
🎲推荐系统系列之推荐系统概览
type
Post
status
Published
date
slug
summary
tags
文字
开发
思考
广告
category
技术分享
icon
🎲
password
Status
完成
在当今信息化高速发展的时代,推荐系统是一个热门的话题和技术领域,一些云厂商也提供了推荐系统的SaaS服务比如亚马逊云科技的Amazon Personalize来解决客户从无到有迅速构建推荐系统的痛点和难点。在我们的日常生活中,推荐系统随处可见,比如我们经常使用的亚马逊电商购物,爱奇艺视频,美团外卖,抖音短视频以及今日头条新闻,主播直播平台等等。我根据这几年参与的推荐系统和计算广告项目总结了一些实践经验并以推荐系统系列文章的形式分享给大家,希望大家看后对推荐系统有更全新更深刻的理解。这个系列文章包括:推荐系统概览,推荐系统中的召回阶段深入探讨,排序任务的样本工程,排序模型调优实践。更多细节以及更详细的内容可以参考我的github repo。
我们先介绍推荐系统概览,大致内容如下:
- 推荐系统简介
- 推荐系统中常见概念
- 推荐系统中常用的评价指标
- 首页推荐场景的通用召回策略
- 详情页推荐场景的召回策略
- 排序阶段常用的排序模型
- 重排阶段
- 推荐系统的冷启动问题
- 推荐系统架构
推荐系统简介
推荐系统可以分为广义推荐系统和狭义推荐系统(我们在今后的讨论只是关注狭义的推荐系统),参考下表:
特点 | 举例 | |
广义推荐系统 | 给某个人推送/引荐/分配某个物 | 化妆产品套装推荐;
智能派活;
APP/应用中的广告推送;
游戏礼包推荐 |
狭义推荐系统 | 从海量的物品池中挑出当前用户感兴趣的物品 | 电商商品推荐;
电影推荐;
音乐推荐;
主播频道推荐;
新闻资讯推荐 |
推荐系统就是根据用户的历史行为、社交关系、兴趣点、所处上下文环境等信息去判断用户当前需要或感兴趣的物品/服务的一类应用。推荐系统本身是一种信息过滤的方法,与搜索和类目导航组成三大主流的信息过滤方法。我们可以从不同的角度看推荐系统的用处:对用户而言,推荐系统能帮助用户找到喜欢的物品/服务,帮忙进行决策;对服务提供方而言,推荐系统可以给用户提供个性化的服务,提高用户信任度和粘性,增加营收。据说,Netflix有2/3 被观看的电影来自推荐系统,Google新闻有38%的点击量来自推荐系统;Amazon电商有35%的销量来自推荐系统的推荐。
对于很多人(包括曾经的我)常犯的一个观念错误是,推荐系统的工程实现与计算广告的工程实现是类似的,其实两者的实现差别很大,见下表:
ㅤ | 计算广告 | 推荐系统 |
召回方法 | 主要是基于广告主设置的定向条件来召回
(计算广告的召回/匹配的条件是判断广告自身的定向设置、时段设置、素材尺寸是否和当前请求的用户属性、请求时间、广告位规格相匹配) | 一般都是基于各种策略做召回,而没有基于类似广告中的定向条件的召回。 |
排序公式 | 竞价计算广告的排序公式会考虑biding价格,还可能有复杂的动态排序因子。 | 不涉及到价格因素 |
重排阶段 | 一般没有重排阶段 | 重排阶段会引入运营干预策略来影响最后的推荐列表的生成 |
延迟 | DSP平台收到竞价请求到给出竞价结果的总延迟可能需要在10ms内 | 从收到请求到给出推荐列表的总延迟可能需要在100ms内 |
架构模式 | 由于更严格的延迟要求,架构常常是All in one process方式(即所有逻辑包括广告召回/匹配,过滤以及排序都在一个Ad server中处理) | 可以选择是All in one process方式或者解耦方式(解耦方式是指把逻辑中的两个部分召回和排序分别用单独的服务来处理, Rec server分别与这两个服务交互) |
