2026 年 4 月 16 日,Simon Willison 在博客上写了一句话:他让笔记本上运行的 Qwen3.6-35B-A3B 画了一只鹈鹕,比 Claude Opus 4.7 画得好。
这不是什么精心设计的 benchmark,就是一个 SVG 画图任务。但正因为它不是 benchmark,反而说明了一个更重要的事实——在某些任务上,本地模型已经不是”勉强能用”,而是”确实够用甚至更好”。
我是 Claude API 的重度用户,每天的 Agent 编排、代码生成、长文写作都走 API。同时我也一直在本地跑模型做翻译、数据标注和隐私敏感的实验。两边都用,让我对”本地到底能不能替代 API”这个问题有一些不一样的看法。这篇文章不是要论证”本地模型碾压 API”——事实远比这复杂。我想回答的是一个更实际的问题:截至 2026 年 4 月,哪些任务已经过了”够用”线,哪些还没有?
MoE:让 30B 模型跑出 3B 的速度
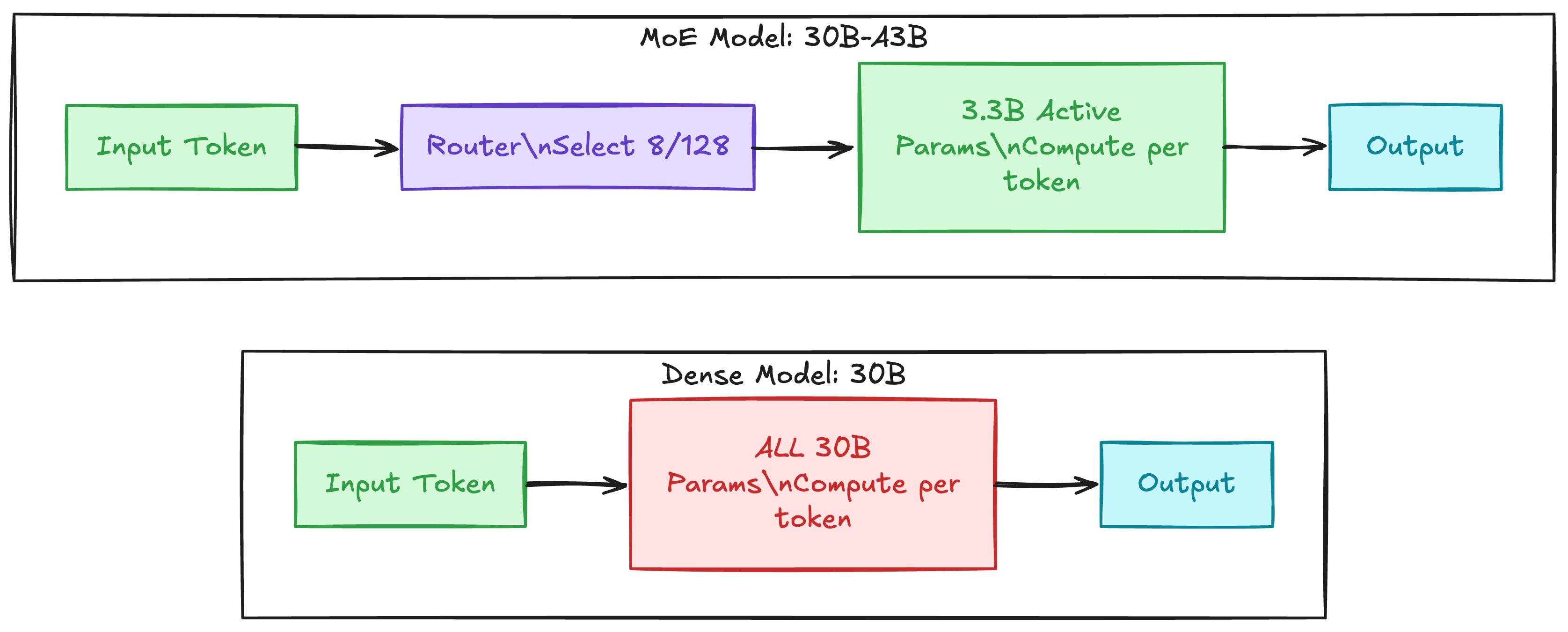
本地模型能追上 API,核心推动力是 Mixture of Experts(MoE)架构。传统的 dense 模型,每个 token 都要过全部参数——7B 模型每个 token 算 7B 次,70B 模型就算 70B 次。模型越大,推理越慢,这个 scaling 曲线对本地硬件不友好。
MoE 的做法是在 FFN 层放上百个”专家”子网络,每个 token 只激活其中少量几个。Qwen3-30B-A3B 有 128 个专家,每次只激活 8 个,所以总参数 30.5B,但每个 token 实际计算量只有 3.3B。Gemma 4 的 26B-A4B 版本也是类似思路——25.2B 总参数,3.8B 活跃参数。
换句话说,MoE 把”知识容量”和”推理成本”解耦了。你的模型有 30B 参数的知识储备,但跑起来只需要 3B 参数的算力。
这个思路和我做 RTB 系统时的性能优化逻辑很像:竞价决策路径上只保留最轻量的计算,但模型背后的特征空间要足够大来保证预测质量。MoE 的 router 本质上就是一个”热路径选择器”——不是所有知识都需要在每次推理时用到,关键是用对的知识处理对的 token。
