🤖大语言模型智能体
type
Post
status
Published
date
slug
summary
tags
文字
开发
思考
category
技术分享
icon
🤖
password
Status
完成
智能体
自 2022 年 10 月 OpenAI 发布 ChatGPT 以来,随着后续 AutoGPT 和 AgentGPT 等项目的涌现,LLM 相关的智能体(Agent)逐渐成为近年来 AI 的研究热点和实际应用方向。本文将介绍智能体的基本概念、核心技术及其最新应用进展。
LLM Agent
大语言模型智能体(Large Language Model Agent, LLM agent) 利用 LLM 作为系统大脑,并结合规划、记忆与外部工具等模块,实现了对复杂任务的自动化执行。
- 用户请求: 用户通过提示词输入任务,与智能体互动。
- 智能体: 系统大脑,由一个或多个 LLMs 构成,负责整体协调和执行任务。
- 规划: 将复杂任务拆解为更小的子任务,并制定执行计划,同时通过反思不断优化结果。
- 记忆: 包含短期记忆(利用上下文学习即时捕捉任务信息)和长期记忆(采用外部向量存储保存和检索关键信息,确保长时任务的信息连续性)。
- 工具: 集成计算器、网页搜索、代码解释器等外部工具,用于调用外部数据、执行代码和获取最新信息。
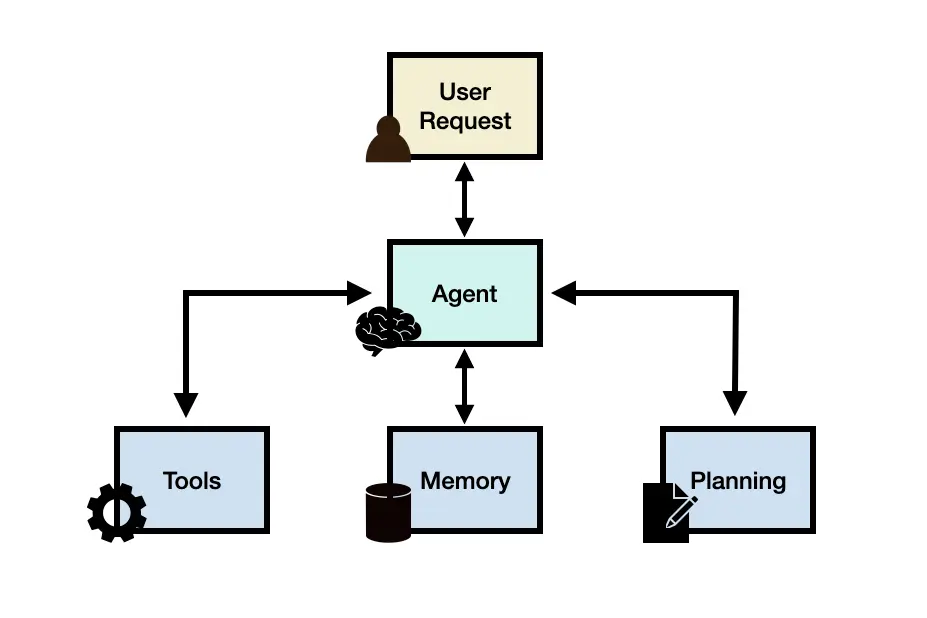
Fig. 1. The illustration of LLM Agent Framework. (Image source: DAIR.AI, 2024)
RL Agent
强化学习(Reinforcement Learning,RL) 的目标是训练一个智能体(agent)在给定的环境 (environment) 中采取一系列动作(actions, at)。在交互过程中,智能体从一个状态(state, st)转移到下一个状态,并在每次执行动作后获得环境反馈的奖励(reward, rt)。这种交互生成了完整的轨迹(trajectory, τ),通常表示为:
τ={(s0,a0,r0),(s1,a1,r1),…,(sT,aT,rT)}.
智能体的目标是学习一个策略(policy, π),即在每个状态下选择动作的规则,以最大化期望累积奖励,通常表达为:
maxπE[∑t=0Tγtrt],
其中 γ∈[0,1] 为折扣因子,用于平衡短期与长期奖励。
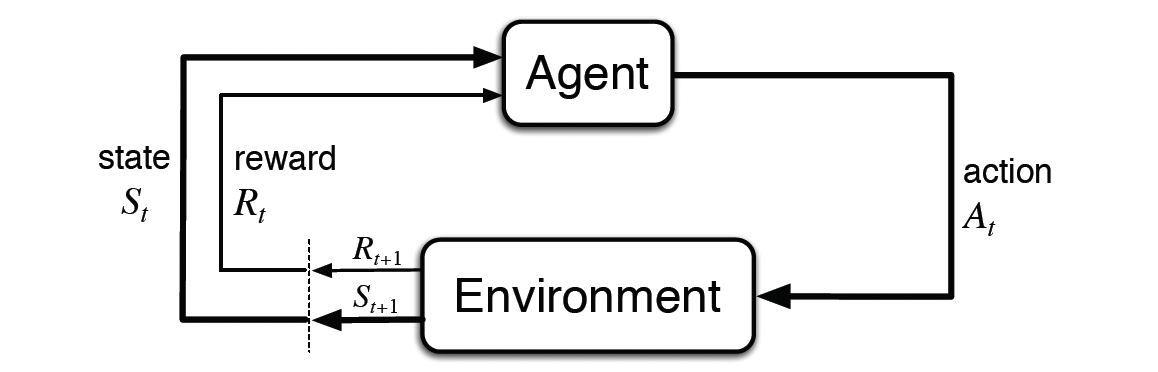
Fig. 2. The agent-environment interaction. (Image source: Sutton & Barto, 2018)
在 LLM 场景中,可以将模型视为一个智能体,而“环境”可理解为用户输入及其对应的期望回答方式:
- 状态(st):可以是当前对话上下文或用户的问题。
- 动作(at):模型输出的文本(回答、生成内容等)。
- 奖励(rt):来自用户或系统的反馈(如用户满意度、奖励模型自动评分等)。
- 轨迹(τ):从初始对话到结束的所有文本交互序列,可用于评估模型的整体表现。
- 策略(π):LLM 在每个状态下(对话上下文)如何生成文本的规则,一般由模型的参数所决定。
对于 LLM,传统上先通过海量离线数据进行预训练,而在后训练强化学习环节中,则通过人类或者模型的反馈对模型进行训练,使其输出更符合人类偏好或任务需求的高质量文本。
对比
下表展示了两者之间的差异:
对比维度 | LLM Agent | RL Agent |
核心原理 | 规划、记忆和工具实现复杂任务自动化。 | 通过与环境互动的试错反馈循环,不断优化策略以最大化长期奖励。 |
优化方式 | 不直接更新模型参数,主要依靠上下文扩展、外部记忆和工具提高性能。 | 持续频繁更新策略模型参数,依赖环境反馈的奖励信号不断优化。 |
互动方式 | 使用自然语言与用户或外部系统交互,灵活调用多种工具获得外部信息。 | 与真实或模拟环境交互,环境提供奖励或惩罚,形成闭环反馈。 |
实现目标 | 分解复杂任务、借助外部资源完成任务,关注任务结果质量与准确性。 | 最大化长期奖励,追求短期与长期回报之间的最优平衡。 |
随着研究的深入,LLM 与 RL 智能体的结合呈现出更多可能性,例如:
- 利用强化学习方法训练 Reasoning LLM(如 o1/o3),使其更适合作为 LLM 智能体的基础模型。
- 同时,记录 LLM 智能体执行任务的数据与反馈,为 Reasoning LLM 提供丰富的训练数据,从而提升模型性能。
规划: 任务分解
LLM Agent 的核心组件包括规划、记忆和工具使用,这些组件共同协作,使智能体能够自主执行复杂任务。