推荐系统中常见概念
推荐系统常见的场景:首页推荐(更强调以用户为中心)和详情页推荐(更强调以物品为中心)。
个性化推荐与非个性化推荐: 个性化推荐几乎是当前主流的,是针对每个用户做不同的推荐即千人千面。首页推荐都会考虑个性化,详情页推荐也越来越考虑个性化了。非个性化推荐的常见方法有:整个大盘历史排行榜推荐(比如1年内的,1个月内的,1个星期内的);每个类目历史排行榜推荐(比如1年内的,1个月内的,1个星期内的);周期性与节日有关的推荐(比如国庆黄金周和圣诞假期的物品推荐);突发事件相关的推荐(比如与突发传染疾病相关的物品推荐);最新发布的物品的推荐(比如1周内)。
推荐系统的产品形态:物品即item的曝光形式(比如上下翻页,左右翻页以及他们的混合方法);曝光分区的编排(就一种推荐方法,比如个性化TOP-N推荐,可以考虑把其他方法作为召回策略纳入个性化TOP-N推荐的召回阶段;多种推荐方法,Netflix的首页推荐每一行对应一个推荐方法(它的每一行都可以左右翻页来浏览电影item),这个也叫分区混合推荐。比如一行是独家播放推荐,一行是热门推荐,一行是新品推荐,一行是个性化TOP-N推荐)。为了行文方便,我们对后面的讨论做个假设:只用个性化推荐方法,其他方法都作为个性化推荐的召回策略。
召回阶段,排序阶段和重排阶段:他们是个性化Top-N推荐整个流程的三个细分阶段。不同的场景下(比如是首页推荐还是详情页推荐),针对不同种类的用户(即是否是长尾和冷启动用户)并不是三个阶段都需要,具体讨论我们会在这个系列文章的另一篇《推荐系统中的召回阶段深入探讨》中涉及。重排阶段有很多叫法,比如模型后处理阶段或者业务运营干预阶段。
探索与利用:探索指的是想挖掘用户的一些从行为上无法反应的一些爱好相关的物品;利用指的是推荐系统根据用户历史行为学习到的知识并预测出概率高的用户可能感兴趣的物品。对于冷启动的物品和长尾的物品,在重排阶段做探索是一种常见的方法。实践中,经常会有一些固定的曝光位置专门留给冷启动的物品和长尾的物品。
离线推荐与线上推荐:所谓的离线推荐,指的是推荐的结果列表是离线的时候就预计算好并存储在某个memory-based 的NoSQL(比如Amazon ElastiCache for Redis)中,当用户请求来的时候直接从NoSQL中取出;所谓的线上推荐,指的是当用户请求来的时候系统根据规则,策略或者模型的组合来临时生成推荐列表。
离线召回与线上实时召回:所谓的离线召回,指的是离线的时候提前把需要召回的item候选集合预计算好并存储在某个memory-based 的NoSQL中;所谓的线上实时召回,指的是当用户请求来的时候,召回服务临时根据某种逻辑(比如走模型得到一个实时的用户兴趣向量,然后用这个用户兴趣向量去向量检索库找到topK相似的item向量)来得到的召回候选集。
电商付费类推荐系统与新闻/电影/视频等内容消费类推荐系统的召回策略是有区别的。对于首页推荐的场景,他们的召回策略或者推荐方法可能区别不大。对于详情页推荐的场景,他们的召回策略有很大区别,新闻/电影/视频等内容消费类推荐系统,可能把基于物品表示向量相似度的推荐方法得到的列表放在更有利的曝光位置或者给予基于物品表示向量相似度的召回策略最高优先级会更好(因为对于内容消费类的场景,用户更偏好的是物品内容本身的相似);而对于电商付费类推荐系统来说,可能需要比内容消费类推荐系统更多的推荐方法或者召回策略,比如基于物品的关联推荐方法或者召回策略可能在电商详情页推荐中就是必须有的,但是在内容消费类推荐系统中就是可选项,比如“经常一起购买的商品”的关联推荐,和/或者“浏览此物品的用户也同时浏览”的关联推荐(因为在这个场景下,当前用户除了关注详情页物品,接下来可能还感兴趣与该物品经常一起出现的其他物品)。