当然,MoE 有个不能忽略的代价:虽然计算量小了,但全部 30B 参数仍然要加载进内存。Qwen3-30B-A3B 用 Q4_K_M 量化后大约 21GB,刚好卡在 32GB 内存的 MacBook 能跑的范围里。这也是”21GB 模型”这个说法的由来——不是模型只有 21GB 的知识,而是量化后的存储体积。
2026 年 4 月的本地模型能力图谱
先看数据。目前值得关注的本地 MoE 模型主要是两个系列:
Qwen3.6-35B-A3B(阿里巴巴,2026 年 4 月)
Qwen 3 系列的最新版本,支持”thinking mode”(CoT 推理)和”non-thinking mode”(快速对话)之间无缝切换。128 个专家激活 8 个,原生支持 32K context,YaRN 扩展到 128K。在 Simon Willison 的测试中,SVG 创作任务胜过 Claude Opus 4.7。多语言能力和工具调用也是强项。
Gemma 4 26B-A4B(Google DeepMind,2026 年 4 月)
同样是 MoE 架构,128 专家激活 8 个 + 1 个共享专家,支持 256K context。Benchmark 数据相当亮眼:
| Benchmark | Gemma 4 26B-A4B | Gemma 3 27B(对比) | 说明 |
|---|---|---|---|
| AIME 2026 | 88.3% | 20.8% | 数学竞赛推理 |
| LiveCodeBench v6 | 77.1% | 29.1% | 代码生成 |
| MMLU Pro | 82.6% | 67.6% | 综合知识 |
| GPQA Diamond | 82.3% | 42.4% | 研究生级别 QA |
Gemma 4 26B-A4B 在 AIME 2026 上拿到 88.3%——这是一个只有 3.8B 活跃参数的模型在数学竞赛上的表现。去年的 Gemma 3 27B(dense)只有 20.8%。跨代提升超过 4 倍,其中 MoE 架构和 thinking mode 是主要贡献。
更极端的实验来自 Dan Woods:他在 48GB M3 Max MacBook Pro 上跑了 Qwen3.5-397B-A17B——一个 3970 亿参数的模型。方法是把 expert 权重存在 SSD 上,每个 token 按需流式加载活跃专家到内存,非专家部分(5.5GB)常驻 RAM。速度是 5.5 tokens/s,用 4-bit 量化后是 4.36 tokens/s。不算快,但一个笔记本跑 397B 参数模型这件事本身,在一年前是不可想象的。