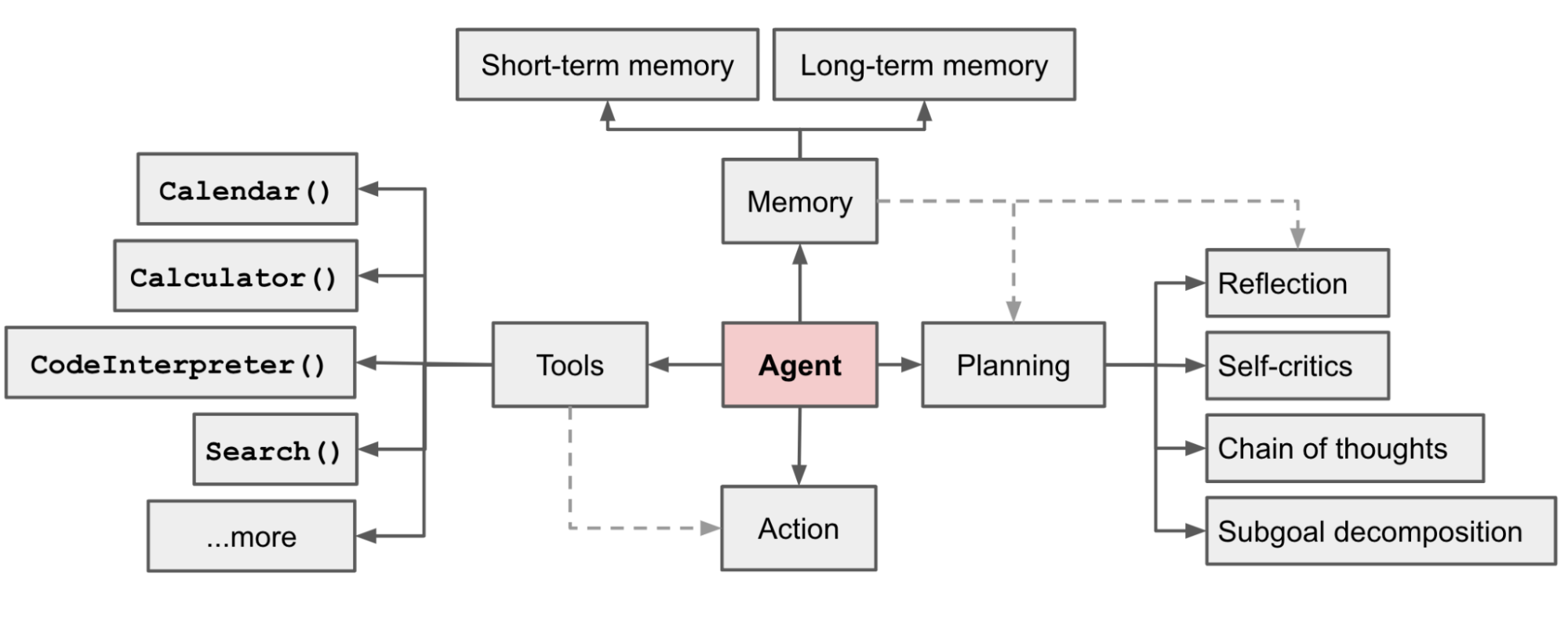
Fig. 3. Overview of a LLM-powered autonomous agent system. (Image source: Weng, 2017)
规划对于成功执行复杂任务至关重要。它可以根据复杂性和迭代改进的需求以不同的方式进行。在简单的场景中,规划模块可以使用 LLM 预先概述详细的计划,包括所有必要的子任务。此步骤确保智能体系统地进行 任务分解 并从一开始就遵循清晰的逻辑流程。
思维链
思维链(Chain of Thought, CoT) (Wei et al. 2022) 通过逐步生成一系列简短句子来描述推理过程,这些句子称为推理步骤。其目的是显式地展示模型的推理路径,帮助模型更好地处理复杂推理任务。下图展示了少样本提示(左侧)和思维链提示(右侧)的区别。少样本提示得到错误答案,而思维链方法则引导模型逐步陈述推理过程,更清晰地体现模型的逻辑过程,从而提升答案准确性和可解释性。
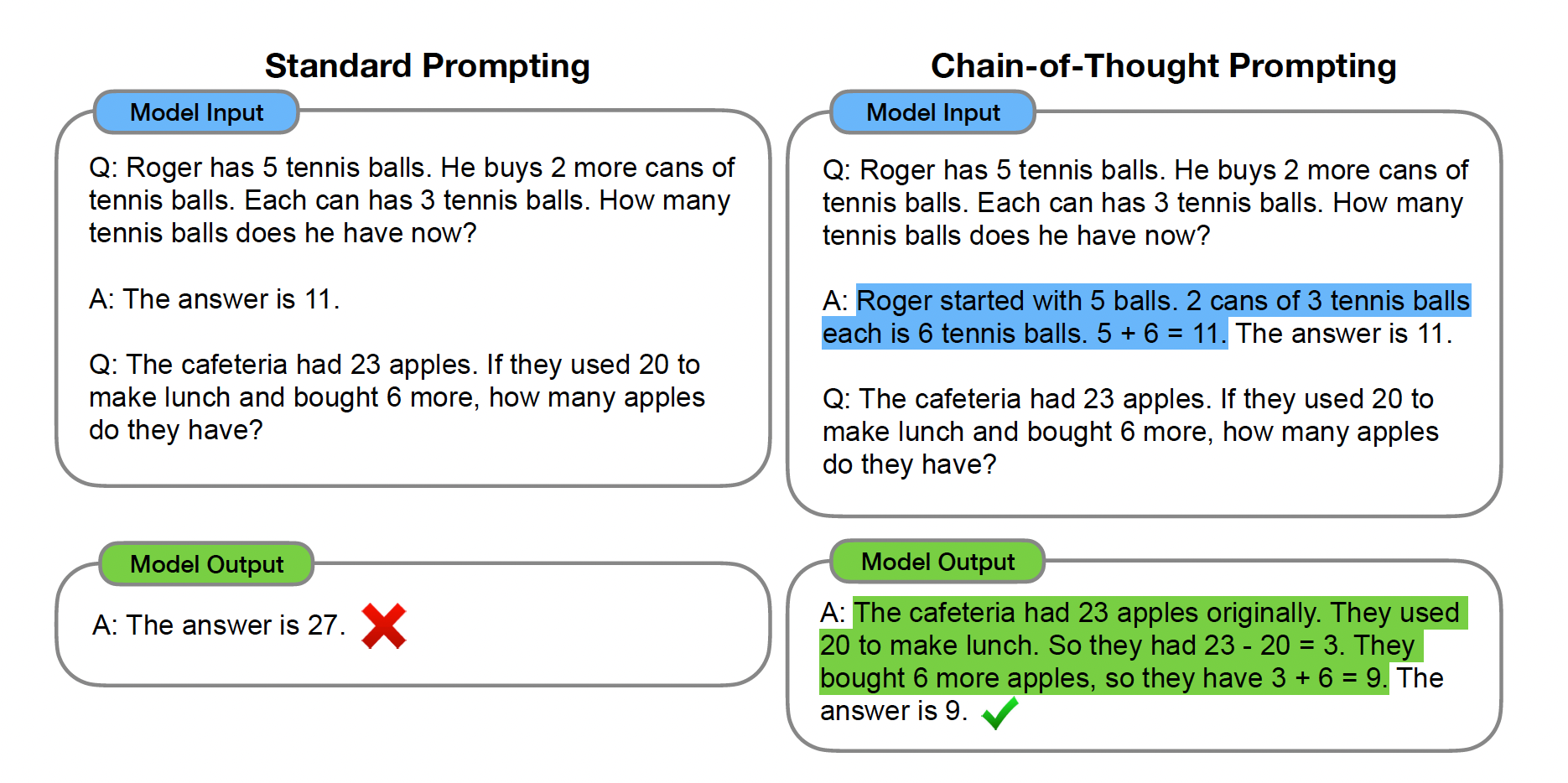
Fig. 4. The comparison example of few-shot prompting and CoT prompting. (Image source: Wei et al. 2022)
零样本思维链提示(Zero-Shot CoT) (Kojima et al. 2022)是 CoT 的后续研究,提出了一种极为简单的零样本提示方式。他们发现,仅需在问题末尾添加一句
Let's think step by step,LLM 便能够产生思维链,可以获得更为准确的答案。
Fig. 5. The comparison example of few-shot prompting and CoT prompting. (Image source: Kojima et al. 2022)
自洽采性
自洽采样(Self-consistency sampling)(Wang et al. 2022a) 通过对同一提示词在
temperature > 0 的情况下多次采样,生成多个多样化答案,并从中选出最佳答案的方法。其核心思想是通过采样多个推理路径,再进行多数投票以提高最终答案的准确性和稳健性。不同任务中选择最佳答案的标准可以有所不同,一般情况下采用多数投票作为通用方案。而对于如编程题这类易于验证的任务,则可以通过解释器运行并结合单元测试对答案进行验证。这是一种对 CoT 的优化,与其结合使用时,能够显著提升模型在复杂推理任务中的表现。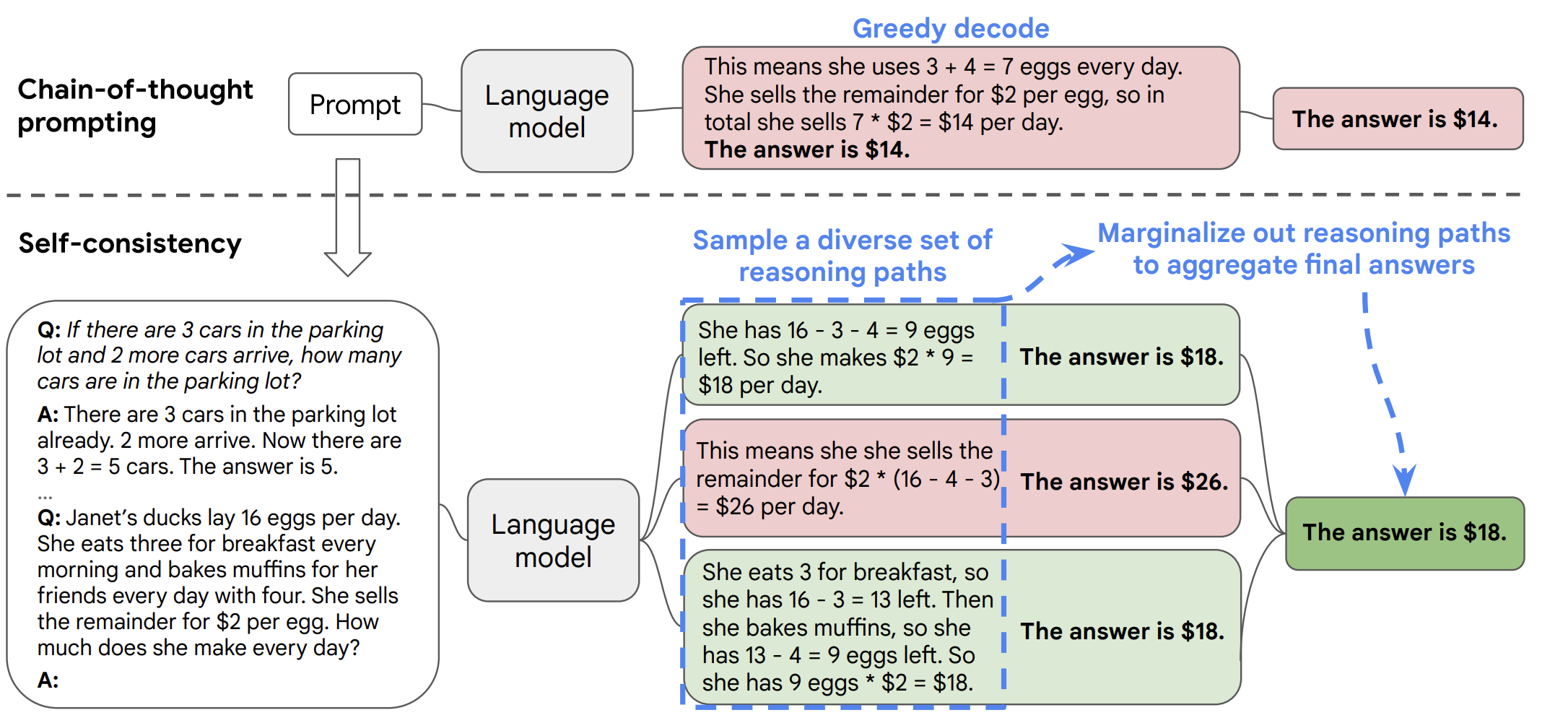
Fig. 6. Overview of the Self-Consistency Method for Chain-of-Thought Reasoning. (Image source: Wang et al. 2022a)
下面是一些后续优化的工作:
- (Wang et al. 2022b)后续采用另一种集成学习方法进行优化, 通过改变示例顺序或以模型生成的推理代替人为书写,增加随机性后再多数投票。
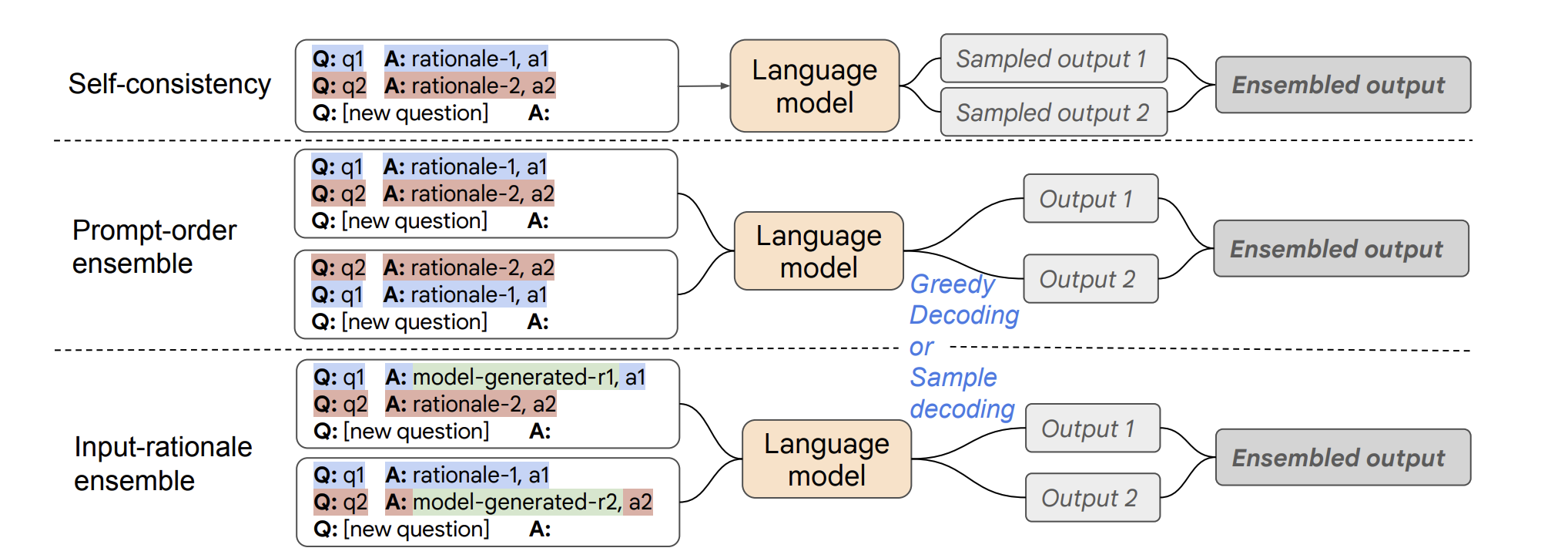
Fig. 7. An overview of different ways of composing rationale-augmented ensembles, depending on how the randomness of rationales is introduced. (Image source: Wang et al. 2022b)
- 如果训练样本仅提供正确答案而无推理依据,可采用STaR(Self-Taught Reasoner)(Zelikman et al. 2022)方法: (1) 让LLM生成推理链,仅保留正确答案的推理。 (2) 用生成的推理微调模型,反复迭代直至收敛。注意
temperature高时易生成带正确答案但错误推理的结果。如无标准答案,可考虑将多数投票视作“正确答案”。
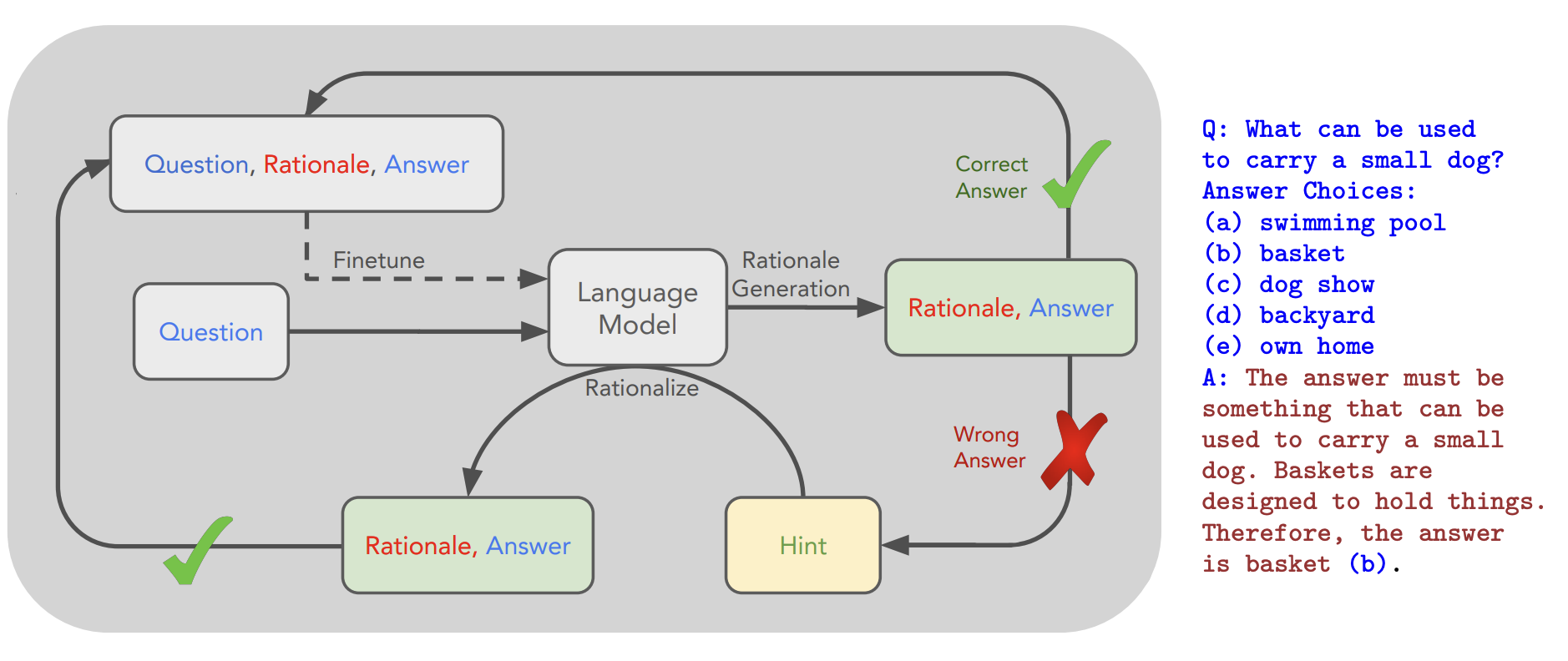
Fig. 8. An overview of STaR and a STaR-generated rationale on CommonsenseQA. (Image source: Zelikman et al. 2022)
- (Fu et al. 2023)发现复杂程度更高的示例(推理步骤更多)可提高模型性能。分隔推理步骤时,换行符