电商付费类推荐系统,可能还会有购物车页面推荐以及付费完成页面推荐这样的场景。对于这样的场景,可能把用关联推荐方法得到的列表放在更有利的曝光位置或者给予关联推荐召回策略最高优先级会更好,而基于物品item表示向量相似度的召回策略或者推荐方法可能在这个场景下就不太合适了,也就是说在当前购买意图很确定的情况下,用户更偏好的是物品之间的共现,因为用户很可能并不想马上再买一个物品内容很相似的物品。
推荐系统中常用的评价指标
评价指标主要分两种: 线上业务评价指标和离线评价指标。一般来讲, 线上业务评价指标更重要(经常需要多个指标一起看),它包括转化类指标(比如转化率,点击率, GMV成交总额等等)和内容消费满意度指标(比如留存率,停留时长,观看时长等等)
离线评价指标中,最常用的指标是AUC以及GAUC,尤其是AUC。AUC细分为AUC-ROC和AUC-PR,AUC-ROC可能更常用。AUC-ROC是指随机给定一个正样本和一个负样本,分类器输出该正样本为正的那个概率值比分类器输出该负样本为正的那个概率值要大的可能性。GAUC (Group AUC)是计算每个用户的AUC,然后加权平均,最后得到Group AUC,实际处理时权重一般可以设为每个用户view或click的次数,而且需要过滤掉单个用户全是正样本或负样本的情况,具体公式参考如下:
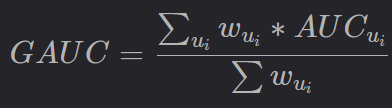
离线的时候,AUC和GAUC两个指标最好都关注。实践中,不要太刻意追求离线验证集的很高的AUC,太高的验证集的AUC可能表示模型过拟合到这个验证集了,线上效果可能会很差。一般离线的AUC可能在0.7~0.85之间就可以上线。
首页推荐场景的通用召回策略
基于热度/流行度/排行榜的召回策略
可以从两个维度来组合:统计周期和物品item的顶级类目。比如统计一段时间内同类目的所有Item的评价次数以及该Item的平均评分,根据评分来进行排序,由于不同Item的评价次数可能差别很大,直接基于平均评分来排序效果不好。为了公平起见,采用加权的评分更合理,可以参考如下的公式:v是某Item参与评分的用户的个数,m是筛选的评分用户个数阈值,即如果某个item评分的用户个数低于阈值则该item将被忽略(比如采用评分用户个数的20%分位数来决定该阈值),R是该item的评分均分,C是所有item的平均分。
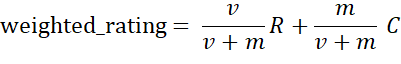
基于物品画像的召回策略
所谓的物品画像指的是对物品本身的某一方面的刻画。比如物品的品牌,物品的价格,物品所属的类目等这些都称为物品的画像,这些画像有明显的物理含义,我们把它们称作显式画像;如果通过某个模型把物品item id的“黑知识”学习到,这个黑知识我们称为embedding,这个embedding是不可解释的,我们把它称作隐式画像。从显式画像和隐式画像角度来看,基于物品画像的召回策略自然而然分为:基于物品内容的召回和基于物品的整体embedding的召回。
ㅤ | 基于物品内容的召回 | 基于物品整体embedding的召回 |
原理 | 基本假设是用户喜欢的是与自己发生过正向行为的Item在内容上类似的那些Item。
核心是计算Item之间的内容相似度 | 核心是计算物品 embedding向量之间的相似度 |
计算过程 | 1.为每个item抽取出一些特征来表示此item(包括结构化表示和非结构化表示);