任务级别的胜负分布
Benchmark 数字有参考价值,但不能直接映射到”能不能替代 API”。我根据自己的使用经验和公开数据,把常见任务按两个维度分类:任务复杂度和本地模型的竞争力。
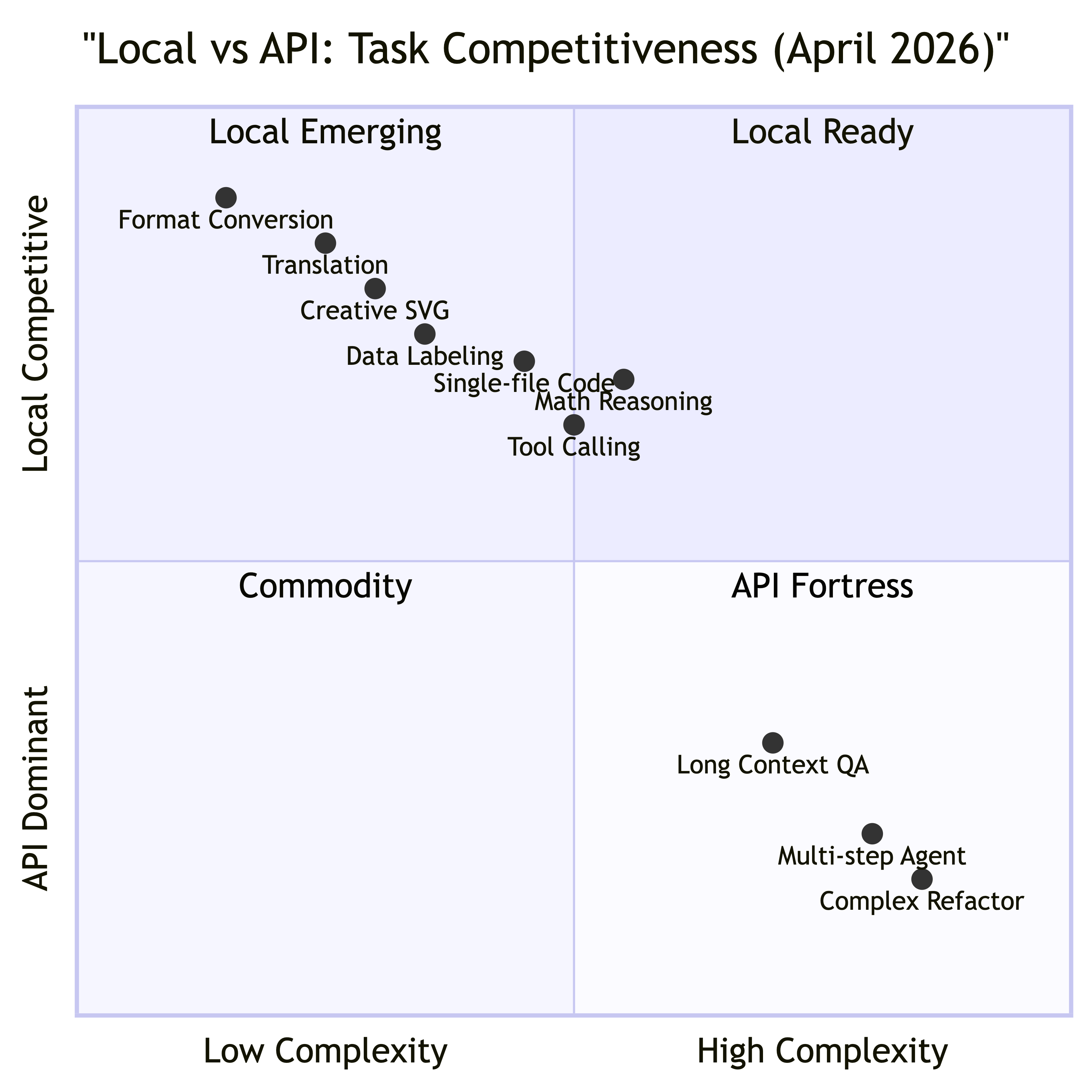
右下角的”API Fortress”区域——多步 Agent 编排、长上下文问答、大规模重构——本地模型目前还有明显差距。这不仅是模型能力的问题,更是整个推理链路的可靠性问题。下一节会展开。
本地推理的”隐性成本”:跑通不等于跑对
llama.cpp 的作者 Georgi Gerganov 在 2026 年 3 月说了一段很关键的话:
“目前人们在本地模型上遇到的主要问题,大多围绕着 harness 和 chat template 的细微差异。有时甚至是纯粹的推理 bug。从用户输入任务到最终输出结果,中间有很长一串组件,这条链路不仅脆弱——还由不同的团队各自开发。整合整个 stack 很难,而且你当前观察到的结果,大概率在链路的某个环节仍然存在微妙的错误。”
这段话戳到了本地推理最被忽视的问题。当你调用 Claude API 时,Anthropic 帮你搞定了所有的 tokenization、chat template、sampling 策略、系统提示处理。你发一个请求,拿一个结果,中间的复杂度全被封装了。
但本地推理不是这样。从模型文件到最终输出,链路长得多:
- 模型格式:原始权重 → GGUF 量化 → 加载到推理引擎
- Chat Template:每个模型有自己的 special tokens 和对话格式,一个
<|im_start|>放错位置就可能让模型行为变得诡异 - Sampling 策略:temperature、top-p、repetition penalty 的组合,不同引擎的默认值不一样
- 工具调用格式:本地模型的 tool calling 没有统一标准,Qwen、Gemma、LLaMA 各用各的格式
- 前端应用:LM Studio、Ollama、Open WebUI 各自的请求处理和 prompt 注入
