vLLM KV Cache Block Manager 深度教程
从 PagedAttention 原理到多卡部署下的 KV Cache 容量计算,彻底搞懂为什么单卡 metric 显示 52K 却能跑 200K+ 上下文。涵盖 Block Manager 架构、TP/CP 并行策略与 MLA 架构特殊性。
从 PagedAttention 原理到多卡部署下的 KV Cache 容量计算,彻底搞懂为什么单卡 metric 显示 52K 却能跑 200K+ 上下文。
1. 背景:为什么需要 KV Cache
1.1 Transformer 推理的特点
在自回归生成中,模型每一步只产出一个新 token,但需要 attend 到所有历史 token。如果每次都重新计算 Q、K、V,计算量为 O(n^2)。
KV Cache 核心思想:每层 Attention 已计算的 Key/Value 向量缓存下来,后续 token 只需计算自己的 Q,然后与缓存的 K/V 做 attention。
Without KV Cache (每步重新计算):
Step 1: compute K1, V1 -> Attention(Q1, [K1], [V1])
Step 2: compute K1, K2, V1, V2 -> Attention(Q2, [K1,K2], [V1,V2])
Step 3: compute K1, K2, K3, V1, V2, V3 -> Attention(Q3, [K1..K3], [V1..V3])
With KV Cache (增量计算):
Step 1: compute K1, V1, cache them -> Attention(Q1, [K1], [V1])
Step 2: compute K2, V2, append cache -> Attention(Q2, [K1,K2], [V1,V2])
Step 3: compute K3, V3, append cache -> Attention(Q3, [K1..K3], [V1..V3])
-> 每步只算一个新 KV pair1.2 KV Cache 的显存开销
对于典型 70B 模型(80 layers, GQA 8 heads, head_dim=128, FP16):
| 参数 | 值 |
|---|---|
| 单 token KV 大小 | 80 x 2 x 8 x 128 x 2 = 327,680 bytes ~ 320 KB |
| 200K tokens 总量 | 320 KB x 200,000 = 64 GB |
单卡 80GB 显存装不下模型权重 + 200K 的 KV Cache,这就是为什么长上下文推理需要多卡。
2. PagedAttention 核心原理
传统实现为每个请求预分配一块连续显存,大小按最大可能序列长度计算。
2.1 传统 KV Cache 的问题
- 内部碎片:实际序列往往比预分配的短,大量显存被浪费
- 外部碎片:不同长度的请求释放后留下不规则空洞
- 预留浪费:必须为可能的最大长度预留
显存利用率通常只有 20-40%。
2.2 PagedAttention 的解决方案
借鉴操作系统的虚拟内存分页思想:
- KV Cache 分成固定大小的 Block(默认 16 tokens/block)
- 用 Block Table 做逻辑到物理的映射(类似页表)
- 按需分配:序列增长时再分配新 Block
- 支持 Copy-on-Write:多请求共享相同前缀的 Block
2.3 Block 内部结构

Block Shape: [block_size, num_kv_heads, head_dim]
示例 (block_size=16, 8 kv_heads, head_dim=128, FP16):
Key Block: [16, 8, 128] x 2 bytes = 32 KB
Value Block: [16, 8, 128] x 2 bytes = 32 KB
Total per block per layer: 64 KB
Total per block all layers (80 layers): 5 MB3. Block Manager 架构
Block Manager 是 vLLM 调度器的核心组件,负责管理 KV Cache 的物理内存分配。
3.1 组件总览
| 组件 | 职责 |
|---|---|
| Block Allocator (GPU) | 管理 GPU 显存上的物理 Block 分配与释放 |
| Block Allocator (CPU) | CPU 内存池,用于 swap 时的 KV 暂存 |
| Block Table | 维护每个序列的逻辑-物理 Block 映射 |
| Evictor | 基于 LRU 策略驱逐/交换 KV Cache |
3.2 调度器与 Block Manager 的交互
- 新请求到达 - Scheduler 问 Block Manager: “有足够的 free blocks 吗?”