\n效果优于step i、.或;。此外,通过复杂度一致性策略(Complexity-based consistency),即仅对生成复杂度 top 的推理链进行多数投票,也能进一步优化模型输出。同时,将提示中的Q:替换为Question:也被证明对性能有额外提升。
k
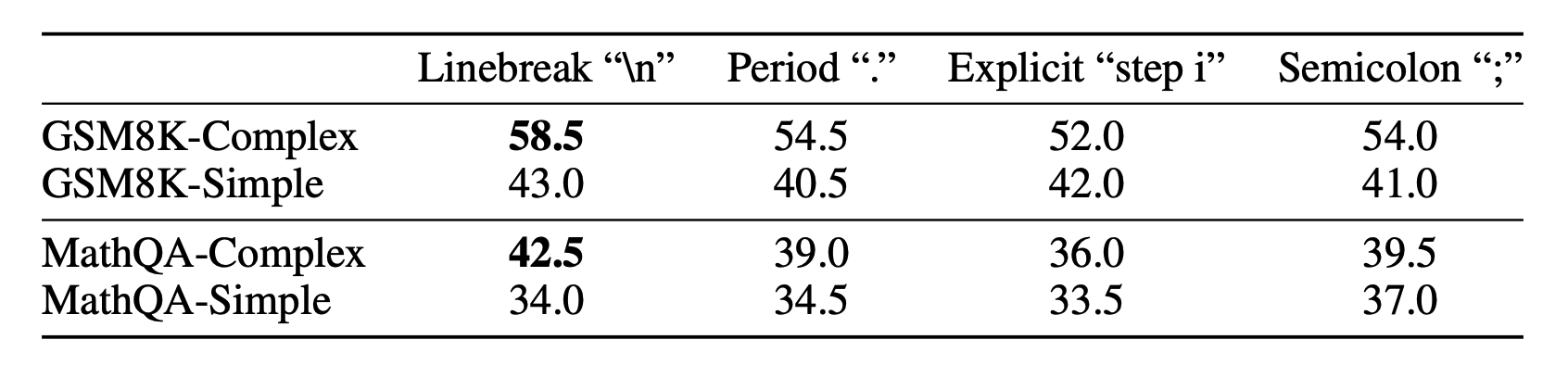
Fig. 9. Sensitivity analysis on step formatting. Complex prompts consistently lead to better performance with regard to different step formatting. (Image source: Fu et al. 2023)
思维树
思维树 (Tree of Thoughts, ToT)(Yao et al. 2023) 在 CoT 基础上拓展,每一步都探索多个推理可能性。它首先将问题分解为多个思考步骤,并在每一步产生多个不同想法,从而形成树形结构。搜索过程可采用广度优先搜索(Breadth-first search, BFS)或深度优先搜索(Depth-first search, DFS),并通过分类器(也可以让 LLM 进行打分)或多数票方式评估每个状态。它包含三个主要步骤:
- 扩展(Expand):生成一个或多个候选解决方案。
- 评分(Score):衡量候选方案的质量。
- 剪枝(Prune):保留排名 top 的最佳候选方案。
k
如果没有找到解决方案(或者候选方案的质量不够高),则回撤到扩展步骤。
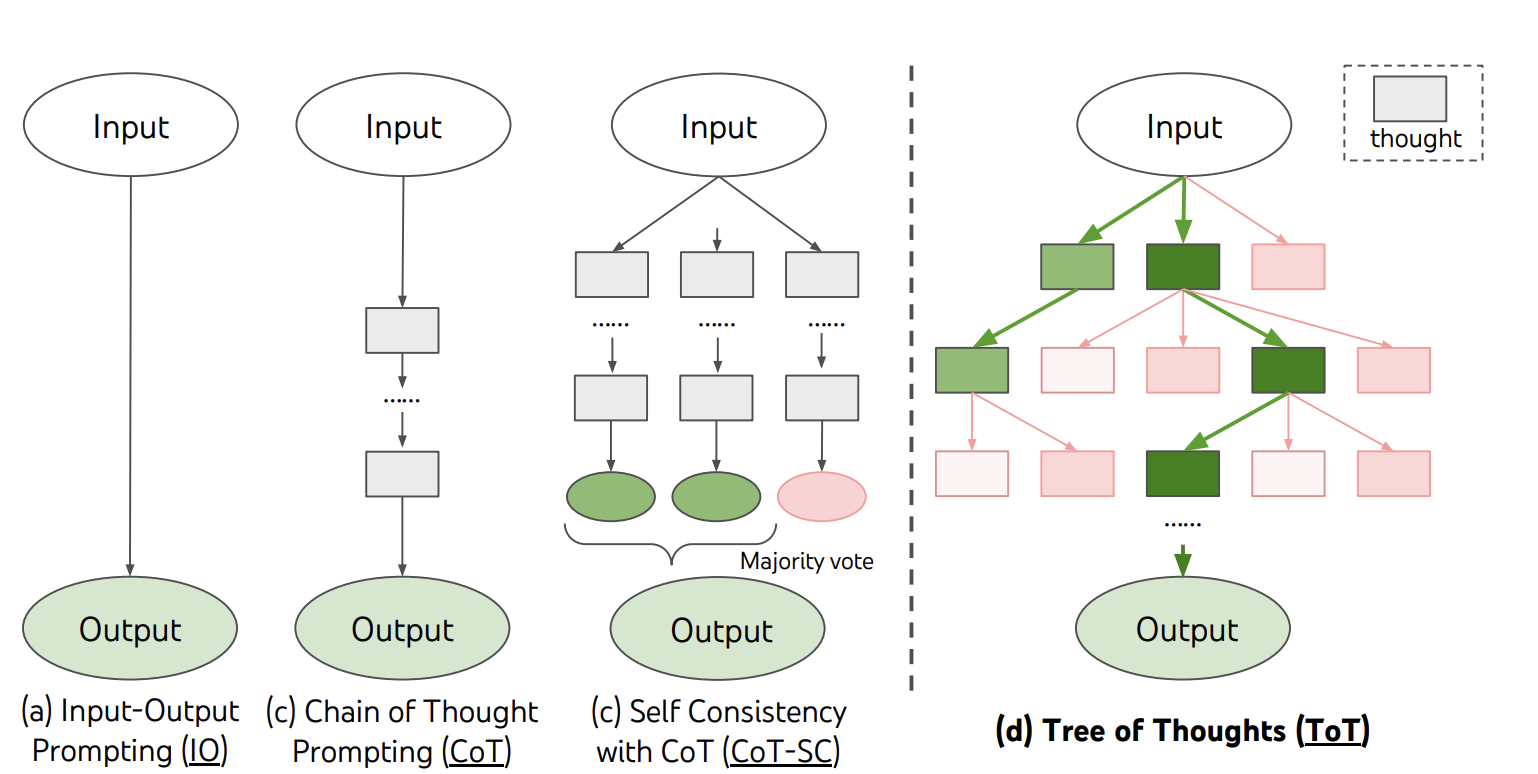
Fig. 10. Schematic illustrating various approaches to problem solving with LLMs. (Image source: Yao et al. 2023)
规划: 自我反思
自我反思(Self-Reflexion) 是使 Agent 通过改进过去的行动决策和纠正以往错误而实现迭代提升的关键因素。在试错不可避免的现实任务中,它起着至关重要的作用。
ReAct
ReAct(Reason + Act) (Yao et al. 2023) 框架通过将任务特定的离散动作和语言空间相结合,实现了 LLM 中推理与行动的无缝整合。这种设计不仅使模型能够通过调用例如 Wikipedia 搜索 API 等外部接口与环境进行交互,同时还能以自然语言生成详细的推理轨迹,从而解决复杂问题。
ReAct 提示模板包含明确的思考步骤,其基本格式如下:
Thought:...
Action:...
Observation:...
...(Repeated many times)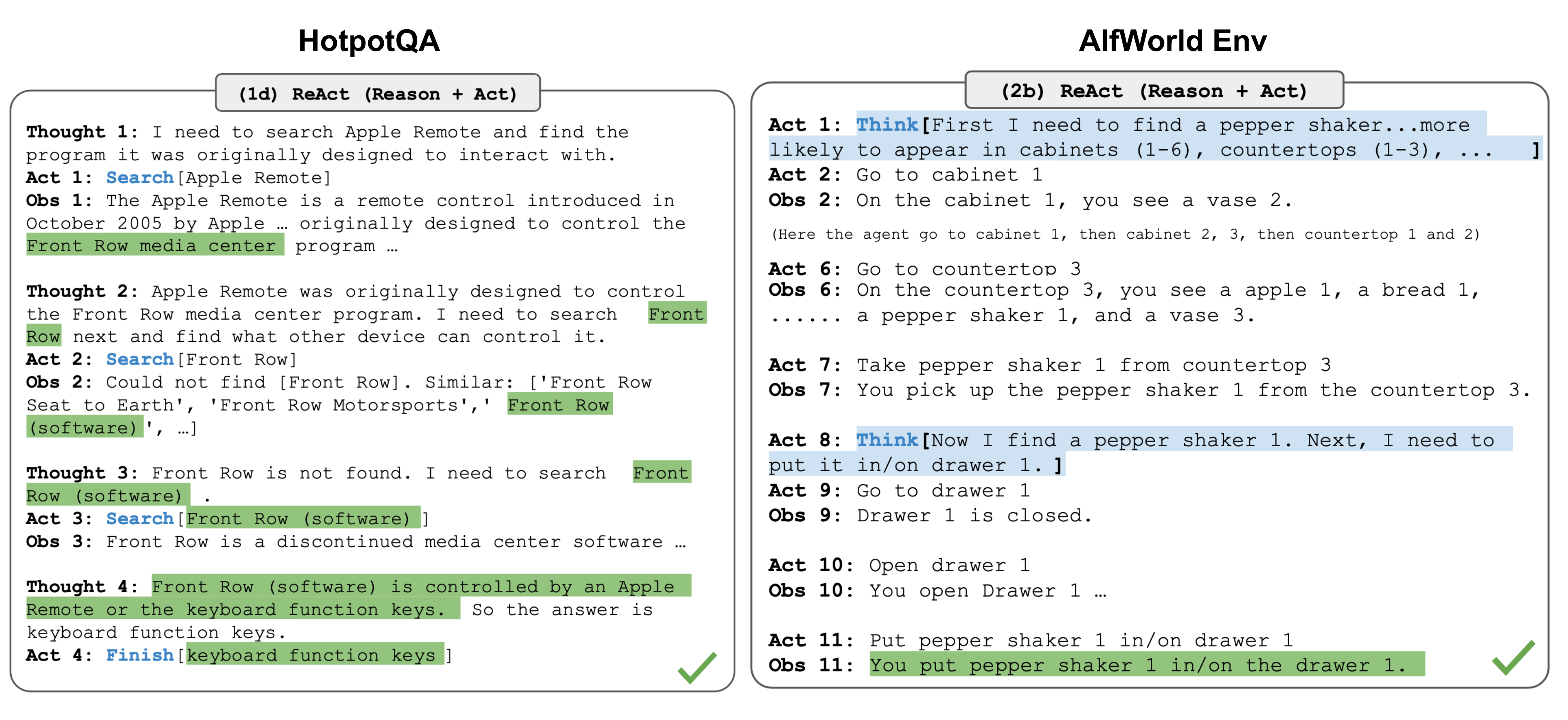
Fig. 11. Examples of reasoning trajectories for knowledge-intensive tasks (e.g. HotpotQA, FEVER) and decision-making tasks (e.g. AlfWorld Env, WebShop). (Image source: Yao et al. 2023)
从下图可以看出在知识密集型任务和决策任务中,ReAct 的表现均明显优于仅依赖
Actor的基础方法,从而展示了其在提升推理效果和交互性能方面的优势。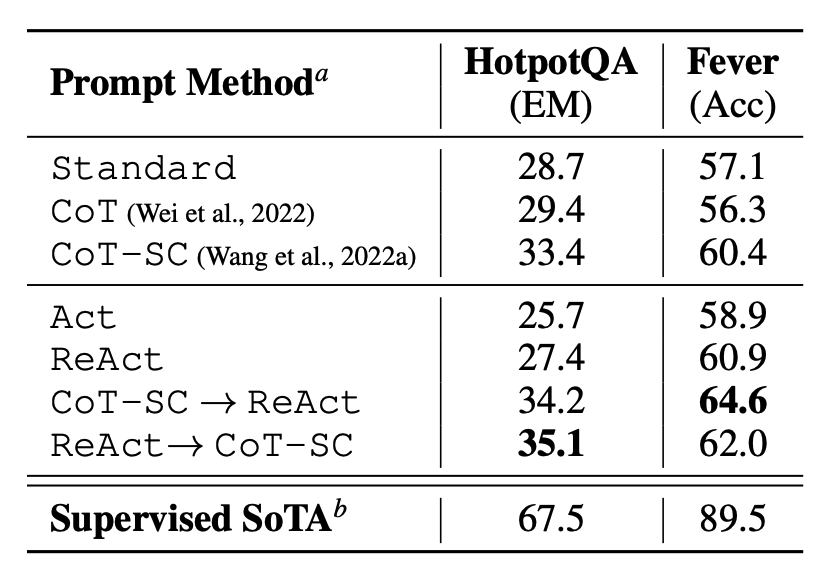
Fig. 12. PaLM-540B prompting results on HotpotQA and Fever. (Image source: Yao et al. 2023)
Reflexion
Reflexion(Shinn et al. 2023)让 LLM 能够通过自我反馈与动态记忆不断迭代、优化决策。
这种方法本质上借鉴了强化学习的思想,在传统的 Actor-Critic 模型中,Actor 根据当前状态 st 选择动作 at,而 Critic 则会给出估值(例如价值函数 V(st) 或动作价值函数 Q(st,at)),并反馈给 Actor 进行策略优化。对应地,在 Reflexion 的三大组件中:
- Actor:由 LLM 扮演,基于环境状态(包括上下文和历史信息)输出文本及相应动作。可记为:
at=πθ(st),
其中 πθ 表示基于参数 θ(即 LLM 的权重或提示)得到的策略。Actor 与环境交互并产生轨迹 τ=(s1,a1,r1),…,(sT,aT,rT)。
- Evaluator:类似于 Critic,Evaluator 接收由 Actor 生成的轨迹并输出奖励信号 rt。在 Reflexion 框架里,Evaluator 可以通过预先设计的启发式规则或额外的 LLM 来对轨迹进行分析,进而产生奖励。例如:
rt=R(τt),
其中 R(⋅) 为基于当前轨迹 τt 的奖励函数。
- Self-Reflection:该模块相当于在 Actor-Critic 之外额外增加了自我调节反馈机制。它整合当前轨迹 τ、奖励信号 rt 以及长期记忆中的历史经验,利用语言生成能力产生针对下一次决策的自我改进建议。这些反馈信息随后被写入外部记忆,为后续 Actor 的决策提供更丰富的上下文,从而在不更新 LLM 内部参数的情况下,通过提示词的动态调整实现类似于策略参数 θ 的迭代优化。
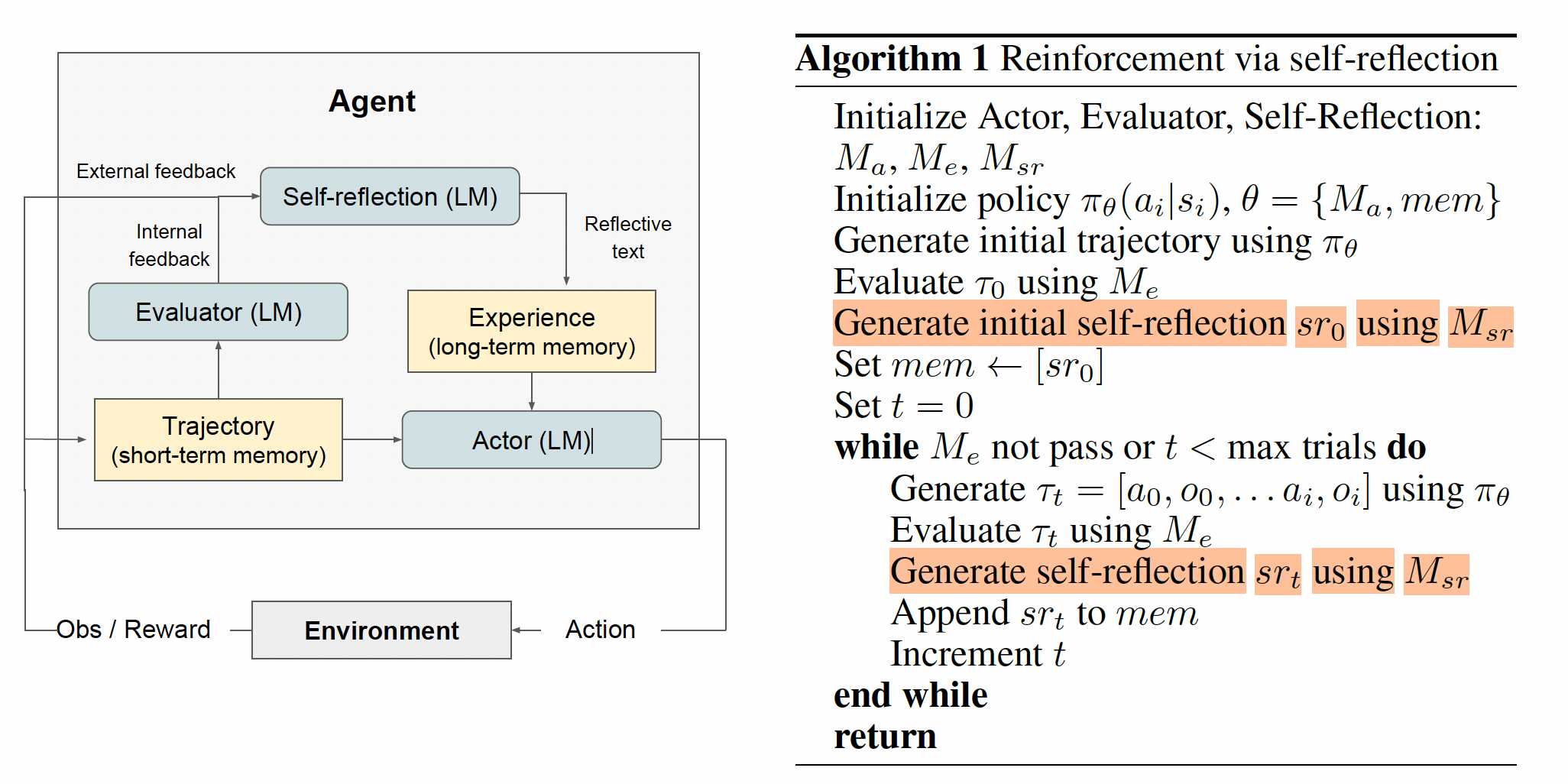
Fig. 13. (a) Diagram of Reflexion. (b) Reflexion reinforcement algorithm. (Image source: Shinn et al. 2023)
Reflexion 的核心循环与算法描述如下:
- 初始化
- 同时实例化 Actor、Evaluator、Self-Reflection 三个模型(均可由 LLM 实现),分别记为 。
- 初始化策略 (包含 Actor 的模型参数或提示,以及初始记忆等信息)。
- 先让 Actor 按当前策略 生成一个初始轨迹 , 进行评估后,再由 生成首条自我反思文本并存入长期记忆。
Ma,Me,Msr
πθ
πθ
τ0
Me
Msr
- 生成轨迹
- 在每一次迭代中, 读取当前的长期记忆及环境观测,依次输出动作 ,与环境交互并获得相应反馈,形成新的轨迹 。 可以视作该任务的短期记忆,仅在本轮迭代中使用。
Ma
a1,a2,…
τt
τt
- 评估
- Me 根据轨迹 (即 Actor 的行为与环境反馈序列),输出奖励或评分 。这一步对应 的内部反馈,或由外部环境直接给出结果。
τt
r1,r2,…
Me
- 自我反思
- Msr 模块综合轨迹 与奖励信号 在语言层面生成自我修正或改进建议 。
- 反思文本既可视为对错误的剖析,也可提供新的启发思路,并通过存储到长期记忆中。实践中,我们可以将反馈信息向量化后存入向量数据库。
τt
rt
srt
- 更新并重复
- 将最新的自我反思文本 追加到长期记忆后,Actor 在下一轮迭代时即可从中采用 RAG 检索历史相关信息来调整策略。
- 反复执行上述步骤,直至 判定任务达成或到达最大轮次。在此循环中,Reflexion 依靠 自我反思 + 长期记忆 的持续累加来改进决策,而非直接修改模型参数。
srt
Me
下面分别展示了 Reflexion 在决策制定、编程和推理任务中的应用示例:
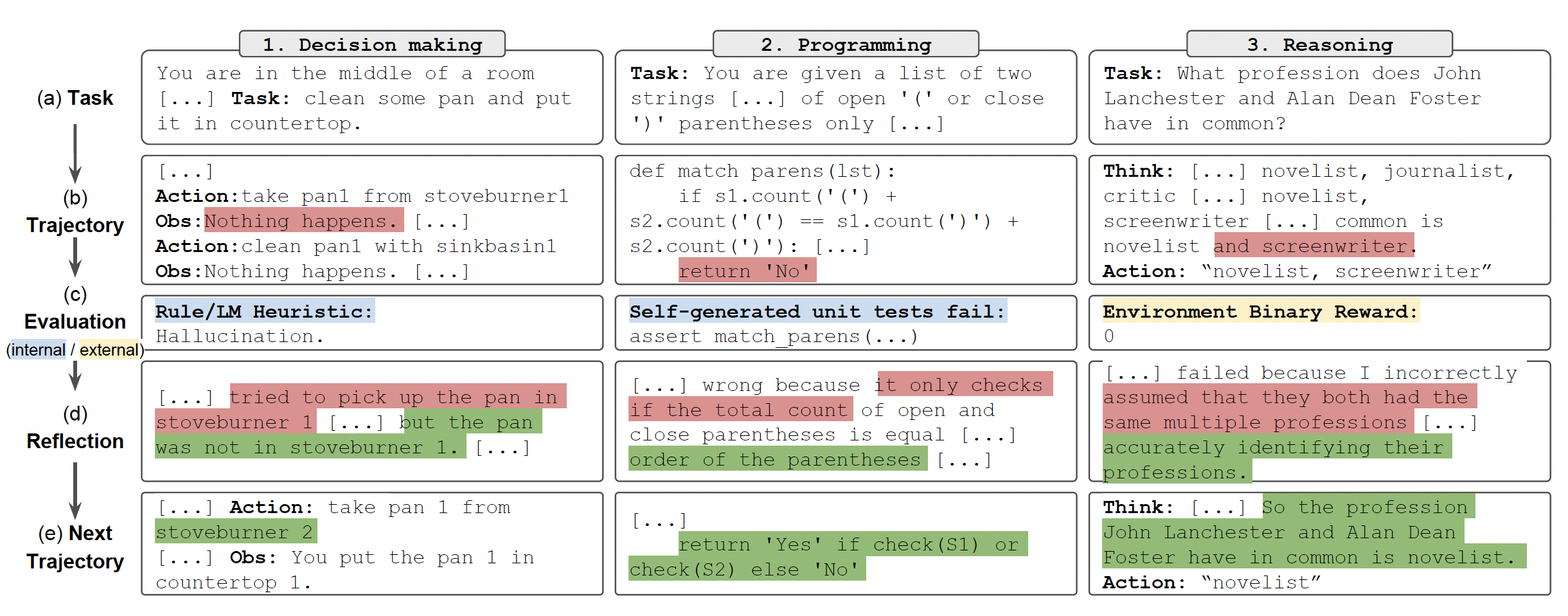
Fig. 14. Reflexion works on decision-making, programming 4.3, and reasoning tasks. (Image source: Shinn et al. 2023)
在 100 个 HotPotQA 问题的实验中,通过对比 CoT 方法和加入 episodic memory 的方式,结果显示采用 Reflexion 方法在最后增加自我反思步骤后,其搜索、信息检索和推理能力提升明显。
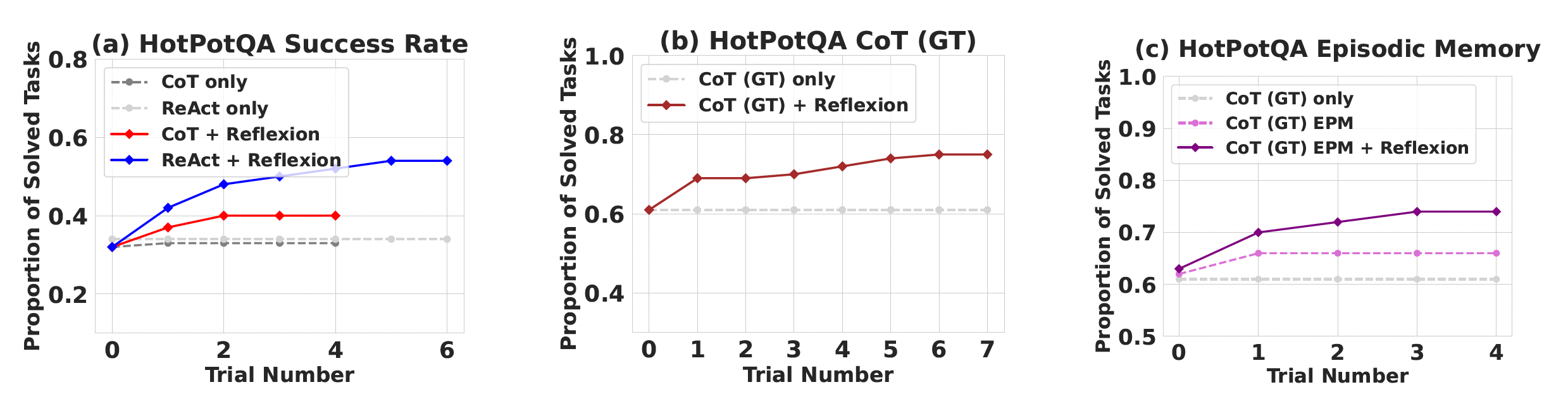
Fig. 15. Comparative Analysis of Chain-of-Thought (CoT) and ReAct on the HotPotQA Benchmark. (Image source: Shinn et al. 2023)
DeepSeek R1
DeepSeek-R1 (DeepSeek-AI, 2025) 代表了开源社区在复现 OpenAI o1 (OpenAI, 2024) 方面的重大突破,通过强化学习技术成功训练出具备深度反思能力的高级推理模型。
关于 DeepSeek R1 的详细训练流程与技术实现,请参考我之前的博客:OpenAI o1复现进展:DeepSeek-R1。
DeepSeek-R1-Zero 在训练过程中的关键转变 — 随着训练的深入,模型逐渐涌现出卓越的自我进化能力。这种能力体现在三个核心方面:
- 自我反思:模型能够回溯并批判性地评估先前的推理步骤。
- 主动探索:当发现当前解题路径不理想时,能够自主寻找并尝试替代方案。
- 动态思考调整:根据问题复杂度自适应地调整生成 token 数量,实现更深入的思考过程。
这种动态且自发的推理行为显著提升了模型解决复杂问题的能力,使其能够更加高效、准确地应对具有挑战性的任务。
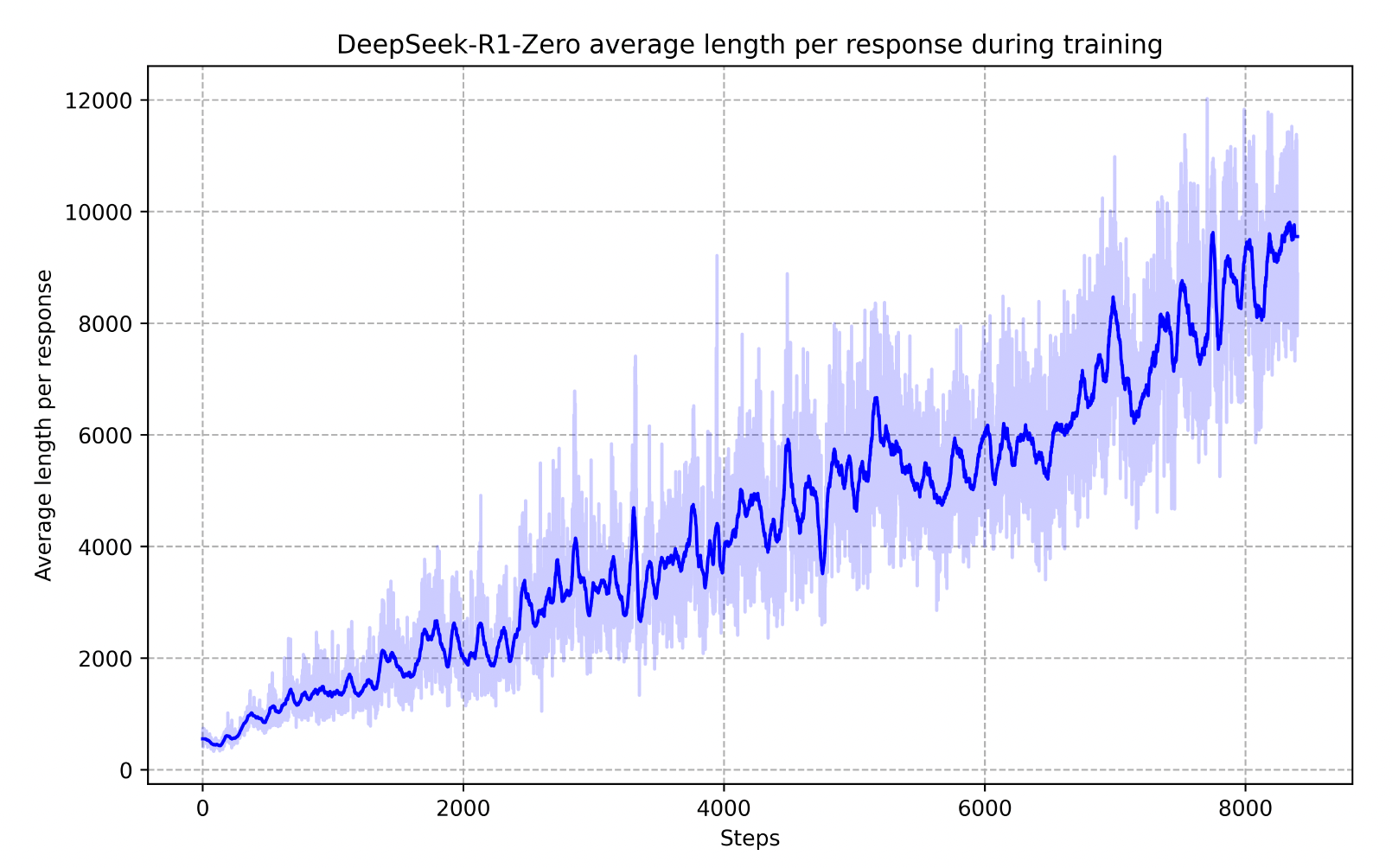