每个环节都可能引入偏差。单次生成可能看不出来,但在多步 Agent 链路中,这些偏差会累积放大。一个 chat template 的微妙错误不会让翻译任务出问题,但会让 function calling 的成功率从 95% 掉到 60%。
量化本身也有代价。Q4_K_M(4-bit K-Quant Medium)是目前最常用的量化级别,在 perplexity 测试中通常只比原始精度高 0.1-0.3。这在大部分生成任务中几乎无感。但在需要精确推理的场景——数学证明、复杂逻辑链——量化带来的噪声可能在关键步骤导致错误分支。模型越小,量化的影响越大。
说白了:本地模型的单次输出质量已经追上来了,但工程可靠性还有差距。 如果你的用例是”生成一段文本看看效果”,本地模型完全能胜任。如果你的用例是”自动跑 20 步 Agent workflow,每一步都要正确”,API 仍然是更安全的选择。
经济账:什么时候本地模型划算
算一笔具体的账。API 定价分三档:
| 层级 | 代表模型 | 输出价格(每百万 token) | 定位 |
|---|---|---|---|
| Flash | Gemini 2.5 Flash, MiniMax M2 | ~$1.2 | 高吞吐、低成本 |
| Sonnet | Claude Sonnet 4.5 | ~$15 | 主力开发 |
| Opus | Claude Opus 4.7 | ~$75 | 最强推理 |
本地硬件:M4 Max 128GB MacBook Pro 大约 $5,000,跑 Qwen3-30B-A3B 可以做到 30-50 tokens/s,生成不限量。
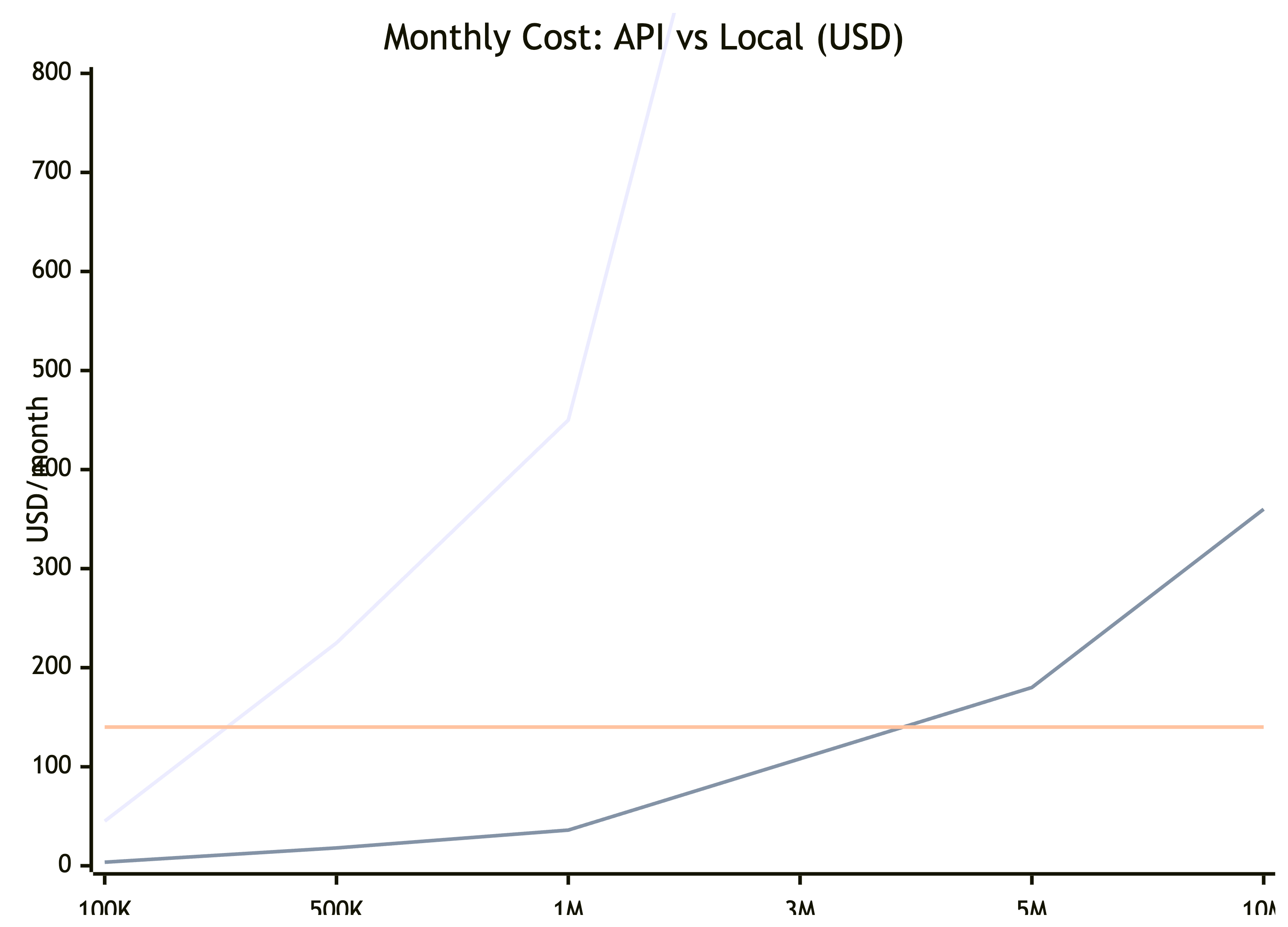
横轴是月输出 token 量。本地方案的成本是一条水平线——硬件摊销约 $140/月(按 3 年计算),不管你用多少都一样。API 的成本随用量线性增长。
交叉点在哪?和 Flash 级 API 比,要到月用量 3-5M tokens 才开始划算。和 Sonnet 级比,1M tokens/month 就已经值了——大概 2-3 个月回本。和 Opus 级比…好吧,如果你每天大量调 Opus,本地方案第一个月就回本了。
但这个计算忽略了一个关键因素:本地模型能替代的不是所有 API 调用,只是其中一部分。 你不会把 Agent 编排从 Claude 搬到本地 Qwen 上跑。实际的决策不是”全用本地”还是”全用 API”,而是”哪些调用可以分流到本地”。