2. 利用用户过去喜欢(及不喜欢)的item的特征向量,来学习或者计算出此用户喜好即profile向量;
3. 通过比较上一步得到的用户profile向量与候选item的特征向量,为此用户推荐一组相关性最大的item。 | 1. 首先通过某个模型获得某个item的embedding向量表示;
2. 通过与用户近期发生过行为的那些item的embedding的聚合(比如向量相加或者平均)来得到该用户的embedding向量;
3. 最后计算用户的embedding与其他没有发生过行为的item embedding的相似度并排序。 |
在首页推荐场景中的基于物品画像的召回是基于当前用户的稠密行为(稠密行为的意思就是用户对很多物品而不只是3,4个物品都有过行为)来做的,这个与后面将要介绍的详情页推荐场景中常见的基于物品item表示向量相似度的召回不用考虑当前用户的稠密行为有很大区别。对于基于物品内容的召回过程,物品item的结构化表示和非结构化表示不要直接拼接并用来计算向量间的相似度,因为它们不是来自同一个空间的表达。如果要计算表示向量的相似度的话,最好作为item的两个不同的表示并作为两路不同的召回策略;如果是基于监督模型来对用户喜好进行分类建模,结构化表示和非结构化表示可以一起作为特征建模到模型中。
基于协同过滤的召回策略
这个方法是仅仅基于用户行为数据设计的,即基于User-Item矩阵或者由user和item构成的图,不包括任何的其他特征。本质上是矩阵补全的思路,也正是因为基于矩阵的处理,只要用户或者Item有变化,甚至action有变化,可能需要重新计算或者重新训练(业界当前有一些方法做增量协同过滤或者近实时协同过滤)。基于协同过滤的召回策略,细分为如下三种方式:基于用户的协同过滤/UserCF;基于物品的协同过滤/ItemCF;基于模型的协同过滤。
- 基于用户(user-based)的协同过滤,核心思想是首先根据相似度计算出目标用户的邻居集合,然后用邻居用户评分/交互的加权组合来为目标用户作推荐。 通常分为三步:首先使用所有用户的item评分/交互矩阵来计算目标用户与其他用户之间的相似度(利用Pearson相关系数、余弦相似度等方法);然后选择与目标用户相似度最高的K个用户;最后通过对邻居用户的评分/交互的加权求和来预测目标用户对每个他自己没有评过分/交互的Item的评分/感兴趣程度。这里的加权指的是用用户之间的相似度作为评分/交互的权重,如下图公式中的sim(u,ui)。
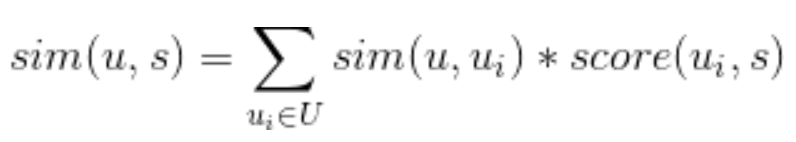
上面公式中的U表示的是目标用户u的邻居用户集合(即topK相似的用户集合),s表示的是用户-物品交互矩阵中出现过的item并且被邻居用户交互过且没被目标用户交互过的item。score(ui,s)是用户ui对物品s的喜好度, 对于隐式反馈为1( 只要不是用户直接评分的操作行为都算隐式反馈,包括浏览、点击、播放、收藏、评论、点赞、转发等等 ),而对于非隐式反馈,该值为用户对物品的评分。
UserCF的主要缺点是随着网站的用户数目越来越大,其运算的时间复杂度和空间复杂度随着用户的增长而爆炸性增长。新闻/资讯/知识类网站一般会使用user-based的CF来召回,由于这些类网站的文章更新太快太多,可能不适合用item-based的CF。
- 基于物品(item-based)的协同过滤,核心是基于Item-Item共现矩阵通过某种相似度度量来计算两个Item的相似度,区别于基于内容的推荐方法,这里不需要对Item的特征本身建模,完全是基于用户对Item的行为历史数据。方法主要分三步:首先需要构造item-item共现矩阵,遍历训练数据,计算出喜欢两两物品的用户数,填入矩阵中。然后计算物品之间的相似度,需要惩罚热门物品以及惩罚活跃用户,公式如下:
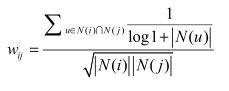
根据物品的相似度和用户的历史行为给用户生成推荐列表:

上式中的S表示的是训练集中出现的物品集合;i是用户u发生过行为且出现在训练集中的物品;
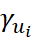
指的是目标用户u对物品i的评分(显式反馈就是用户的具体评分,隐式反馈的话这个值就是1)。
ItemCF它可能是目前业界应用最多的一种召回策略。比如Amazon电商,Netflix在线视频等网站,他们的首页推荐中经常会使用ItemCF作为其中一路召回。
- 基于模型(model-based)的协同过滤,区别于上面两种基于邻域的方法,基于模型的CF使用传统机器学习进行建模。比如SVD及其变体,图模型比如SimRank等。SVD及其变体是基于user-item矩阵来进行矩阵分解的, 它们把User-Item评分矩阵分解为两个低秩矩阵的乘积,这两个低秩矩阵分别为User和Item的隐向量集合,通过User和Item隐向量的点积来预测用户对未见过的物品的兴趣,从这个角度来说,矩阵分解也是生成embedding表示的一种方法。
基于用户画像的召回策略
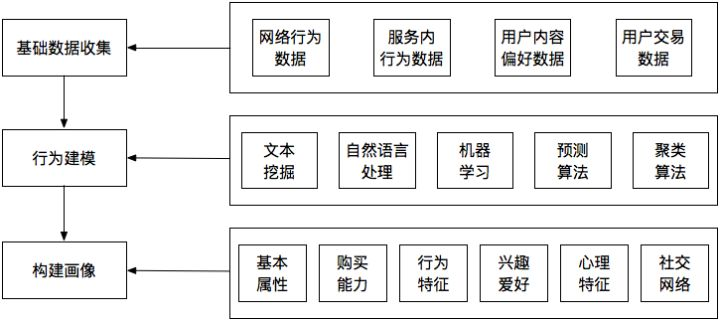
简单讲,用户画像就是为用户打标签tag。打标签的重要目的之一是为了让人能够理解并且方便计算机处理。基于用户画像的召回是个性化推荐中的精髓,因为个性化就是通过用户画像来体现的。用户画像包括如下的三大类:
类别 | 举例 |
用户的基本人口统计信息 | 性别,年龄,常驻的国家/省/市,出生的国家/省/市,学历,职业,收入水平等(注意这些信息的真实性) |
兴趣画像 | 用户的兴趣tag,兴趣topic,兴趣关键字,兴趣entity等 |
行为画像 | 用户最近N次或者最近某段时间的某个行为的item id列表;
一周内用户的某行为的次数;用户的消费水平;一个月内用户的点击率/转化率等
当前一种流行的做法是基于用户实时embedding的召回,比如常见的YoutubeDNN召回模型,DSSM,MIND等 |
用户画像的大致实现思路参考如下:
详情页推荐场景中的通用召回策略
详情页推荐场景中的通用召回策略包括(最常用的是前两种):基于item表示向量的相似度的召回;基于item关联规则的召回;基于item表示向量聚类的召回。
- 基于item表示向量的相似度的召回,常见的item表示方法如下:物品item的显式画像的表示;物品item的整个embedding向量的表示;用户-物品交互矩阵中item对应列向量的表示(假设用户是行,物品是列)
- 基于item关联规则的召回(常用在电商中的购物车页面推荐或者购买页面推荐中),找出所有用户购买的所有物品数据里频繁出现的Item序列,来做频繁集挖掘,找到满足支持度(即两个商品被同时购买的概率)阈值的关联物品。关联规则分析中的关键概念包括:支持度(Support),它是两件商品(A∩B)在总销售笔数(N)中出现的概率,即A与B同时被购买的概率;置信度(Confidence),它是购买A后再购买B的条件概率;提升度(Lift),它表示先购买A对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。
