显著性
核心应用场景:广告模型迭代、投放策略优化等场景的效果验证
"""
@staticmethod
def calculate_sample_size(baseline_ctr: float, mde: float, alpha: float = 0.05, power: float = 0.8) -> int:
"""
计算A/B测试每组所需的最小样本量(对照组+实验组各需此样本量)
基于二项分布(CTR场景)的样本量计算公式,确保能检测到目标效应且具备统计可靠性
Args:
baseline_ctr: 基线CTR(对照组当前的点击率,如0.03表示3%)
mde: 最小可检测效应(Minimum Detectable Effect,相对提升比例,如0.1表示10%)
alpha: 显著性水平(第一类错误概率,默认0.05,即误判“有效”的概率≤5%)
power: 统计功效(1-第二类错误概率,默认0.8,即正确检测“有效”的概率≥80%)
Returns:
int: 每组所需的最小样本量(向上取整,确保样本量充足)
Raises:
ValueError: 输入参数非法(如baseline_ctr不在(0,1)、mde≤0等)
"""
# 输入参数合法性校验
if not (0 < baseline_ctr < 1):
raise ValueError(f"baseline_ctr必须在(0,1)之间,当前为{baseline_ctr}")
if mde <= 0:
raise ValueError(f"mde必须为正数(表示相对提升比例),当前为{baseline_ctr}")
if not (0 < alpha < 1):
raise ValueError(f"alpha必须在(0,1)之间,当前为{alpha}")
if not (0 < power < 1):
raise ValueError(f"power必须在(0,1)之间,当前为{power}")
# 1. 计算Z值(基于正态分布近似二项分布)
z_alpha = stats.norm.ppf(1 - alpha / 2) # 双侧检验的alpha分位数
z_beta = stats.norm.ppf(power) # 统计功效对应的beta分位数
# 2. 计算实验组预期CTR及合并概率(用于估计标准差)
p_control = baseline_ctr # 对照组CTR(基线)
p_experiment = baseline_ctr * (1 + mde) # 实验组预期CTR(基线+MDE)
pooled_p = (p_control + p_experiment) / 2 # 合并概率(用于计算 pooled 标准差)
# 3. 样本量计算公式(二项分布双侧检验)
# 公式推导:n = (Zα/2 + Zβ)² * [p1(1-p1) + p2(1-p2)] / (p1 - p2)²
numerator = (z_alpha + z_beta) ** 2 * (p_control * (1 - p_control) + p_experiment * (1 - p_experiment))
denominator = (p_control - p_experiment) ** 2
sample_size_per_group = numerator / denominator
# 向上取整,确保样本量满足统计要求(避免小数样本)
return int(np.ceil(sample_size_per_group))
@staticmethod
def design_test(baseline_ctr: float, target_improvement: float, daily_traffic: int) -> dict:
"""
完整A/B测试方案设计:基于基线CTR、目标提升、每日流量,输出样本量、测试时长、分流比例
Args:
baseline_ctr: 基线CTR(对照组当前点击率)
target_improvement: 目标提升比例(即MDE,如0.1表示10%)
daily_traffic: 每日可用于测试的总流量(如1000000表示每日100万曝光)
Returns:
dict: 测试方案详情,包含:
- sample_size_per_group: 每组所需样本量
- test_days: 预计测试天数(向上取整)
- split_ratio: 实验组分流比例(0~0.5,确保对照组流量充足)
- control_traffic: 对照组每日流量
- experiment_traffic: 实验组每日流量
Raises:
ValueError: 每日流量≤0
"""
if daily_traffic <= 0:
raise ValueError(f"daily_traffic必须为正整数,当前为{daily_traffic}")
# 1. 计算每组所需样本量
sample_size_per_group = ABTestDesigner.calculate_sample_size(
baseline_ctr=baseline_ctr,
mde=target_improvement
)
# 2. 计算总样本量(对照组+实验组)及预计测试天数
total_required_samples = sample_size_per_group * 2 # 两组总样本需求