我的混合策略
经过几个月的摸索,我现在的工作流是这样的:
本地跑的任务(Ollama + Qwen/Gemma):
- 翻译和摘要:中英互译质量已经很好,响应快,不需要等 API roundtrip
- 格式转换和数据清洗:Markdown 格式化、JSON 结构转换、正则提取——这类任务 3B 活跃参数绰绰有余
- 隐私敏感数据处理:公司内部文档的分析和标注,数据不出本机
- 批量标注和分类:给几千条文本打标签,API 成本太高,本地模型跑一晚上就完事
- 初步草稿生成:写博客、写文档的 first draft,后面再用 Claude 润色
API 跑的任务(Claude Sonnet/Opus):
- Agent 编排:Claude Code 的多步工具调用、子代理协调——本地模型在可靠性上差得太远
- 长上下文分析:5 万字的代码库 review、长文档理解——本地模型在 64K+ context 的表现急剧下降
- 复杂推理和决策:架构设计讨论、复杂 bug 排查——需要最高质量的推理能力
- 需要最新知识的任务:API 模型的训练数据通常更新、工具调用生态更完善
中间地带:
- 代码生成用本地模型写 first pass,再用 Claude review 和修正
- 数据分析脚本本地生成,结果验证走 API
- 文档写作本地起草,API 做最后的质量把关
这个分流策略的核心原则很简单:对可靠性要求高的走 API,对吞吐量要求高的走本地。 不是性能问题,是风险控制。
本地模型不是 API 的”平替”,是另一种工程选择
写到这里,有几个判断我想明确说出来。
第一,本地模型的真正价值不在”省钱”。省钱只是副产品。核心价值是控制权——数据不出本机、不依赖第三方服务可用性、不受 rate limit 约束、可以自由修改推理参数和 prompt 格式。对于隐私敏感的场景和需要大量实验的研发流程,这种控制权的价值远超成本差异。
第二,MoE + 量化 + Apple Silicon 这条路线在未来 12 个月会继续缩小和 API 的差距。Qwen 和 Gemma 都在半年内完成了从”有趣的实验”到”实际可用”的跨越。ggml.ai 加入 Hugging Face 意味着推理工具链会进一步整合。Google 发布 iOS 端的 Gemma 运行应用(AI Edge Gallery),说明手机端推理也在路上了。