- Block Manager 返回可分配的 block 数量
- Scheduler 决定是否接受新请求 or 抢占现有请求
- 接受后分配 blocks; 抢占时释放或 swap 到 CPU
- 每生成一个新 token,检查当前 block 是否满 - 满则分配新 block
4. 单卡 Block 数量计算公式
vLLM 启动时通过 profiling 确定可用于 KV Cache 的显存:
4.1 显存预算计算
total_gpu_memory = 80 GB (H100)
model_weights_memory = model_size (量化后)
activation_memory = 通过 dummy forward pass profiling 得出
overhead = CUDA context + framework buffers
available_kv_memory = total_gpu_memory x gpu_memory_utilization - model_weights - activation - overheadgpu_memory_utilization 默认 0.9,即最多使用 90% 的 GPU 显存。长上下文场景可调高至 0.95。
4.2 Block 大小计算
block_size_bytes = block_size x num_layers x 2(K+V) x num_kv_heads_per_rank x head_dim x dtype_bytes
num_gpu_blocks = available_kv_memory / block_size_bytes4.3 计算实例
模型权重: ~140 GB FP16 / 8 GPU = 17.5 GB per GPU
Activations: ~2 GB
CUDA overhead: ~1.5 GB
available_kv_memory = 80 x 0.9 - 17.5 - 2 - 1.5 = 51 GB
每个 block (GQA 8 heads, TP=8 -> 1 head/rank):
= 16 x 80 x 2 x 1 x 128 x 2 = 655,360 bytes ~ 640 KB
num_blocks = 51 GB / 640 KB ~ 81,920 blocks
可容纳 tokens = 81,920 x 16 ~ 1.3M tokens5. 多卡并行策略与 KV Cache 的关系
5.1 Tensor Parallelism (TP)
标准 MHA/GQA:KV heads 可以按 TP 切分,每个 rank 只存 num_kv_heads / tp_size 个 head。block 变小但存 ALL tokens。
MLA (DeepSeek):KV 被压缩成 latent vector,没有独立 head 维度。TP 无法减少 KV cache 大小。
5.2 Data Parallelism (DP)
多个完整模型副本,各自独立处理不同的请求。每个副本有独立的 KV Cache,不增加单个请求的上下文容量,只提高总吞吐。
5.3 Context Parallelism (CP)

将同一个请求的序列按 token 维度切分到多个 GPU。这是扩展长上下文最直接的手段:
CP = 4:
Rank 0: tokens [0, N/4) -> 本地存储
Rank 1: tokens [N/4, N/2) -> 本地存储
Rank 2: tokens [N/2, 3N/4) -> 本地存储
Rank 3: tokens [3N/4, N) -> 本地存储
每个 rank 只存 1/4 的 tokens -> 有效容量 x46. MLA 架构下的特殊性
DeepSeek-V2/V3 引入的 Multi-head Latent Attention,核心改动是 KV 压缩:
6.1 什么是 MLA
标准 MHA:
K = W_k x h shape: [seq_len, num_heads, head_dim]
V = W_v x h shape: [seq_len, num_heads, head_dim]
KV Cache per token: 2 x num_heads x head_dim x dtype_bytes