Fig. 16. The average response length of DeepSeek-R1-Zero on the training set during the RL process. (Image source: DeepSeek-AI, 2025)
DeepSeek-R1-Zero 训练过程中也涌现出一个典型"顿悟时刻"(aha moment)。在这一关键阶段,模型在推理过程中突然意识到先前的思考路径存在错误,随即迅速调整思考方向,最终成功导向正确答案。这一现象有力证明了模型在推理过程中已发展出强大的自我纠错和反思能力,类似于人类思考过程中的顿悟体验。

Fig. 17. An interesting “aha moment” of an intermediate version of DeepSeek-R1-Zero. (Image source: DeepSeek-AI, 2025)
记忆
人类记忆
记忆 指的是获取、储存、保持和提取信息的过程。人类的记忆主要分为以下三大类:

Fig. 18. Categorization of human memory. (Image source: Weng, 2017)
- 感觉记忆: 用于在原始刺激(视觉、听觉、触觉等)消失后短暂保留感官信息,通常持续时间以毫秒或秒计。感觉记忆又分为:
- 视觉记忆:对视觉通道所保留的瞬时图像或视觉印象,一般维持 0.25~0.5 秒,用于在视频或动画场景中形成视觉连续性。
- 听觉记忆:对听觉信息的短暂存储,可持续数秒,使人能回放刚刚听到的语句或声音片段。
- 触觉记忆:用于保留短暂的触觉或力觉信息,一般持续毫秒到秒级,例如敲击键盘或盲文阅读时短暂的手指感知。
- 短期记忆: 存储我们当前意识到的信息。
- 持续时间约 20~30 秒,容量通常为 7±2 个项目。
- 承担学习、推理等复杂认知任务时对信息的临时处理和维持。
- 长期记忆: 能将信息保存数天到数十年,容量几乎无限。长期记忆分为:
- 外显记忆: 可有意识回忆,包含情景记忆(个人经历、事件细节)和语义记忆(事实与概念)。
- 内隐记忆:无意识记忆,主要与技能和习惯相关,如骑车或盲打。
人类记忆的这三种类型相互交织,共同构成了我们对世界的认知和理解。在构建 LLM Agent 中,我们也可以借鉴人类记忆的这种分类方式:
- 感觉记忆 对应 LLM 对输入原始数据(如文本、图片和视频)等的嵌入表征。
- 短期记忆 对应 LLM 的上下文内学习,受限于模型上下文窗口
max_tokens,当对话长度超出窗口后,早期信息将被截断。
- 长期记忆 对应 外部向量存储或数据库,Agent 可以基于 RAG 技术在需要时检索历史信息。
LLM Agent 记忆
Agent 与用户多轮互动、执行多步任务时,可以利用不同形式的记忆以及环境信息来完成工作流。
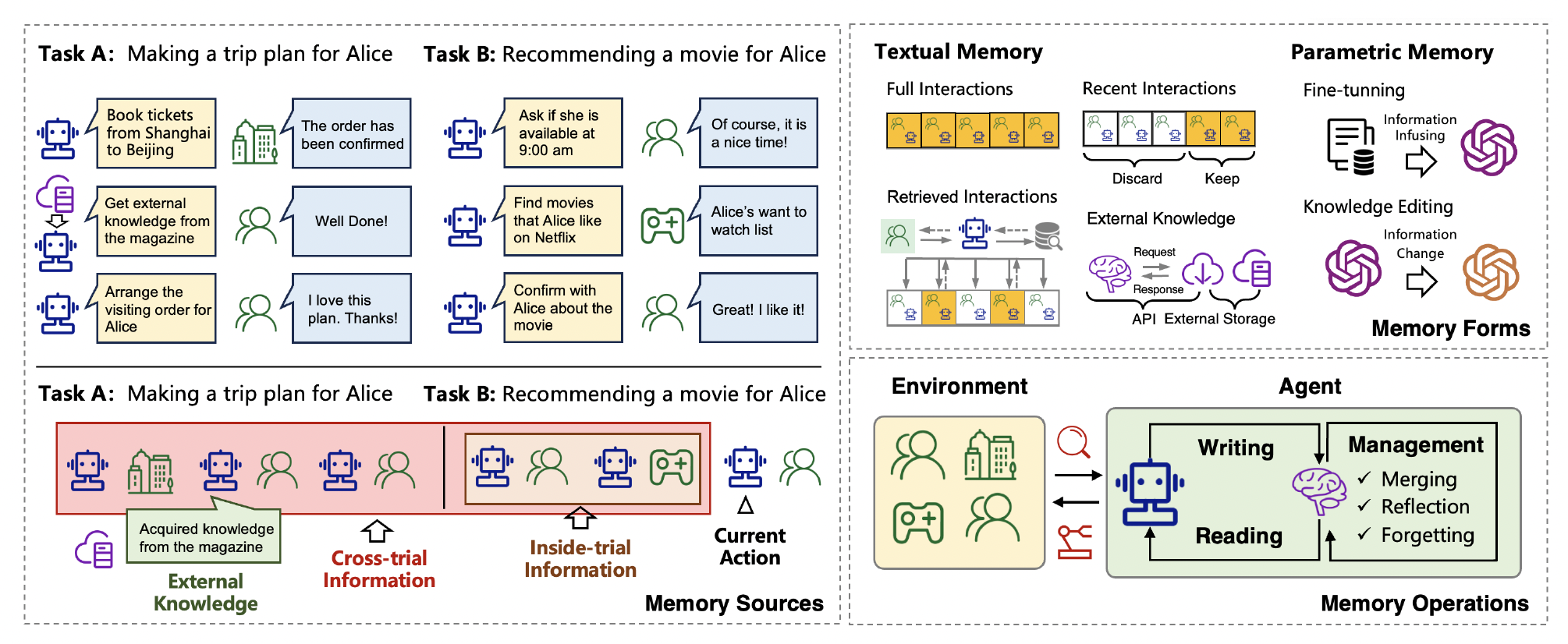
Fig. 19. An overview of the sources, forms, and operations of the memory in LLM-based agents. (Image source: Zhang et al. 2024)
- 文本记忆
- 完整交互:记录了所有对话与操作轨迹,帮助 Agent 回溯上下文。
- 近期交互:只保留与当前任务高度相关的对话内容,减少不必要的上下文占用。
- 检索到的交互:Agent 可从外部知识库中检索到与当前任务相关的历史对话或记录,融入当前上下文中。
- 外部知识:当 Agent 遇到知识空白时,可通过 API 或外部存储进行检索和获取额外信息。
- 参数化记忆
- 微调:通过给 LLM 注入新的信息或知识,从而扩充模型的内部知识。
- 知识编辑:在模型层面对已有知识进行修改或更新,实现对模型内部参数记忆的动态调整。
- 环境
- 代表着 Agent 与用户及外部系统交互时涉及的实体和上下文,比如用户 Alice、可能访问的工具或界面(例如订票系统、流媒体平台等)。
- Agent
- LLM Agent 负责读与写操作,即读取外部环境或知识库的信息,写入新的动作或内容。
- 同时包含一系列管理功能,如合并、反思、遗忘等,用以动态维护短期和长期记忆。
另外一个例子是 Agent 在完成在两个不同但相关的任务中,需要同时使用短期记忆和长期记忆:
- 任务 A 播放视频:Agent 将当前的计划、操作和环境状态(例如搜索、点击、播放视频等)记录在短期记忆中,这部分信息会保存在内存和 LLM 的上下文窗口中。