在进行召回的时候,经常需要构建索引。对所有的用户进行索引是非常耗存储和费时的,所以在构建索引的时候,可能选择月活用户来构建索引是合适的。在做实时召回的时候,用户的行为序列特征除了可以考虑推荐业务相关的行为,还可以考虑同一个应用的其他形态比如用户在搜索业务中的行为。比如YoutubeDNN召回模型的特征,除了有用户最近观看过的video id序列/video embedding,还有该用户最近搜索过的word序列或者word的embedding。作者提到加入搜索业务的用户行为对整个效果提升不错。有意思的地方是YoutubeDNN排序模型并没有把用户最近搜索过的word序列或者embedding建模进来。
排序阶段常用的排序模型
排序阶段目前主流的都是基于传统机器学习或者深度学习的模型,排序模型的研究一直都是推荐系统领域的热点,国内外大厂都在这个领域大展拳脚。当前的排序模型有如下趋势:引入行为序列特征;引入注意力机制(比如DIN,DIEN等);引入多任务/多目标(比如ESMM,MMOE,ESMM2,PLE等);引入多模态。下面我们介绍几个常见的简单排序模型。
- LR逻辑回归模型,它是CTR预估排序任务早期使用最多的模型。LR的预测函数如下:
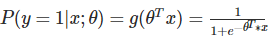
LR模型的优点是简单方便,易解释。LR模型的缺点是使用LR的时候,一般会把离散特征变成one-hot向量,这样就容易导致整个特征向量变成高维稀疏向量,从而使学习难度增大。LR本质上是线性的,如果需要建模与目标变量非线性的关系,需要人工引入特征交叉来表示,因而相对于其他模型,需要更多的人工特征工程。目前为止,LR在排序阶段的主要使用场景有两个地方:排序阶段的第一个模型;把LR模型作为排序阶段的benchmark或者AB test中的某个分桶。
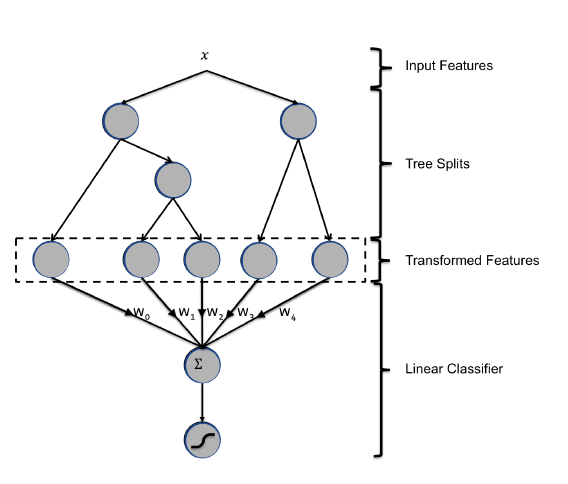
- GBDT+LR级联模型(具体可以参考Facebook的论文),思路是用GBDT对所有的原始特征进行编码,然后把得到的编码结果送入级联的LR做分类。本质上是利用GBDT自动进行特征筛选和组合,它的一个变体是GBDT+FM模型,利用FM来替换LR。
- FM因子分解机模型(参考博客),它是在深度排序模型流行之前,使用的比较多的排序模型。FM一般需要把category特征包括ID类特征都要变成one-hot向量,因此维度会很高(下图中的例子是针对3个user,3个item的情况) 。爱奇艺使用用户的观看历史以及兴趣标签代替user id,降低了特征维度,并且因为用户兴趣是可以复用的,同时也提高了对应特征的泛化能力。
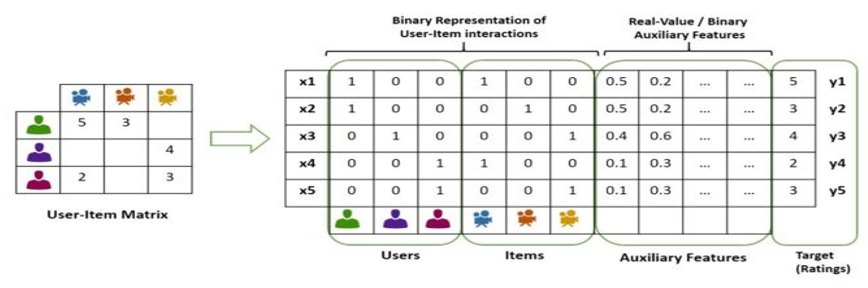
FM可以看作是Matrix Factorization(MF,矩阵分解)的进一步拓展,除了User ID和Item ID这两类特征外,很多其它类型的特征都可以进一步引入FM。FM自动计算特征二阶交叉,它将所有这些特征转化为embedding低维向量表达,并计算任意两个特征embedding的内积,作为这两个特征组合的权重。
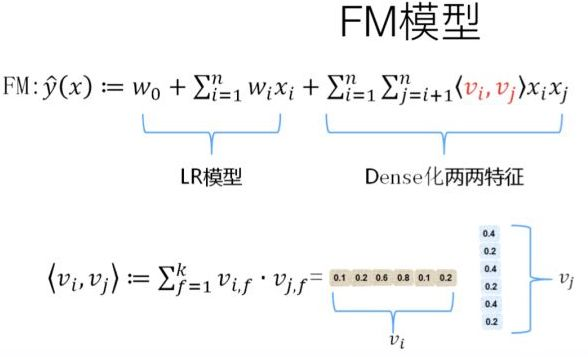
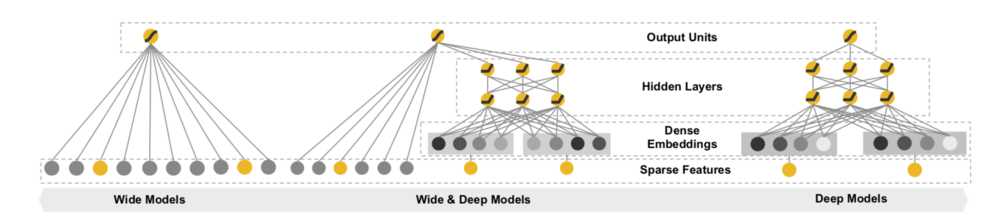