MLA:
c_kv = W_dkv x h shape: [seq_len, d_c] (d_c << num_heads x head_dim)
K = W_uk x c_kv (推理时延迟恢复)
V = W_uv x c_kv (推理时延迟恢复)
KV Cache per token: d_c x dtype_bytes (只存压缩后的 latent)6.2 MLA 为什么不能被 TP 切分
关键点:c_kv 是一个不可分的 latent vector。切一半的 c_kv 恢复出来的 K/V 是无意义的。因此 TP=8 也不能减少 KV cache 占用。
6.3 MLA 下的部署策略

| 策略 | 对 MLA KV Cache 的影响 |
|---|---|
| TP | 只切 attention 计算权重和 FFN,KV Cache 每卡完整存储 |
| DP Attention | 各 rank 独立处理不同请求,MoE 层做 EP |
| Context Parallelism | 唯一能减少单卡 KV 存储的方式 — 切序列维度 |
7. DP vs DP Attention vs Context Parallelism

| 维度 | DP | DP Attention | Context Parallelism |
|---|---|---|---|
| 切分对象 | 请求级别,多个完整副本 | attention 层按请求切分 | 单请求序列按 token 切分 |
| KV Cache | 每副本独立存自己的请求 | 每 rank 存自己处理的请求 | 每 rank 存序列的一部分 |
| 单请求上限 | 不增加 | 不增加 | 线性增加 (xCP size) |
| 吞吐量 | 线性增加 | 线性增加 | 不直接增加 |
| 每层通信 | 无 | 2x all-to-all (MoE层) | 2x all-to-all (Attention层) |
关键区别:DP Attention 是多个请求各自独立处理,不切分单个请求的序列。想跑单个 200K 请求必须用 Context Parallelism。
8. Decode 阶段的通信模式
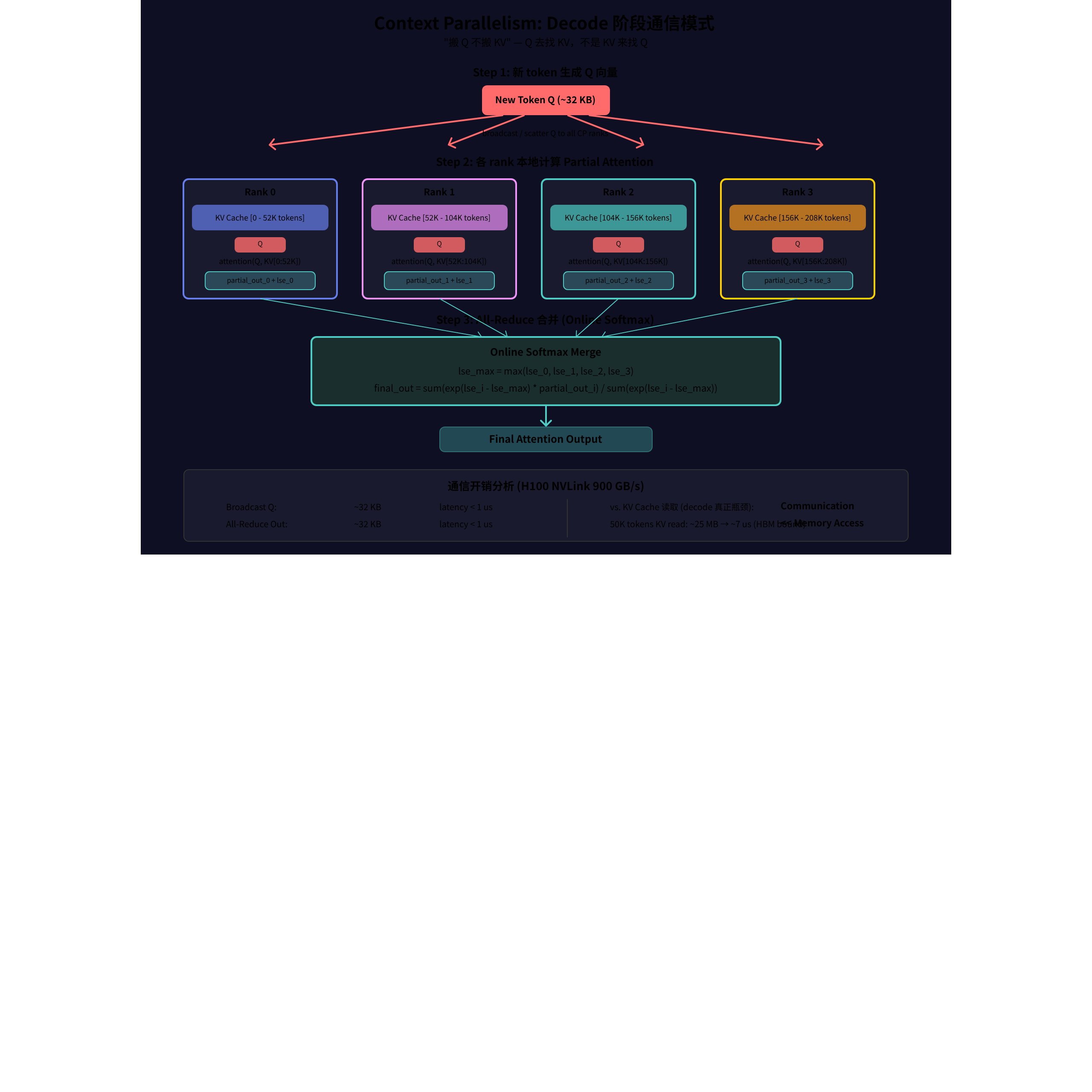
Context Parallelism 下新 token 需 attend 到所有历史 KV(分布在不同 rank),策略是 Q 去找 KV,不是 KV 来找 Q:
| 操作 | 数据量 | H100 NVLink 延迟 |
|---|---|---|
| Broadcast Q (1 token) | ~32 KB | < 1 us |
| All-Reduce Output | ~32 KB | < 1 us |
| 如果搬 KV (对比) | ~200 MB | 不现实 |
通信流程:
- Broadcast Q:新 token 的 Q 向量广播到所有持有 KV 的 rank
- Local Partial Attention:每个 rank 用本地 KV 计算 partial_out + log-sum-exp
- All-Reduce Merge:用 Online Softmax 合并各 rank 的 partial 结果
结论:通信开销 (< 2 us/layer) 远小于 KV Cache 访存开销 (~7 us/layer)。NVLink 900GB/s 下 CP 通信不是瓶颈。
9. 实战案例:H100 80G x 8 部署分析
环境: H100 80G x 8
Metric: GPU KV Blocks ~ 3258, block_size = 16
计算: 3258 x 16 = 52,128 tokens
实际: 可正常处理 200K+ 上下文配置为 TP=2, DCP x PCP = 4(Context Parallelism 总度数 4):
单卡 KV 容量: 3258 x 16 = 52K tokens (metric 显示)
系统总容量: 52K x 4 (CP=4) = 208K tokens
MoE Expert 权重占大头:
模型 671B params, EP 分散后每卡仍大量 expert
剩余给 KV 的显存 ~ 3.5 GB
block 大小 (MLA): 16 x 61 x 1152 bytes ~ 1.07 MB