- 任务 B 下载游戏:Agent 利用长期记忆中与 Arcane 和 League of Legend 相关的知识,快速找到游戏下载方案。图中显示,Agent 在 Google 上进行搜索,我们可以将 Google 的知识库视作一个外部知识源,同时所有新的搜索、点击和下载操作也会被更新到短期记忆中。
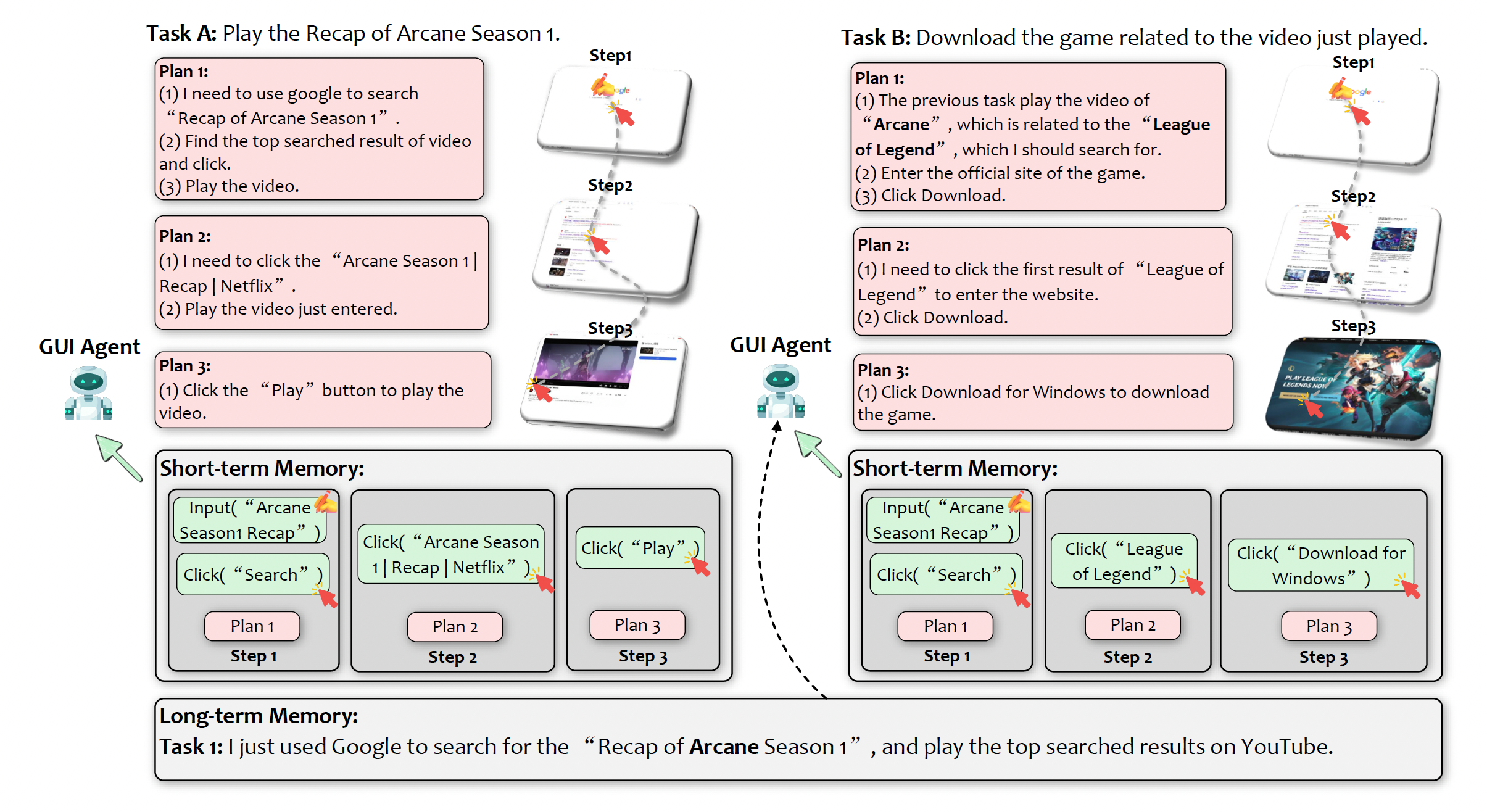
Fig. 20: Illustration of short-term memory and long-term memory in an LLM-brained GUI agent. (Image source: Zhang et al. 2024)
常见记忆元素及其对应的存储方式可以总结成以下表格:
记忆元素 | 记忆类型 | 描述 | 存储介质 / 方式 |
动作 | 短期记忆 | 历史动作轨迹(例如点击按钮、输入文本等) | 内存、LLM 上下文窗口 |
计划 | 短期记忆 | 上一步或当前生成的下一步操作计划 | 内存、LLM 上下文窗口 |
执行结果 | 短期记忆 | 动作执行后返回的结果、报错信息及环境反馈 | 内存、LLM 上下文窗口 |
环境状态 | 短期记忆 | 当前 UI 环境中可用的按钮、页面标题、系统状态等 | 内存、LLM 上下文窗口 |
自身经验 | 长期记忆 | 历史任务轨迹与执行步骤 | 数据库、磁盘 |
自我引导 | 长期记忆 | 从历史成功轨迹中总结出的指导规则与最佳实践 | 数据库、磁盘 |
外部知识 | 长期记忆 | 辅助任务完成的外部知识库、文档或其他数据源 | 外部数据库、向量检索 |
任务成功指标 | 长期记忆 | 记录任务成功率、失败率等指标,便于改进和分析 | 数据库、磁盘 |
此外,研究者还提出一些新的训练和存储方法,以增强 LLM 的记忆能力:
LongMem(Language Models Augmented with Long-Term Memory)(Wang, et al. 2023)使 LLM 能够记忆长历史信息。其采用一种解耦的网络结构,将原始 LLM 参数冻结为记忆编码器(memory encoder)固定下来,同时使用自适应残差网络(Adaptive Residual Side-Network,SideNet)作为记忆检索器进行记忆检查和读取。
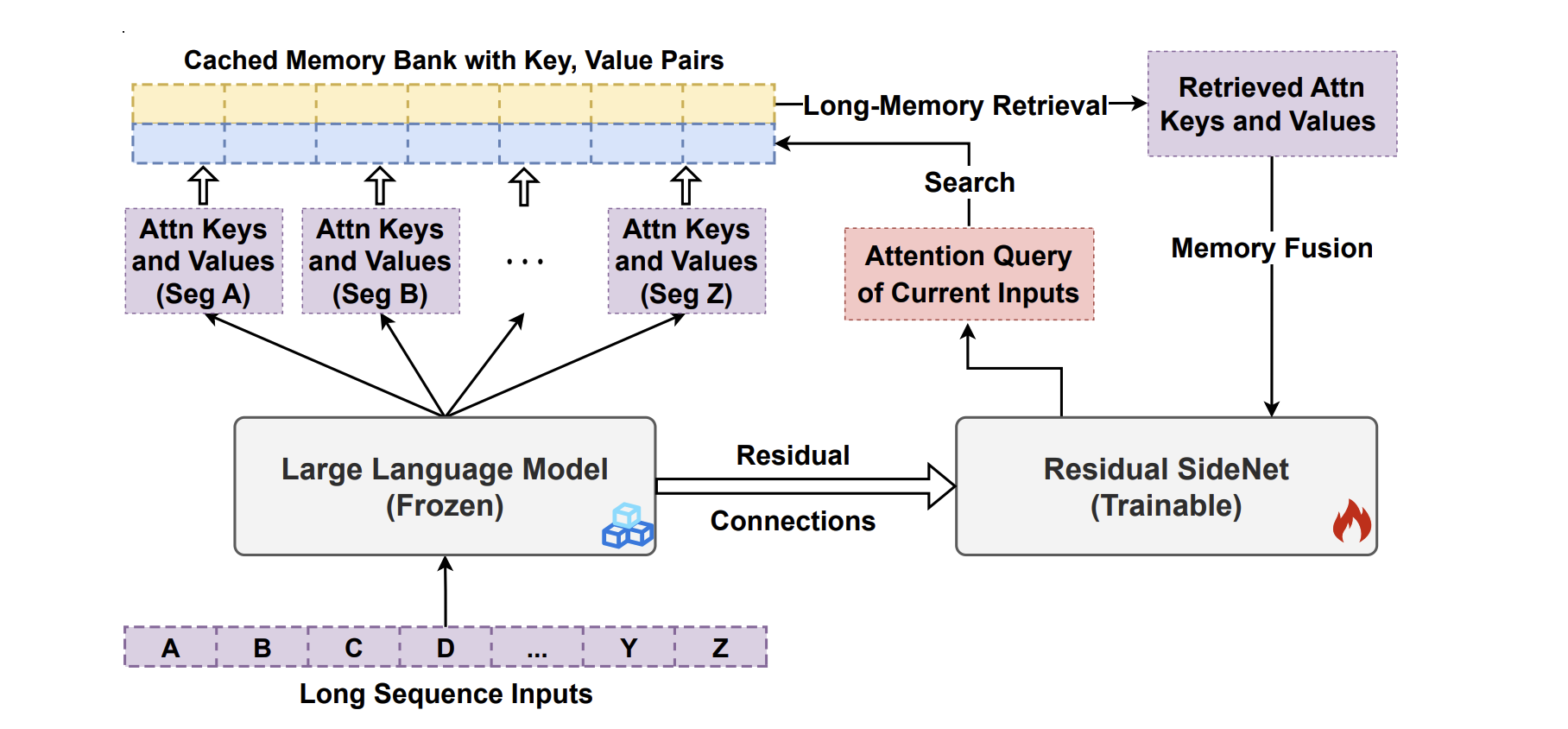
Fig. 21. Overview of the memory caching and retrieval flow of LongMem. (Image source: Wang, et al. 2023)
其主要由三部分构成:Frozen LLM、Residual SideNet 和 Cached Memory Bank。其工作流程如下:
- 先将长文本序列拆分成固定长度的片段,每个片段在 Frozen LLM 中逐层编码后,在第 层提取注意力的 向量对并缓存到 Cached Memory Bank。
m
K,V∈RH×M×d
- 面对新的输入序列时,模型根据当前输入的 query-key 检索长期记忆库,从中获取与输入最相关的前 个 key-value(即 top- 检索结果),并将其融合到后续的语言生成过程中;与此同时记忆库会移除最旧的内容以保证最新上下文信息的可用性。
k
k
- Residual SideNet 则在推理阶段对冻结 LLM 的隐藏层输出与检索得到的历史 key-value 进行融合,完成对超长文本的有效建模和上下文利用。
通过这种解耦设计,LongMem 无需扩大自身的原生上下文窗口就能灵活调度海量历史信息,兼顾了速度与长期记忆能力。
工具使用
工具使用 是 LLM Agent 重要组成部分, 通过赋予 LLM 调用外部工具的能力,其功能得到了显著扩展:不仅能够生成自然语言,还能获取实时信息、执行复杂计算以及与各类系统(如数据库、API 等)交互,从而有效突破预训练知识的局限,避免重复造轮子的低效过程。
传统 LLM 主要依赖预训练数据进行文本生成,但这也使得它们在数学运算、数据检索和实时信息更新等方面存在不足。通过工具调用,模型可以:
- 提升运算能力: 例如通过调用专门的计算器工具 Wolfram,模型能够进行更精准的数学计算,弥补自身算术能力的不足。
- 实时获取信息: 利用搜索引擎 Gooole、Bing 或数据库 API,模型可以访问最新信息,确保生成内容的时效性和准确性。
- 增强信息可信度: 借助外部工具的支持,模型能够引用真实数据来源,降低信息虚构的风险,提高整体可信性。
- 提高系统透明度: 跟踪 API 调用记录可以帮助用户理解模型决策过程,提供一定程度的可解释性。
当前,业界涌现出多种基于工具调用的 LLM 应用,它们利用不同策略和架构,实现了从简单任务到复杂多步推理的全面覆盖。
Toolformer