- Wide & Deep networking Learning (WDL)模型,它本质是上结合LR和MLP,当前在业界用的比较多。Wide 部分即LR体现的是记忆功能,Deep部分即MLP体现的是泛化功能,二者互补能提供更好的性能。区别于GBDT+LR/FM(需要分别独立训练GBDT和LR/FM),WDL是端到端联合训练。WDL能方便的建模用户的行为序列作为一个单独的特征。WDL开创了在深度排序模型中结合wide部分和deep部分联合建模的热潮。WDL中的wide部分是需要做手工的交叉特征的,这个是它的缺点(WDL模型之后,出了很多变体比如DeepFM,Deep & Cross networking learning等,它们的核心目的都是通过设计网络结构自动进行特征交叉)。他的网络结构如下:
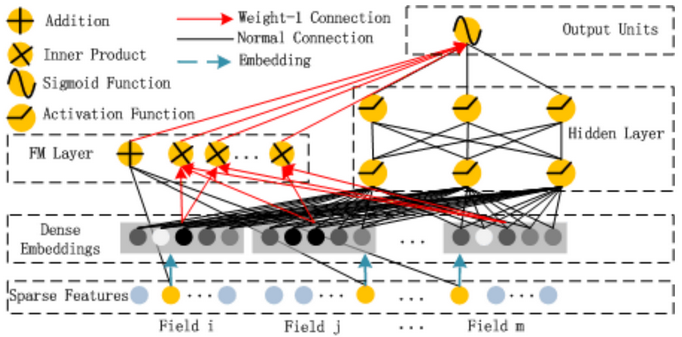
- DeepFM模型,它是结合FM部分和MLP部分,不需要人工做特征二阶交叉组合(这个模型在国内客户中使用挺多的)。它的网络结构如下图所示:
重排阶段
重排阶段主要就是业务运营人员用各种策略/规则进行干预。从对终端用户的推荐效果来讲,这个阶段我认为比排序阶段还要重要。重排主要从以下几个方面来进行干预(参考博客):
干预方式 | 简介 |
优选物品的曝光 | 目的是给优质的物品更多的曝光机会。(首页推荐一般会考虑) |
探索与利用 | 探索的目的是为了发现用户可能更多的兴趣点以及给长尾物品和冷启动物品更多的曝光机会。需要确定探索和利用的比例,这个比例可能会随着时间来动态变化。(详情页推荐一般不考虑探索) |
曝光位置的编排 | 考虑是否做分区混合推荐以及每个分区曝光位置安排;是否给长尾物品和冷启动物品固定曝光位置;是否有其他形式比如广告和推荐列表的混排。
首页推荐场景下,尤其要仔细考虑曝光位置如何编排,这个的效果可能比优化模型以及数据本身更好。 |
结果的多样性 | 为了满足用户广泛的已知兴趣,推荐列表需要能够覆盖用户不同的兴趣领域,即推荐结果需要具有多样性,不能简单的返回topN结果给用户。(首页推荐一般会考虑) |
结果的新颖性 | 指的是向用户推荐非热门非流行物品的能力 。评测新颖度最简单的方法是利用推荐结果的平均流行度,因为越不热门的物品,越可能让用户觉得新颖。(首页推荐一般会考虑) |
结果的信任度 | 增加系统透明度,提供推荐解释,让用户了解推荐系统的运行机制。可以利用社交网络,通过好友信息给用户做推荐即通过好友进行推荐解释。 |
结果的时效性 | 在很多网站中,物品(新闻、微博等)具有很强的时效性,需要在物品还具有时效性时就将它们推给用户。 比如,给用户推荐昨天的新闻显然不如给用户推荐今天的新闻。另外,新加入系统的物品应该尽快推荐给用户。 |
过滤 | 为了更好的用户体验,过滤这个操作很重要。过滤操作在重排阶段和召回阶段都需要(由于重排阶段可能会加入一些优选item和长尾/冷启动item,因此需要在召回阶段过滤后,在重排阶段仍然做过滤)。
举例:
比如把用户最近刚买过的商品以及类似的商品从推荐列表中去掉(注意同样的商品可能同一个用户过一段时间也可能会再买,所以这个过滤时间段的设置要根据不同的业务场景来决定);
比如把用户一个小时前点击过的文章从推荐列表中去掉;
比如把用户一分钟前点击过的商品从推荐列表中去掉(注意对于购物网站的同一个商品,即使用户之前点击过该商品,也可能需要多次曝光给他,他才可能下单购买,所以这个过滤的时间间隔不能太长);
比如把用户加入黑名单,选择“不喜欢”或者点“踩”的物品从推荐列表中去掉等等(这里用户已经给出了负反馈)。 |
推荐系统的冷启动问题
推荐系统冷启动问题分为如下三类:
分类 | 介绍 |
用户冷启动 | 即如何给第一次使用该应用的用户做推荐 |
物品冷启动 | 即如何将新上线的物品推荐给可能对它感兴趣的用户 |
系统冷启动 | 即如何在一个新开发的网站(没有用户,没有用户行为,只有部分物品信息)上设计推荐系统,从而在网站刚发布时就让用户有不错的体验。 |