test_days = np.ceil(total_required_samples / daily_traffic) # 向上取整,确保完成测试
# 3. 确定分流比例(优先用小比例,流量不足时最大分50%)
# 逻辑:若每日10%流量≥单组样本量,用10%分流(减少风险);否则按需求调整,最大50%
min_traffic_per_group = sample_size_per_group / test_days # 每组每日至少需的流量
if daily_traffic * 0.1 >= min_traffic_per_group:
split_ratio = 0.1 # 实验组分10%,对照组分90%
else:
# 按需求计算最小分流比例,最大不超过50%(避免对照组样本不足)
split_ratio = min(0.5, min_traffic_per_group / daily_traffic)
# 4. 计算对照组/实验组每日流量(取整,确保流量分配合理)
experiment_traffic = int(np.ceil(daily_traffic * split_ratio))
control_traffic = daily_traffic - experiment_traffic
return {
"sample_size_per_group": sample_size_per_group, # 每组所需样本量(对照组/实验组)
"test_days": int(test_days), # 预计测试天数
"split_ratio": round(split_ratio, 2), # 实验组分流比例(如0.1表示10%)
"control_traffic": control_traffic, # 对照组每日流量
"experiment_traffic": experiment_traffic # 实验组每日流量
}
# 实际使用示例:设计广告CTR优化的A/B测试方案
if __name__ == "__main__":
# 测试输入参数
baseline_ctr = 0.03 # 基线CTR:3%(对照组当前水平)
target_improvement = 0.10 # 目标提升:10%(希望实验组CTR≥3.3%)
daily_traffic = 1000000 # 每日总流量:100万曝光
# 生成测试方案
test_plan = ABTestDesigner.design_test(
baseline_ctr=baseline_ctr,
target_improvement=target_improvement,
daily_traffic=daily_traffic
)
# 打印测试方案(格式化输出,提升可读性)
print("=" * 60)
print("A/B测试方案详情")
print("=" * 60)
print(f"1. 每组所需样本量:{test_plan['sample_size_per_group']:,} 次曝光")
print(f"2. 预计测试天数:{test_plan['test_days']} 天")
print(f"3. 流量分流比例:实验组 {test_plan['split_ratio']:.0%} | 对照组 {1-test_plan['split_ratio']:.0%}")
print(f"4. 每日流量分配:")
print(f" - 对照组:{test_plan['control_traffic']:,} 次曝光/天")
print(f" - 实验组:{test_plan['experiment_traffic']:,} 次曝光/天")
print("=" * 60)
# 示例输出结果(基于输入参数计算)
A/B测试方案详情
1. 每组所需样本量:1,234,567 次曝光
2. 预计测试天数:3 天
3. 流量分流比例:实验组 50% | 对照组 50%
4. 每日流量分配:
- 对照组:500,000 次曝光/天 //基本是流量对半分 无法把控具体曝光数
- 实验组:500,000 次曝光/天
7.4.2 A/B测试分析
import numpy as np
from scipy import stats
from statsmodels.stats.proportion import proportion_confint
from typing import Dict, Tuple, Union
class ABTestAnalyzer:
"""
A/B测试结果分析工具类:基于对照组与实验组的投放数据,进行统计检验、指标对比及决策建议
核心能力:CTR差异显著性检验、置信区间计算、业务收益评估、全量发布决策
"""
@staticmethod
def _validate_input_data(data: Dict[str, Union[int, float]], data_type: str) -> None:
"""
输入数据合法性校验:确保数据包含必要字段且数值合理(内部辅助函数)
Args:
data: 对照组/实验组数据(字典)
data_type: 数据类型标识("control" 或 "experiment")
Raises:
KeyError: 缺少必要字段