Toolformer (Schick, et al. 2023)是一种能够通过简单 API 使用外部工具的 LLM。它的训练方式基于 GPT-J 模型进行微调,仅需为每个 API 提供少量示例。Toolformer 学到调用的工具包括问答系统、 Wikipedia 搜索、计算器、日历和翻译系统:

Fig. 22. Examples of inputs and outputs for all APIs used. (Image source: Schick, et al. 2023)
HuggingGPT
HuggingGPT (Shen, et al. 2023)是一种利用 ChatGPT 作为任务规划器的框架,通过读取模型描述从 HuggingFace 筛选可用的模型来完成用户任务,并根据执行结果进行总结。
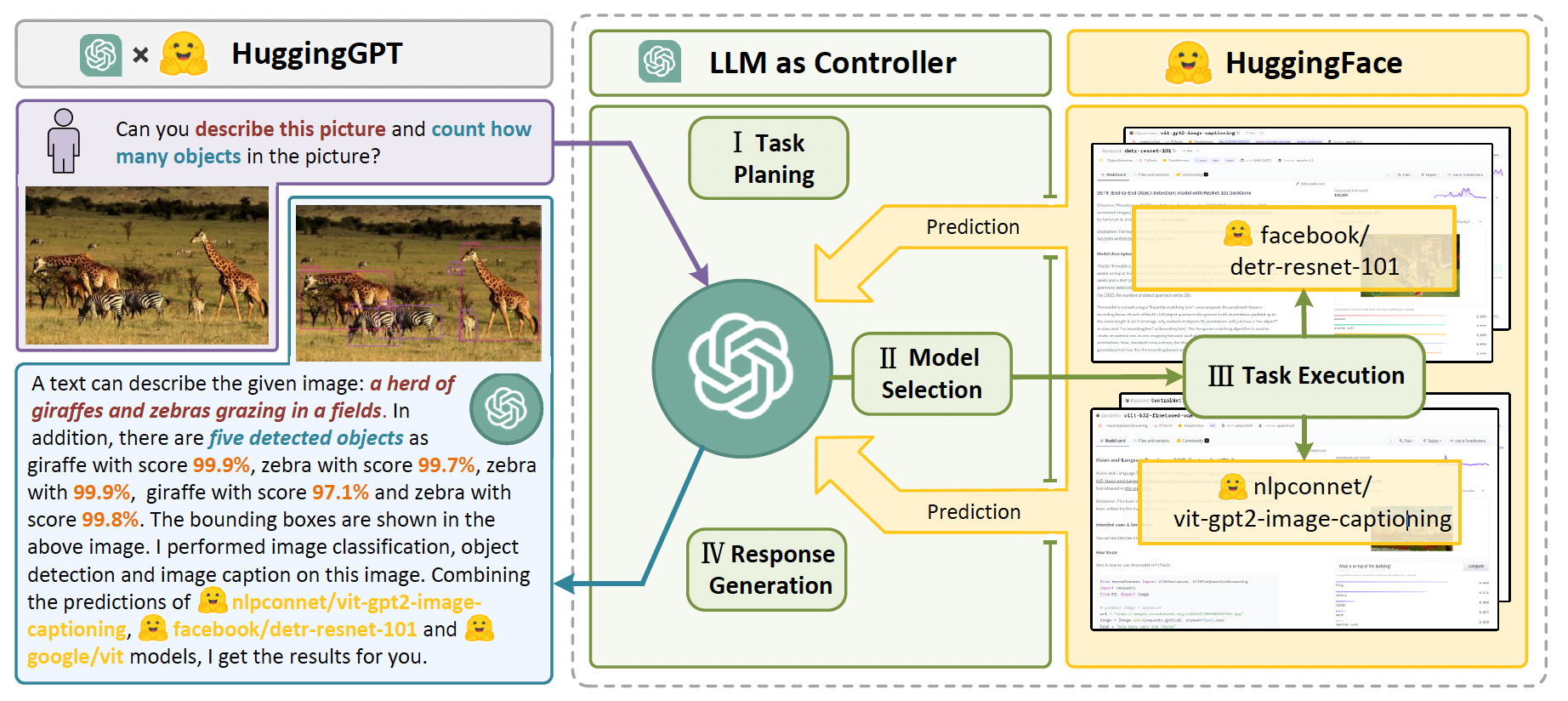
Fig. 23. Illustration of how HuggingGPT works. (Image source: Shen, et al. 2023)
该系统由以下四个阶段组成:
- 任务规划: 将用户请求解析为多个子任务。每个任务包含四个属性:任务类型、ID、依赖关系以及参数。论文使用少样本提示来指导模型进行任务拆分和规划。
- 模型选择: 将各子任务分配给不同的专家模型,采用多选题的方式来确定最合适的模型。由于上下文长度有限,需要根据任务类型对模型进行初步过滤。
- 任务执行: 专家模型执行分配的具体任务并记录结果, 结果会被传递给 LLM 进行后续处理。
- 结果生成: 接收各专家模型的执行结果,最后给用户输出总结性答案。
LLM 智能体应用
Generative Agent
Generative Agent (Park, et al. 2023) 实验通过 25 个由大型语言模型驱动的虚拟角色,在沙盒环境中模拟真实的人类行为。其核心设计融合了记忆、检索、反思以及规划与反应机制,允许 Agent 记录并回顾自身经验,并从中提炼出关键信息,以指导后续行动和互动。
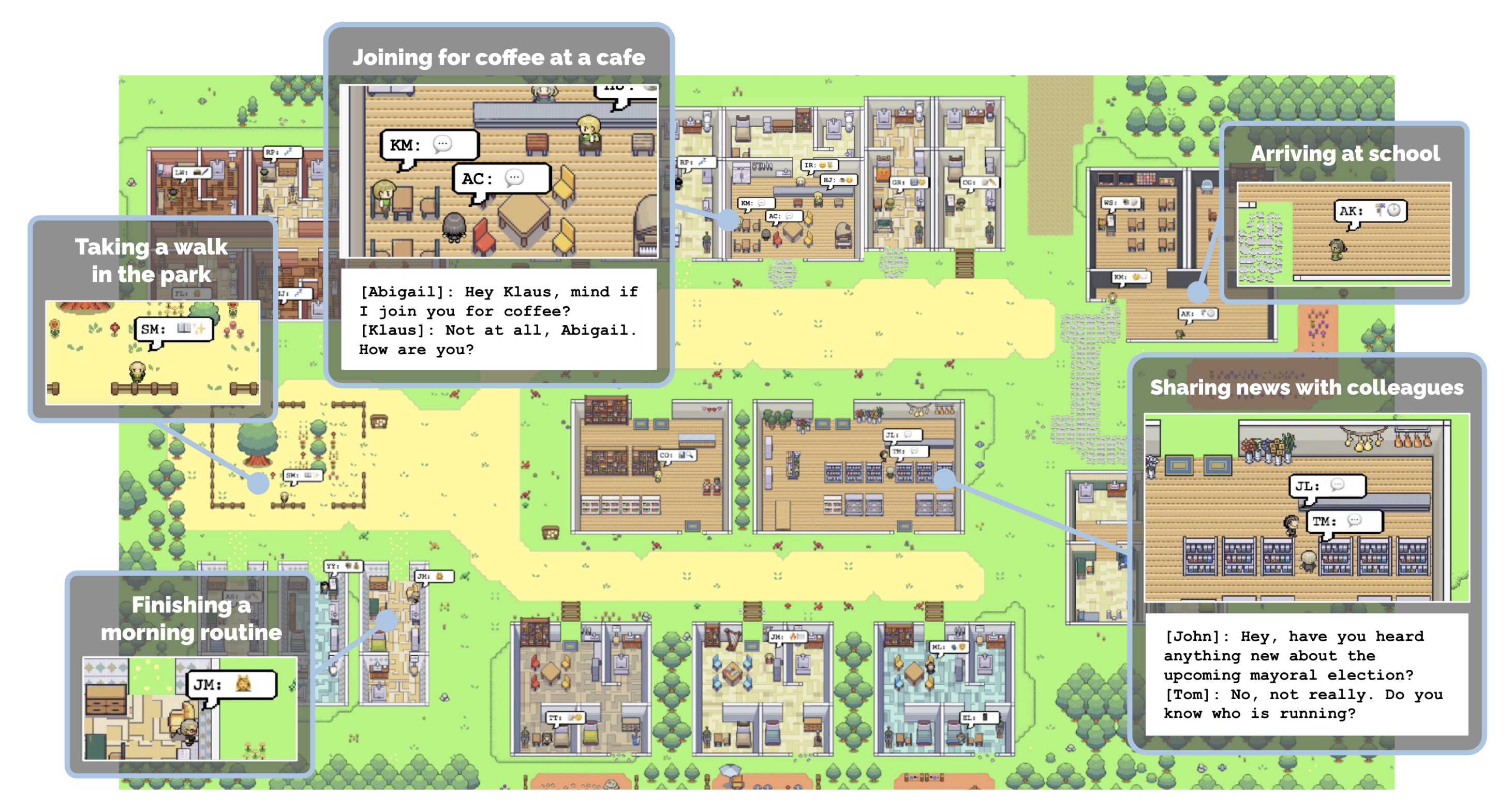
Fig. 24. The screenshot of generative agent sandbox. (Image source: Park, et al. 2023)
整个系统利用长期记忆模块记录所有观察事件,结合检索模型根据时效性、重要性与相关性提取信息,再通过反思机制生成高层次推断,最终将这些成果转化为具体行动。该仿真实验展示了信息扩散、关系记忆和社会事件协调等涌现行为,为交互式应用提供了逼真的人类行为模拟。
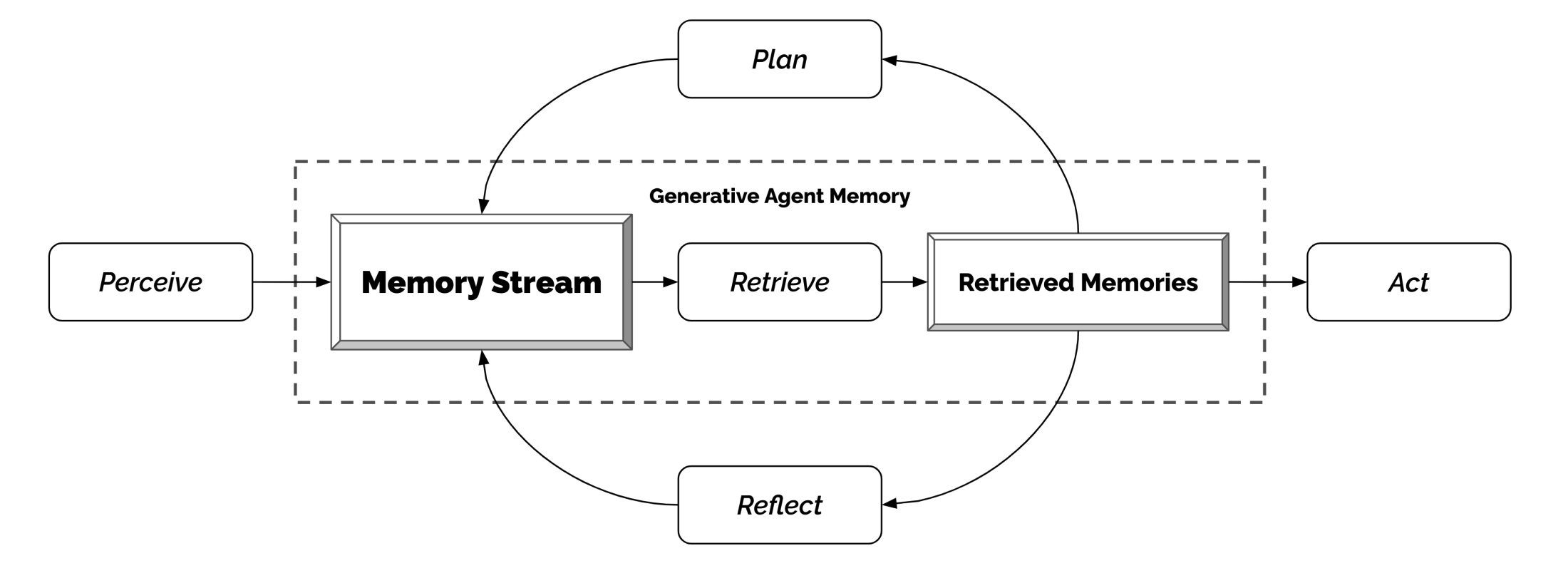
Fig. 25. The generative agent architecture. (Park, et al. 2023)
WebVoyager
WebVoyager(He et al. 2024) 是一种基于多模态大模型的自主网页交互智能体,能够控制鼠标和键盘进行网页浏览。WebVoyager 采用经典的 ReAct 循环。在每个交互步骤中,它查看带有类似 SoM(Set-of-Marks)(Yang, et al. 2023) 方法标注的浏览器截图即通过在网页元素上放置数字标签提供交互提示,然后决定下一步行动。这种视觉标注与 ReAct 循环相结合,使得用户可以通过自然语言与网页进行交互。具体可以参考使用 LangGraph 框架的WebVoyager 代码。
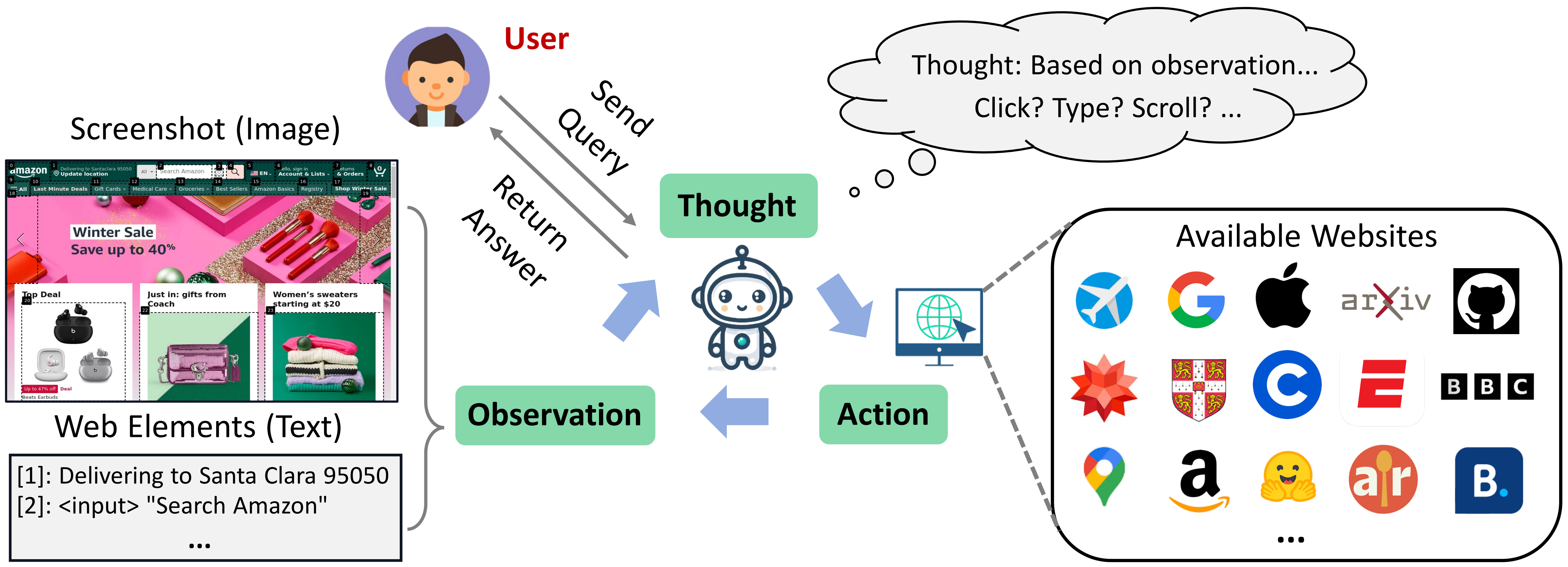
Fig. 26. The overall workflow of WebVoyager. (Image source: He et al. 2024)
OpenAI Operator
Operator (OpenAI, 2025) 是一个 OpenAI 近期发布的 AI 智能体,旨在自主执行网络任务。Operator 能够像人类用户一样与网页互动,通过打字、点击和滚动等操作完成指定任务。Operator 的核心技术是计算机使用智能体(Computer-Using Agent, CUA)(OpenAI, 2025)。CUA 结合了 GPT-4o 的视觉能力和通过强化学习获得更强的推理能力,经过专门训练后能够与图形用户界面(GUI)进行交互,包括用户在屏幕上看到的按钮、菜单和文本框。
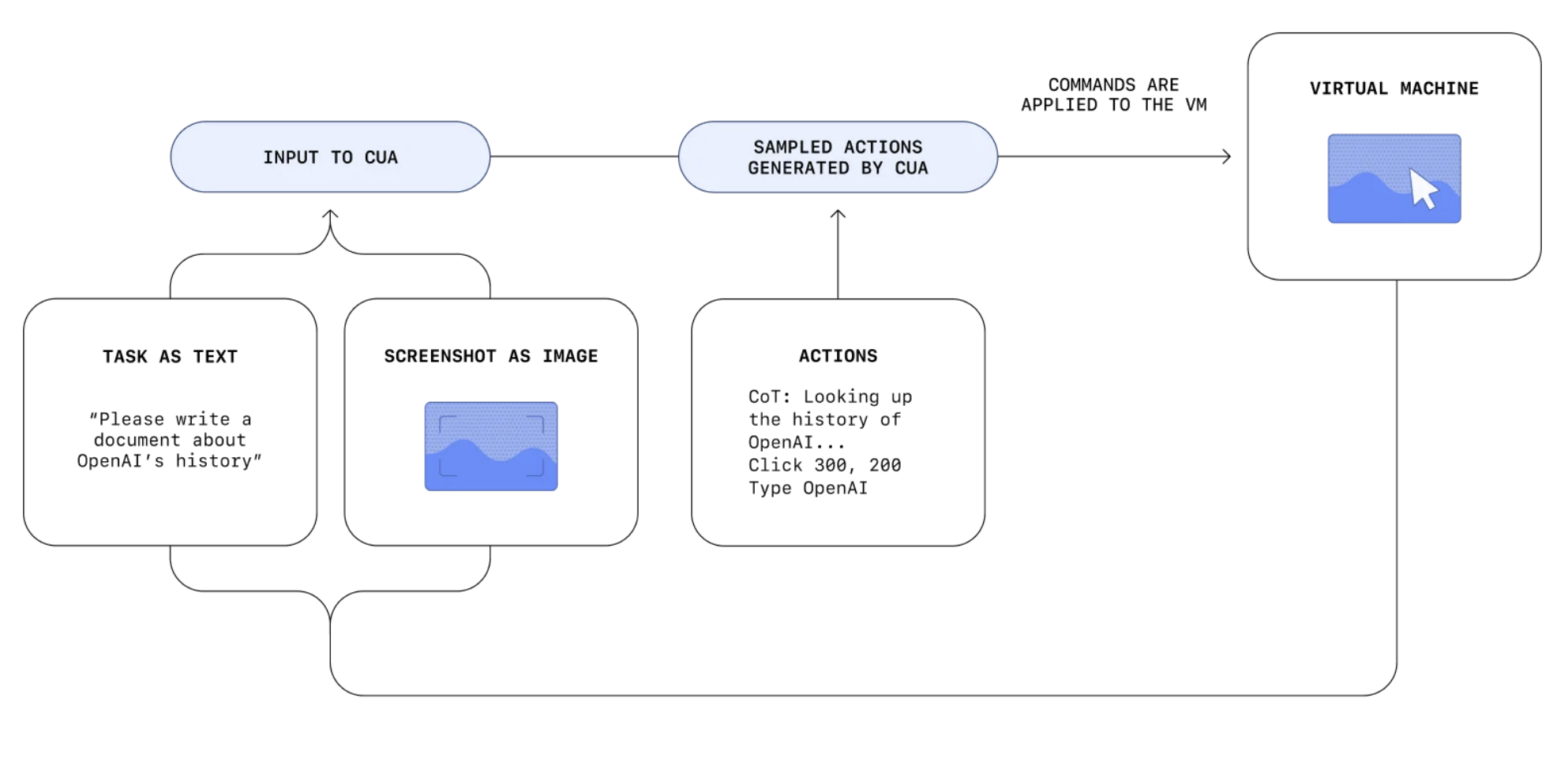
Fig. 27. Overview of OpenAI CUA. (Image source: OpenAI, 2025)