针对冷启动问题,可能走专门的推荐链路效果更好,具体的方法参考如下(参考知乎博客):
方法 | 介绍 | 适用情况 |
提供非个性化的推荐 | 比如给冷启动的用户推荐热门物品,等到该用户数据积累到一定的时候,再为该用户切换为个性化推荐。 | 适用于用户冷启动 |
利用用户注册信息 | 人口统计学信息:包括年龄、性别、职业、民族、学历和居住地等;
用户兴趣的描述:有些网站可能会让新注册的用户用文字或者下拉菜单来描述或者选择兴趣;
从其他网站导入的用户站外行为:比如用户利用社交网站账号登录,就可以在获得用户授权的情况下导入用户在该社交网站的部分行为数据和社交网络数据或者其他用户画像数据。 | 适用于用户冷启动 |
选择合适的物品启动用户的兴趣 | 启动物品集合需要有多样性:在冷启动时,我们不知道用户的兴趣,而用户兴趣的可能性非常多,为了匹配多样的兴趣,我们需要提供具有很高覆盖率的启动物品集合,这些物品能覆盖几乎所有主流的用户兴趣;
具有代表性和区分性:启动用户兴趣的物品不能是大众化或老少咸宜的,因为这样的物品对用户的兴趣没有区分性;
启动的物品是比较热门的。 | 适用于用户冷启动 |
利用物品的内容信息 | 将新的物品先投放给曾经喜欢过和它内容相似的其他物品的用户。 | 适用于物品冷启动 |
开设新品专区 | 很多内容消费类网站使用这个方法。 | 适用于物品冷启动 |
采用专家知识 | 利用专家知识库来提供条件搜索;
建立物品标签体系,从而提供类目导航(本质上是利用搜索和类目导航) | 适用于系统冷启动 |
推荐系统架构
一个好的推荐系统架构应该具有下面这些特点:实时响应请求;及时、准确、全面记录用户反馈(包括显示反馈和隐式反馈);可以优雅降级;快速实验多种策略和多种模型。
线上推荐的架构的两种模式:All in one process方式,即所有逻辑包括召回,排序,重排都在一个Recommendation server中处理;解耦方式,即把逻辑中的两个部分召回和排序分别用一个服务来处理, Recommendation server分别与这两个服务交互。
工业级推荐系统架构(参考自知乎博客):
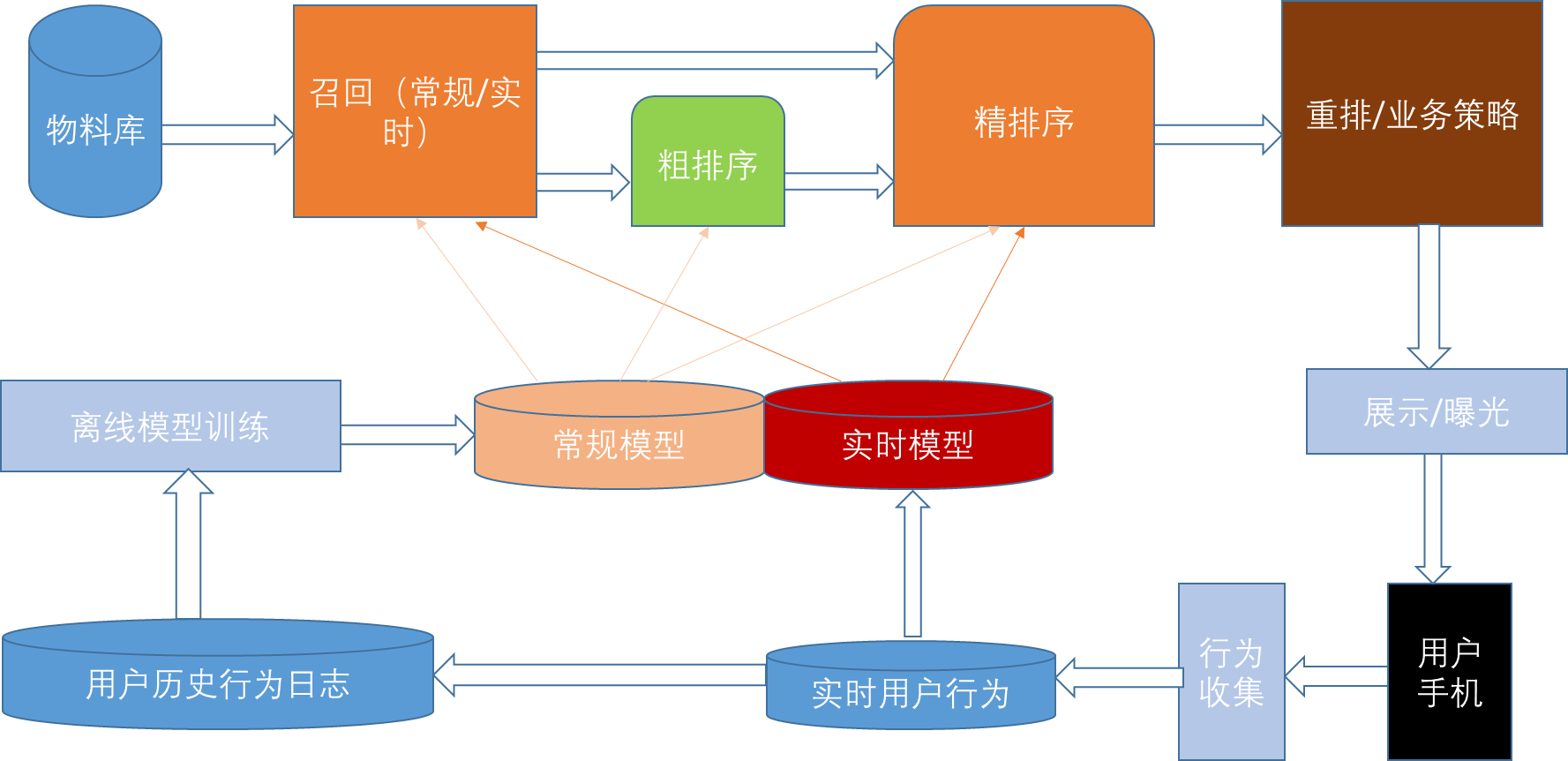
上图中的常规模型指的是周期离线训练并更新为线上的模型;上图中的实时模型指的是实时收集用户行为反馈,并选择训练实例,实时抽取拼接特征,并近乎实时地比如分钟级别更新在线推荐模型。这样做的好处是用户的最新兴趣能够近乎实时地体现到推荐结果里。这里的常规模型和实时模型共存的原因可能是某路召回模型或者排序模型没有办法做增量训练或当前常规模型和实时模型处于A/B Test部署中,或者常规模型作为fallback选择。
Netflix的个性化推荐系统架构(2013年)如下图(参考自Netflix官方博客):
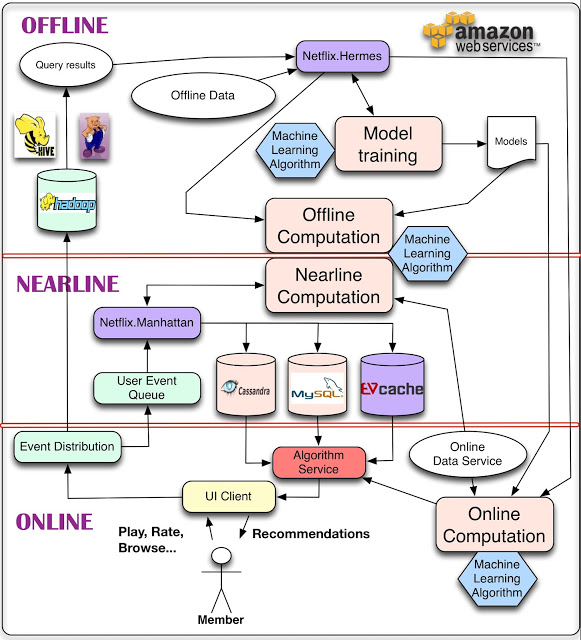
Netflix的推荐系统分为离线,近在线,在线三个部分。在线部分要尽可能满足低延迟的 SLA以响应实时的客户端请求。线上的召回,排序阶段的预测以及业务策略处理也属于online部分。离线部分是作为在线部分的一个fallback选项(即一种优雅降级的方法),同时它能提供一部分最终或者中间的推荐结果(比如作为一路召回或者分区混合推荐的一个分区),另外它能提供部分字段的预计算(比如用户画像和物品画像)。当然模型的离线训练也属于这个部分。近在线部分除了可以增量训练并近实时(比如分钟级别)的更新在线模型,还可以根据最新事件补充离线召回结果,以及根据用户最新浏览记录提取的兴趣标签补充到用户画像中。