ValueError: 数值非法(如曝光≤0、点击>曝光、收益<0等)
"""
# 必要字段校验
required_fields = ["impressions", "clicks", "revenue"]
missing_fields = [f for f in required_fields if f not in data]
if missing_fields:
raise KeyError(f"{data_type}组数据缺少必要字段:{', '.join(missing_fields)}")
# 数值合理性校验
impressions = data["impressions"]
clicks = data["clicks"]
revenue = data["revenue"]
# 曝光量必须为正整数
if not (isinstance(impressions, int) and impressions > 0):
raise ValueError(f"{data_type}组曝光量(impressions)必须为正整数,当前为{impressions}")
# 点击量必须为非负整数且不超过曝光量
if not (isinstance(clicks, int) and 0 <= clicks <= impressions):
raise ValueError(f"{data_type}组点击量(clicks)必须为0~{impressions}的整数,当前为{clicks}")
# 收益必须为非负数
if not (isinstance(revenue, (int, float)) and revenue >= 0):
raise ValueError(f"{data_type}组收益(revenue)必须为非负数,当前为{revenue}")
@staticmethod
def analyze_results(
control_data: Dict[str, Union[int, float]],
experiment_data: Dict[str, Union[int, float]]
) -> Dict[str, Union[float, bool, Tuple[float, float], str]]:
"""
完整A/B测试结果分析流程:指标对比→统计检验→置信区间→业务决策
Args:
control_data: 对照组数据字典,需包含:
- impressions: 曝光数(int,>0)
- clicks: 点击数(int,0≤clicks≤impressions)
- revenue: 收益(int/float,≥0)
- (可选)conversions: 转化数(int,0≤conversions≤clicks)
experiment_data: 实验组数据字典,字段与对照组一致
Returns:
Dict: 分析结果字典,包含指标、检验结果、决策建议
"""
# 1. 输入数据合法性校验(避免后续计算出错)
ABTestAnalyzer._validate_input_data(control_data, "control")
ABTestAnalyzer._validate_input_data(experiment_data, "experiment")
# 2. 基础核心指标计算(CTR、提升比例)
# 对照组指标
control_imp = control_data["impressions"]
control_click = control_data["clicks"]
control_ctr = control_click / control_imp # 对照组CTR
# 实验组指标
exp_imp = experiment_data["impressions"]
exp_click = experiment_data["clicks"]
exp_ctr = exp_click / exp_imp # 实验组CTR
# CTR相对提升(lift = (实验组CTR - 对照组CTR) / 对照组CTR)
ctr_lift = (exp_ctr - control_ctr) / control_ctr
# 3. 统计显著性检验(卡方检验:检验两组CTR是否存在显著差异)
# 构建列联表:[ [点击数, 未点击数], [点击数, 未点击数] ]
contingency_table = [
[control_click, control_imp - control_click], # 对照组:点击/未点击
[exp_click, exp_imp - exp_click] # 实验组:点击/未点击
]
# 卡方检验:返回卡方值、p值、自由度、期望频数
chi2_stat, p_value, dof, expected = stats.chi2_contingency(contingency_table)
# 显著性判断(alpha=0.05,p<0.05则认为差异显著)
is_significant = p_value < 0.05
# 4. 置信区间计算(Wilson方法:更适合小样本或比例接近0/1的场景,95%置信度)
# 对照组CTR的95%置信区间
control_ci = proportion_confint(
count=control_click,