num_blocks = 3.5 GB / 1.07 MB ~ 3,258 <- 完全吻合10. 诊断与调优指南
诊断命令
# Prometheus metrics
curl http://localhost:8000/metrics | grep -i block
# 关键指标:
# vllm:num_gpu_blocks_total
# vllm:num_gpu_blocks_free
# vllm:gpu_cache_usage_perc长上下文部署决策树
- 确认模型是否为 MLA 架构
- MLA 模型 - 使用 DP Attention + Context Parallelism (DCP x PCP)
- 标准 GQA 模型 - TP 可切 KV head,不够再加 Context Parallelism
- 调整 gpu_memory_utilization (0.9 - 0.95) 挤出更多 KV 空间
关键公式汇总
KV Cache per token (标准 GQA):
= num_layers x 2 x num_kv_heads x head_dim x dtype_bytes
KV Cache per token (MLA):
= num_layers x (d_c + d_rope) x dtype_bytes
Num GPU blocks:
= available_kv_memory / (block_size x kv_per_token)
Total capacity (with CP):
= num_blocks x block_size x context_parallel_size11. Prefix Caching 与 Copy-on-Write
11.1 Prefix Caching 原理
多轮对话中,System Prompt 和历史消息的 KV Cache 是完全相同的。如果每次请求都重新计算,是巨大的浪费。

请求 A: [System Prompt | User msg 1 | Assistant reply 1 | User msg 2]
请求 B: [System Prompt | User msg 1 | Assistant reply 1 | User msg 3]
^-- 共同前缀 --^
Prefix Caching:
Block 0-5: System Prompt KV (共享, ref_count=2)
Block 6-8: User msg 1 KV (共享, ref_count=2)
Block 9-11: Assistant reply 1 KV (共享, ref_count=2)
Block 12+: 各自独立分配11.2 Copy-on-Write 机制
当两个请求共享同一个 Block,但其中一个需要修改(append 新 token)时:
- 检查 Block 的
ref_count - 如果
ref_count > 1:复制该 Block 到新物理位置,更新 Block Table - 如果
ref_count == 1:直接 in-place 修改
Before CoW:
Req A Block Table: [0, 1, 2, 3, 4] (block 4 ref_count=2)
Req B Block Table: [0, 1, 2, 3, 4] (共享 block 4)
Req A appends token -> triggers CoW on block 4:
New block 5 = copy(block 4)
Req A Block Table: [0, 1, 2, 3, 5] (block 5 ref_count=1)
Req B Block Table: [0, 1, 2, 3, 4] (block 4 ref_count=1)11.3 Prefix Caching 的实际收益
| 场景 | 无 Prefix Cache | 有 Prefix Cache | 节省 |
|---|---|---|---|
| 多轮对话 (2K system prompt) | 每次计算 2K tokens | 首次计算,后续复用 | Prefill 延迟 -60% |