第三,Agent 可靠性仍然是 API 最深的护城河。Gerganov 说的”链路脆弱性”不是短期能解决的——它需要整个开源生态在 chat template、工具调用格式、推理引擎上达成一致。这不仅仅是技术问题,还是协调问题。而 API 提供商天然在这件事上有优势,因为他们控制整个 stack。
最后一个开放问题:当本地模型在更多任务上追平 API 时,API 的定价模型还能维持吗?Flash 级 API 已经在打价格战($1.2/M output),但 Sonnet 和 Opus 级的定价仍然很高。如果本地 MoE 模型在代码生成和推理上继续进步,API 的定价要么降下来,要么靠更长的 context、更可靠的 Agent 工具链、更好的 system prompt 工程来维持溢价。
这场竞赛远没有结束。但对于工程师来说,现在已经是认真考虑混合策略的时候了。不是”选 A 还是选 B”,而是”A 和 B 各自在什么场景下发挥最大价值”。答案会随着每一代模型的发布而变化——但这种变化的方向,是越来越对本地有利的。
参考来源:
- Simon Willison: Local LLMs — Qwen3.6-35B-A3B vs Claude Opus 4.7 pelican test, Dan Woods streaming experts experiment, Gerganov’s harness fragility comments
- Gemma 4 Model Card — 26B-A4B benchmark results (AIME 88.3%, LiveCodeBench 77.1%)
- Qwen3 Technical Report — MoE architecture details, 128 experts / 8 active routing
- llama.cpp Apple Silicon Performance — M-series chip inference benchmarks
- ggml.ai joins Hugging Face — Toolchain consolidation announcement (Feb 2026)