nobs=control_imp,
alpha=0.05,
method="wilson" # Wilson得分区间:校正比例估计的偏差
)
# 实验组CTR的95%置信区间
exp_ci = proportion_confint(
count=exp_click,
nobs=exp_imp,
alpha=0.05,
method="wilson"
)
# 5. 业务收益指标计算(收益提升比例)
control_revenue = control_data["revenue"]
exp_revenue = experiment_data["revenue"]
# 处理对照组收益为0的情况(避免除以0)
revenue_lift = (exp_revenue - control_revenue) / control_revenue if control_revenue != 0 else (1.0 if exp_revenue > 0 else 0.0)
# 6. 全量发布决策建议(综合显著性、CTR趋势、收益趋势)
decision, reason = ABTestAnalyzer._generate_decision(
is_significant=is_significant,
ctr_lift=ctr_lift,
revenue_lift=revenue_lift,
p_value=p_value
)
# 7. 整理返回结果(统一格式,保留4位小数避免浮点噪声)
return {
"control_ctr": round(control_ctr, 6), # 对照组CTR
"experiment_ctr": round(exp_ctr, 6), # 实验组CTR
"ctr_lift": round(ctr_lift, 6), # CTR相对提升
"p_value": round(p_value, 6), # 显著性检验p值
"is_significant": is_significant, # 是否统计显著
"control_ctr_ci": (round(control_ci[0], 6), round(control_ci[1], 6)), # 对照组CTR置信区间
"experiment_ctr_ci": (round(exp_ci[0], 6), round(exp_ci[1], 6)), # 实验组CTR置信区间
"control_revenue": round(control_revenue, 2), # 对照组收益
"experiment_revenue": round(exp_revenue, 2), # 实验组收益
"revenue_lift": round(revenue_lift, 6), # 收益相对提升
"decision": decision, # 决策建议
"reason": reason # 决策理由
}
@staticmethod
def _generate_decision(
is_significant: bool,
ctr_lift: float,
revenue_lift: float,
p_value: float
) -> Tuple[str, str]:
"""
生成全量发布决策建议(内部辅助函数,封装决策逻辑)
Args:
is_significant: 是否统计显著(p<0.05)
ctr_lift: CTR相对提升比例
revenue_lift: 收益相对提升比例
p_value: 显著性检验p值
Returns:
Tuple[str, str]: 决策结果 + 决策理由
"""
# 场景1:统计显著 + CTR正向提升 + 收益正向提升 → 全量发布
if is_significant and ctr_lift > 0 and revenue_lift > 0:
decision = "✅ 全量发布"
reason = f"实验组CTR提升{ctr_lift:.2%},收益提升{revenue_lift:.2%},且统计显著(p={p_value:.4f}),符合全量条件"
# 场景2:统计显著 + CTR正向提升,但收益无正向提升 → 谨慎发布
elif is_significant and ctr_lift > 0 and revenue_lift <= 0:
decision = "⚠️ 谨慎发布"
reason = f"实验组CTR提升{ctr_lift:.2%}(统计显著,p={p_value:.4f}),但收益提升{revenue_lift:.2%}未达预期,需排查收益下降原因"
# 场景3:统计不显著(无论CTR趋势)→ 不发布
elif not is_significant:
decision = "❌ 不发布"
reason = f"对照组与实验组CTR差异不显著(p={p_value:.4f} > 0.05),当前差异可能为随机波动,需增加样本量或延长测试时间"
# 场景4:统计显著但CTR负向提升 → 不发布
else:
decision = "❌ 不发布"
reason = f"实验组CTR下降{abs(ctr_lift):.2%}(统计显著,p={p_value:.4f}),不符合发布条件"
return decision, reason
# 实际使用示例:分析广告CTR优化A/B测试结果
if __name__ == "__main__":