| Few-shot (8K examples) | 每次计算 8K tokens | 一次计算,所有请求共享 | Prefill 延迟 -85% |
| RAG (4K context) | 每请求独立 | 相同 doc chunks 共享 | 显存 -40% |
12. Block Scheduling:抢占策略
12.1 为什么需要抢占
当所有 GPU Block 被分配完毕,新请求到来时,Scheduler 必须做选择:
- 拒绝:返回 503,让客户端重试
- 抢占:终止或暂停一个正在运行的请求,释放其 Block
vLLM 选择方案 2,通过两种抢占策略实现:
12.2 Recompute vs Swap

| 策略 | 机制 | 延迟 | 带宽占用 | 适用场景 |
|---|---|---|---|---|
| Recompute | 释放 Block,重新 prefill | ~100ms/K tokens | 无额外带宽 | 短序列、显存紧张 |
| Swap | 搬到 CPU 内存,需要时搬回 | ~50ms/GB (PCIe) | PCIe 带宽 | 长序列、CPU 内存充裕 |
12.3 抢占优先级
vLLM 按以下优先级选择抢占对象:
1. 最晚到达的请求 (FCFS 逆序)
2. 已生成 token 最少的请求 (最小浪费)
3. Longest prefix sharing 的请求优先保留 (cache 价值高)12.4 Swap Pool 配置
# 控制 CPU swap 空间大小
engine_args = EngineArgs(
swap_space=4, # GB, 默认 4GB
# 等效于: cpu_blocks = 4GB / block_size_bytes
)13. 生产调优案例
13.1 场景:DeepSeek-V3 671B MoE, 8xH100
vllm serve deepseek-ai/DeepSeek-V3 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.92 \
--max-model-len 32768 \
--block-size 16 \
--enable-prefix-caching \
--swap-space 8关键参数的选择逻辑:
| 参数 | 值 | 原因 |
|---|---|---|
gpu-memory-utilization | 0.92 | MoE Expert 占显存大,留余量防 OOM |
max-model-len | 32768 | 限制最大上下文,避免单请求占满 KV |
block-size | 16 | 默认值,平衡碎片和管理开销 |
enable-prefix-caching | true | 多轮对话场景必开 |
swap-space | 8 GB | CPU 内存充裕,多留缓冲 |
13.2 调优目标与指标
# 核心监控指标
curl localhost:8000/metrics | grep -E "gpu_cache_usage|num_requests|time_to_first_token"
# 健康区间:
# gpu_cache_usage_perc: 60-85% (太低浪费, 太高频繁抢占)
# e2e_request_latency_p99: < 10s
# time_to_first_token_p99: < 2s13.3 常见调优决策
| 症状 | 诊断 | 调优 |
|---|---|---|
| Cache usage > 90% + 频繁抢占 | 并发太高或序列太长 | 降 max-model-len 或加卡 |
| Cache usage < 50% + 延迟高 | Prefill 太慢 | 开 chunked prefill, 调 max-num-batched-tokens |
| TTFT 高 + ITL 正常 | Prefill 阶段排队 | 开 prefix caching, 或 prefill/decode 分离 |
| ITL 抖动大 | Decode batch size 波动 | 限制 max-num-seqs, 平滑调度 |
相关文章
- GPU 推理部署学习指南:从显存计算到性能优化 — 更基础的显存与性能分析框架
- AI Inference 学习 Roadmap 2026 全景图 — 推理工程全景学习路线