# 1. 准备对照组与实验组数据
control_data = {
"impressions": 1000000, # 对照组曝光:100万次
"clicks": 30000, # 对照组点击:3万次(CTR=3%)
"conversions": 3000, # 对照组转化:3千次(CVR=10%)
"revenue": 100000.0 # 对照组收益:10万元
}
experiment_data = {
"impressions": 1000000, # 实验组曝光:100万次(与对照组等量)
"clicks": 33000, # 实验组点击:3.3万次(CTR=3.3%)
"conversions": 3300, # 实验组转化:3.3千次(CVR=10%)
"revenue": 110000.0 # 实验组收益:11万元
}
# 2. 执行结果分析
analysis_result = ABTestAnalyzer.analyze_results(control_data, experiment_data)
# 3. 格式化打印分析结果
print("=" * 70)
print("A/B测试结果分析报告")
print("=" * 70)
print(f"1. CTR指标对比:")
print(f" - 对照组CTR:{analysis_result['control_ctr']:.3%}(95%置信区间:[{analysis_result['control_ctr_ci'][0]:.3%}, {analysis_result['control_ctr_ci'][1]:.3%}])")
print(f" - 实验组CTR:{analysis_result['experiment_ctr']:.3%}(95%置信区间:[{analysis_result['experiment_ctr_ci'][0]:.3%}, {analysis_result['experiment_ctr_ci'][1]:.3%}])")
print(f" - CTR相对提升:{analysis_result['ctr_lift']:.2%}")
print(f"\n2. 收益指标对比:")
print(f" - 对照组收益:¥{analysis_result['control_revenue']:,.2f}")
print(f" - 实验组收益:¥{analysis_result['experiment_revenue']:,.2f}")
print(f" - 收益相对提升:{analysis_result['revenue_lift']:.2%}")
print(f"\n3. 统计检验结果:")
print(f" - p值:{analysis_result['p_value']:.4f}")
print(f" - 统计显著:{'是' if analysis_result['is_significant'] else '否'}")
print(f"\n4. 决策建议:")
print(f" - 结论:{analysis_result['decision']}")
print(f" - 理由:{analysis_result['reason']}")
print("=" * 70)
# 示例输出结果
A/B测试结果分析报告
1. CTR指标对比:
- 对照组CTR:3.000%(95%置信区间:[2.971%, 3.029%])
- 实验组CTR:3.300%(95%置信区间:[3.269%, 3.331%])
- CTR相对提升:10.00%
2. 收益指标对比:
- 对照组收益:¥100,000.00
- 实验组收益:¥110,000.00
- 收益相对提升:10.00%
3. 统计检验结果:
- p值:0.0001
- 统计显著:是
4. 决策建议(举例):
- 结论:全量发布
- 理由:实验组CTR提升10.00%,收益提升10.00%,且统计显著(p=0.0001),符合全量条件7.4.3 A/B测试的常见陷阱
A/B测试常见三大陷阱及规避方法
## 陷阱1:过早停止实验
错误做法
实验仅运行1天(如周一),发现实验组CTR(3.5%)高于对照组CTR(3.0%),提升16.7%,立即判定“实验成功”并全量发布。最终结果:长期运行后,CTR提升消失甚至转为负向(如实验组CTR回落至2.8%),业务收益受损。
核心原因
1. 样本量不足:短期数据样本量小,无法反映真实效果,易受随机波动影响。
2. 随机波动干扰:单日数据可能因突发因素(如用户临时行为、外部事件)出现极端值,不具备代表性。
3. 选择偏差:单日(如周一)用户行为与全周(工作日+周末)差异大,无法覆盖完整用户行为周期。
正确做法
1. 严格按计划执行:根据预计算的样本量和测试天数(如前文ABTestDesigner输出的3天),确保实验运行满预设周期,不提前终止。
2. 达标样本量再判断:必须等待对照组、实验组均达到预设样本量(如每组123万曝光),再进行结果分析。
3. 覆盖完整周期:至少覆盖1个完整周(7天),避免因“时段特异性”导致的效果误判(如工作日vs周末用户行为差异)。
## 陷阱2:多重比较问题
错误做法
同时测试10个指标(CTR、CVR、CPA、ROI、曝光量、点击成本等),未预设“主要指标”。发现其中1个指标(如“广告停留时长”)满足“p<0.05”,即判定“实验有效”并推广。
核心问题
- 假阳性概率剧增:显著性水平α=0.05的含义是“单次比较中,误判‘有效’的概率≤5%”;但10次独立比较时,至少1次假阳性的概率=1-(1-0.05)^10≈40%,接近一半概率是“偶然显著”,非真实效果。
- 指标优先级混乱:次要指标(如停留时长)的“显著提升”可能无实际业务价值,却被误当作核心依据,导致决策偏差。
正确做法
1. 预设主要指标:实验前明确1-2个核心业务指标(如广告场景的“CTR+ROI”),仅以主要指标的显著性作为决策核心,其他指标仅作“辅助参考”。
2. 多重比较校正:若必须同时分析多个指标,需使用校正方法降低假阳性,常用Bonferroni校正:校正后显著性阈值=原阈值(0.05)/ 比较次数(如10),即p<0.005才判定为“显著”。
3. 聚焦业务价值:次要指标(如停留时长)即使“显著”,若无法关联核心收益(如ROI无提升),也不作为推广依据。
## 陷阱3:辛普森悖论(Simpson's Paradox)
典型场景
- 总体数据:实验组CTR(3.2%)> 对照组CTR(3.0%),看似“有效”。
- 分层数据:早上时段:实验组CTR(2.5%)< 对照组CTR(2.8%);晚上时段:实验组CTR(3.8%)< 对照组CTR(4.0%);分层后实验组全时段均劣于对照组,与总体结论完全矛盾。
核心原因
- 混杂因素干扰:存在未被控制的“混杂变量”(如“时段流量分配不均”):实验组:晚上流量占比80%(晚上是高CTR时段,基础CTR高);对照组:早上流量占比80%(早上是低CTR时段,基础CTR低);总体CTR差异是“时段流量结构差异”导致的假象,而非实验方案本身的效果。
正确做法
1. 分层分析验证:结果分析时,需按关键维度(如时段、用户群体、地域)分层计算指标,确保“总体结论”与“分层结论”一致,若矛盾则排查混杂因素。
2. 确保分流随机均匀:实验前必须保证“随机分流”,且各组在关键维度(时段、用户画像、地域)的流量结构一致(如实验组/对照组晚上流量占比均为50%),避免因“流量分配偏差”导致的悖论。
3. 控制混杂变量:实验设计阶段,将关键维度(如时段)作为“分层因子”,采用“分层随机抽样”,确保各组在分层因子上的分布完全匹配。7.5 模型迭代策略
持续优化才能保持竞争力。
7.5.1 迭代周期
class ModelIterationPlan:
"""
模型迭代计划:按周期(周/月/季度)制定不同粒度的迭代目标与任务,平衡快速验证与长期战略
"""
@staticmethod
def weekly_iteration():
"""
每周迭代(快速实验):聚焦短期优化,验证小范围改进(如特征、参数调整)
返回:每周每日的核心任务安排
"""
return {
'Monday': '数据准备(处理上周全量业务数据,清洗标注)',
'Tuesday': '特征工程(尝试1-2个新特征或特征组合,验证有效性)',
'Wednesday': '模型训练(基于新数据/特征训练模型,跑离线实验)',
'Thursday': '离线评估(验证AUC、GAUC、LogLoss等核心指标,筛选最优模型)',
'Friday': 'A/B测试上线(将最优模型灰度到10%流量,监控基础指标)',
'Weekend': '监控指标(实时跟踪线上CTR、CVR等,排查异常波动)',
'下周一': '决策:指标达标则全量,不达标则回滚,异常则继续观察1-2天'
}
@staticmethod
def monthly_major_update():
"""
每月大版本(架构升级):聚焦中期优化,迭代模型架构或核心逻辑(如算法替换、多目标优化)
返回:每月每周的核心任务安排
"""
return {
'Week 1': '问题诊断(分析上月线上数据,定位指标瓶颈,明确优化痛点)',
'Week 2': '方案设计(设计新模型架构/算法,输出技术方案与评估标准)',
'Week 3': '开发验证(完成模型开发,通过离线全量数据验证,确保指标提升)',
'Week 4': 'A/B测试(灰度到20%-30%流量,多维度监控指标稳定性)',
'下月': '决策:全量推广(指标达标)或回滚优化(指标不达标)'
}
@staticmethod
def quarterly_strategic_upgrade():
"""
每季度战略升级(方向调整):聚焦长期布局,适配业务战略变化(如新技术引入、场景拓展)
返回:每季度每月的核心任务安排
"""
return {
'Month 1': '调研分析(调研业界前沿技术、竞品方案,结合业务战略明确升级方向)',
'Month 2': '技术预研(搭建预研环境,验证新技术可行性,输出预研报告)',
'Month 3': '灰度上线(完成技术落地,小流量(5%-10%)验证业务适配性)',
'下季度': '全量推广(技术稳定后逐步扩大流量,完成全量覆盖)'
}🙏 致谢
感谢你读完这个系列!希望这些内容对你有所帮助。
持续学习,持续进步! 🚀
参考的文章:
[1] Factorization Machines
- Rendle, S. (2010). “Factorization Machines.” IEEE International Conference on Data Mining (ICDM).
- https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
[2] Wide & Deep Learning
- Cheng, H. T., et al. (2016). “Wide & Deep Learning for Recommender Systems.” 1st Workshop on Deep Learning for Recommender Systems.
- https://arxiv.org/abs/1606.07792
[3] DeepFM
- Guo, H., et al. (2017). “DeepFM: A Factorization-Machine based Neural Network for CTR Prediction.” IJCAI.
- https://arxiv.org/abs/1703.04247
[4] Deep & Cross Network (DCN)
- Wang, R., et al. (2017). “Deep & Cross Network for Ad Click Predictions.” ADKDD.
- https://arxiv.org/abs/1708.05123
[5] Deep Learning Recommendation Model (DLRM)
- Naumov, M., et al. (2019). “Deep Learning Recommendation Model for Personalization and Recommendation Systems.” arXiv preprint.
- https://arxiv.org/abs/1906.00091
[6] Entire Space Multi-Task Model (ESMM)
- Ma, X., et al. (2018). “Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate.” SIGIR.
- https://arxiv.org/abs/1804.07931
[7] Multi-gate Mixture-of-Experts (MMOE)
- Ma, J., et al. (2018). “Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts.” KDD.
- https://dl.acm.org/doi/10.1145/3219819.3220007
[8] Horovod
- Sergeev, A., & Del Balso, M. (2018). “Horovod: fast and easy distributed deep learning in TensorFlow.” arXiv preprint.
- https://arxiv.org/abs/1802.05799
[9] Ring-AllReduce Algorithm
- Patarasuk, P., & Yuan, X. (2009). “Bandwidth optimal all-reduce algorithms for clusters of workstations.” Journal of Parallel and Distributed Computing, 69(2), 117-124.
[10] A/B Testing Methodology
- Kohavi, R., Longbotham, R., Sommerfield, D., & Henne, R. M. (2009). “Controlled experiments on the web: survey and practical guide.” Data Mining and Knowledge Discovery, 18(1), 140-181.
[11] TensorFlow Recommenders Addons (TFRA)
- Dynamic Embedding实现
- GitHub: https://github.com/tensorflow/recommenders-addons
- 文档: https://www.tensorflow.org/recommenders-addons
[12] Horovod - Distributed Training Framework
[13] TensorFlow Serving
[14] TensorFlow Model Optimization
[15] Google AI Blog - Wide & Deep Learning
- “Wide & Deep Learning: Better Together with TensorFlow”
- https://ai.googleblog.com/2016/06/wide-deep-learning-better-together-with.html
[16] Facebook AI Blog - DLRM
- “DLRM: An advanced, open source deep learning recommendation model”
- https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep-learning-recommendation-model/
[17] Uber Engineering Blog - Horovod
- “Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework”
- https://eng.uber.com/horovod/
[18] Alibaba Tech - ESMM实践
- “阿里妈妈:品牌广告中的NLP算法实践”
- https://developer.aliyun.com/article/684543
[19] Netflix Tech Blog - A/B Testing
- “It’s All A/Bout Testing: The Netflix Experimentation Platform”
- https://netflixtechblog.com/its-all-a-bout-testing-the-netflix-experimentation-platform-4e1ca458c15
[20] Criteo AI Lab - CTR Prediction
- “Deep Learning for Click-Through Rate Estimation”
- https://ailab.criteo.com/