CUA 的运作方式遵循一个迭代循环,包含三个阶段:
- 感知: CUA 通过捕获浏览器截图来“观察”网页内容。这种基于视觉的输入方式使其能够理解页面的布局和元素。
- 推理: 借助链式思考的推理过程,CUA 会评估下一步行动,其依据是当前和之前的截图以及已执行的操作。这种推理能力使其能够跟踪任务进度、回顾中间步骤,并根据需要进行调整。
- 行动: CUA 通过模拟鼠标和键盘操作(如点击、输入和滚动)与浏览器进行交互。这使其能够在无需特定 API 集成的情况下执行各种网络任务。
CUA 和之前现有的 WebVoyager 不同之处在于这是一个专门经过强化学习训练的 Agent,而不是直接调用 GPT-4o 搭建的固定流程的 Workflow。虽然 CUA 目前仍处于早期阶段且存在一定局限,但它以下基准测试中取得了 SOTA 结果。
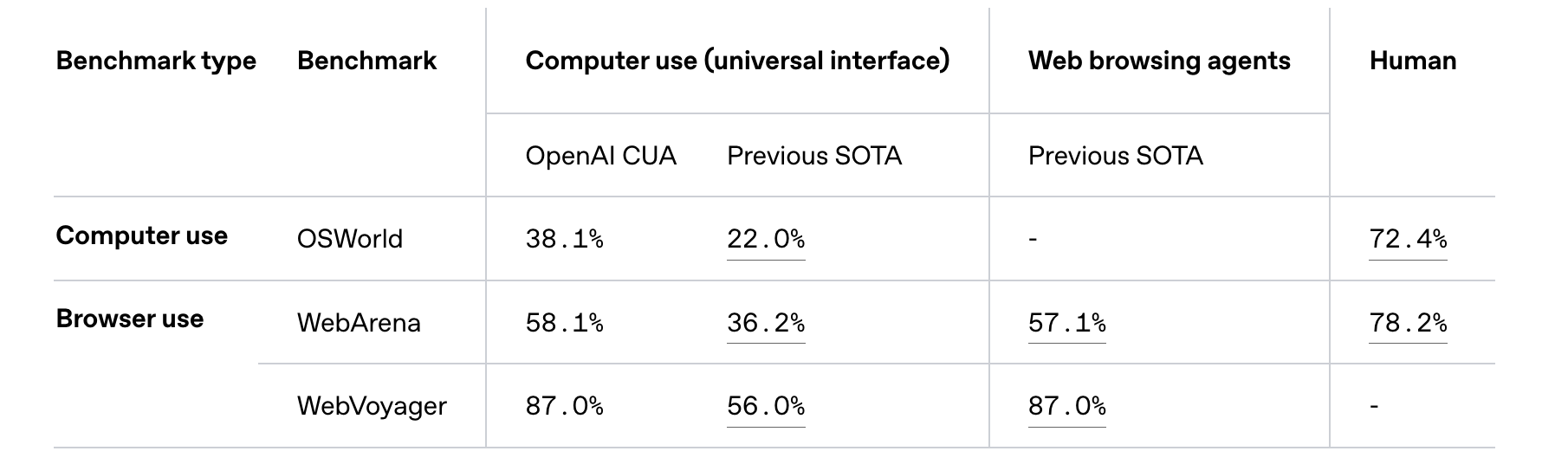
Fig. 28. OpenAI CUA Benchmark Results. (Image source: OpenAI, 2025)
Deep Research
Deep Research 本质上是一个报告生成系统:给定用户的查询,系统以 LLM 作为核心 Agent,经过多轮迭代式的信息检索与分析,最终生成一份结构化、翔实的报告。目前,各类 Deep Research 系统的实现逻辑主要可分为Workflow Agent和RL Agent两种方式。
Workflow Agent vs RL Agent
Workflow Agent 这种方式依赖开发人员预先使用设计的工作流和手工构建的 Prompt 来组织整个报告生成过程。主要特点包括:
- 任务分解与流程编排:系统将用户查询拆分为若干子任务,比如生成大纲、信息检索、内容汇总等,再按照预定的流程顺序执行。
- 固定流程:各个阶段之间的调用和交互是事先设定好的,类似于构建一个静态的流程图或有向无环图(DAG),确保每一步都有明确的职责。
- 人工设计依赖:该方法主要依赖工程师的经验,通过反复调试 Prompt 来提升输出质量,适用性较强但灵活性有限。
可以利用 LangGraph框架以图的形式来构建和编排工作流。
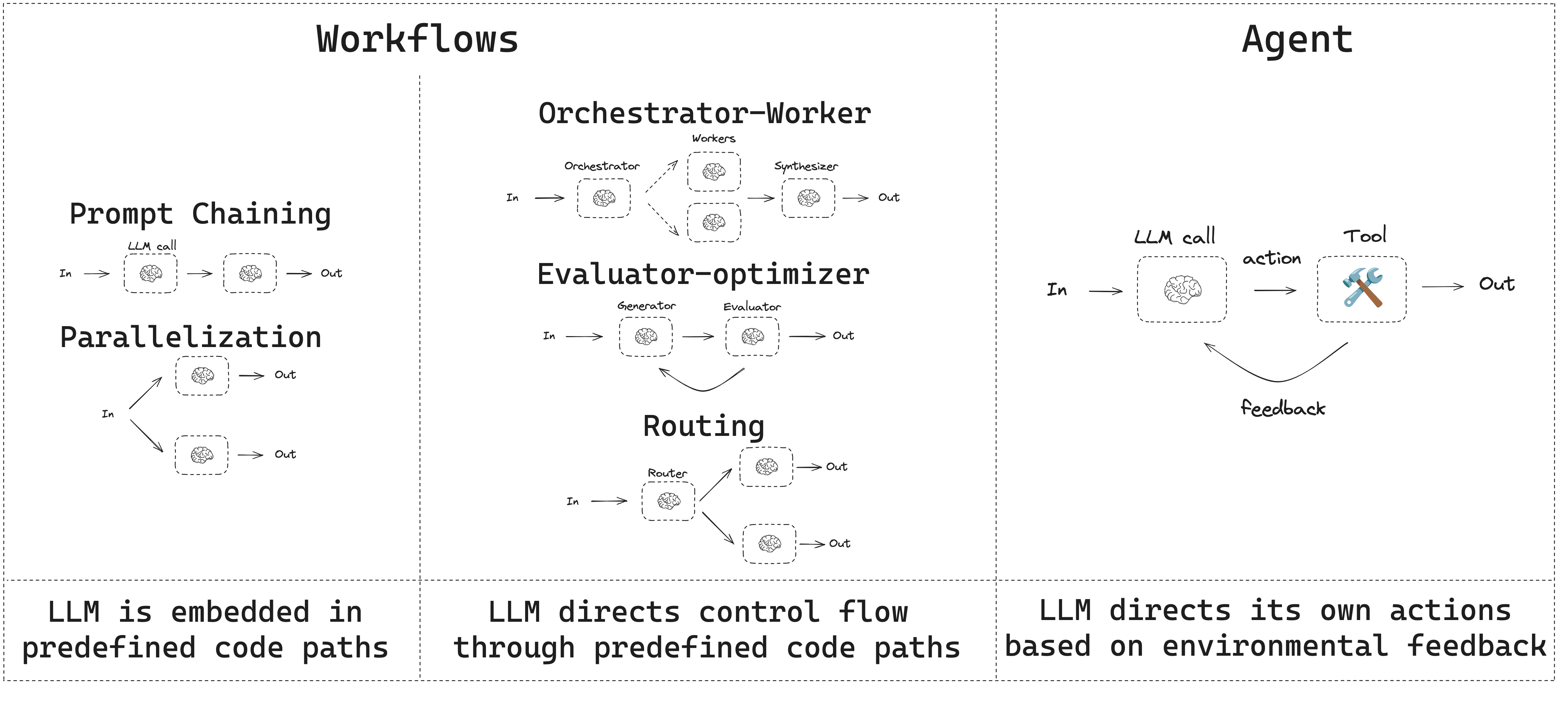
Fig. 29. A workflow of the LangGraph. (Image source: LangGraph, 2025)
目前 Github 上已经有多个开源项目实现了基于工作流的 Deep Research Agent,如 GPT Researcher 和 open deep research 等。
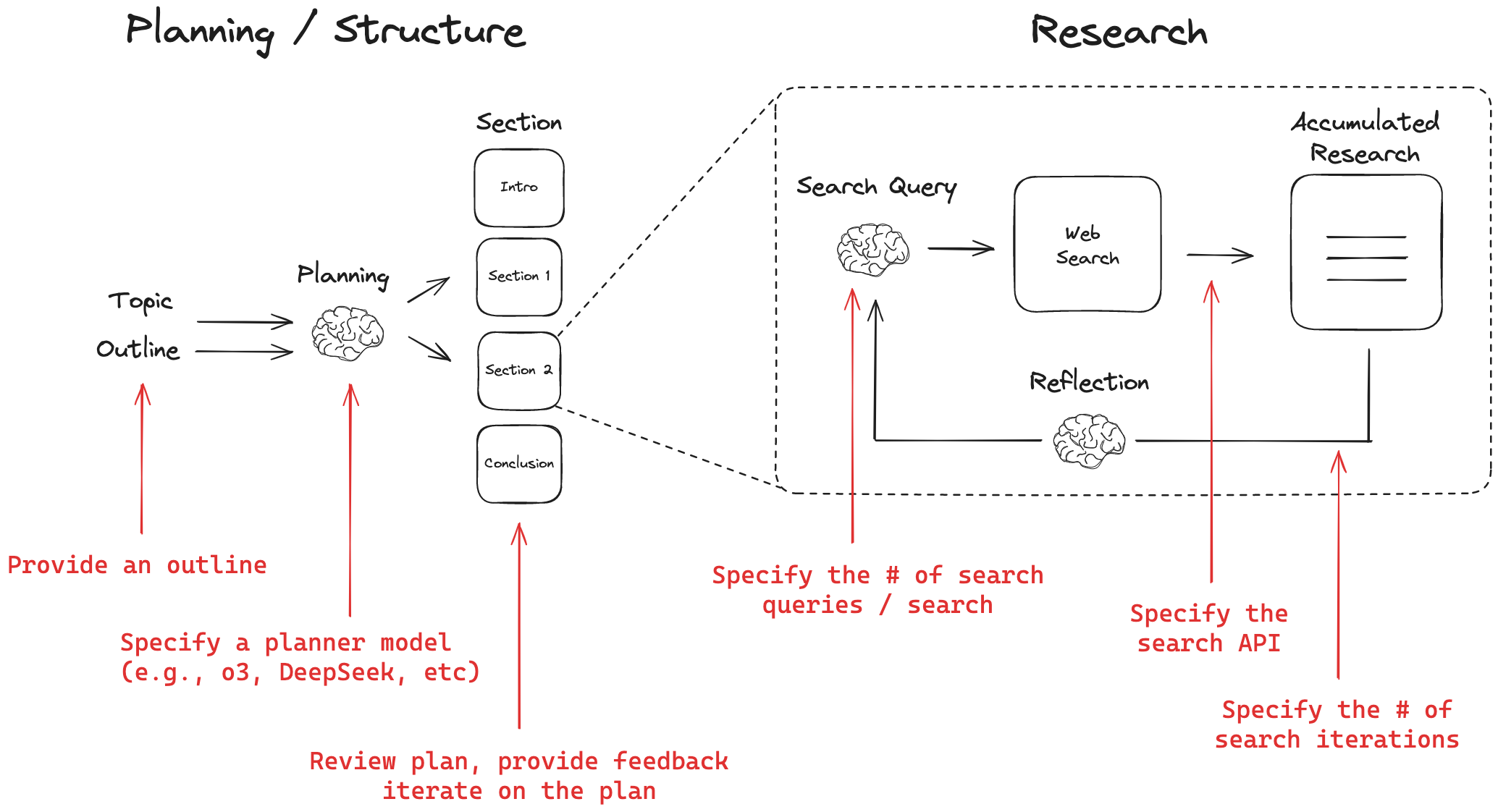
Fig. 30. An overview of the open deep research. (Image source: LangChain, 2025)
RL Agent 则是另外一种实现方法,通过 RL 训练推理模型来优化 Agent 的多轮搜索、分析与报告撰写流程进行优化。主要特点包括:
- 自主决策能力:系统通过强化学习训练,让 Agent 在面对复杂的搜索与内容整合任务时能够自主判断、决策和调整策略,从而更高效地生成报告。
- 持续优化:利用奖励机制对生成过程进行打分和反馈,Agent 能够不断迭代优化自身策略,实现从任务拆解到最终报告生成的整体质量提升。
- 降低人工干预:相较于依赖手工 Prompt 的固定流程,强化学习训练方式减少了对人工设计的依赖,更适合应对多变和复杂的实际应用场景。
下面的表格总结了这两种方式的主要区别:
特性 | Workflow Agent | RL Agent |
流程设计 | 预先设计固定工作流,任务分解和流程编排明确 | 端到端学习,Agent 自主决策和动态调整流程 |
自主决策能力 | 依赖人工设计的 Prompt,决策过程固定且不可变 | 通过强化学习,Agent 能够自主判断、决策并优化策略 |
人工干预 | 需要大量手工设计与调试 Prompt,人工干预较多 | 降低人工干预,通过奖励机制实现自动反馈和持续优化 |
灵活性与适应性 | 对复杂或变化场景的适应性较弱,扩展性有限 | 更适应多变和复杂的实际场景,具备较高的灵活性 |
优化机制 | 优化主要依赖工程师的经验调整,缺乏端到端反馈机制 | 利用强化学习的奖励反馈,实现持续自动化的性能提升 |
实现难度 | 实现相对直观,但需要繁琐的流程设计和维护 | 需要训练数据和计算资源,初期开发投入较大,但长期效果更佳 |
是否需要训练 | 无需额外训练,仅依赖手工构建的流程和 Prompt | 需要通过强化学习对 Agent 进行训练,以实现自主决策 |
OpenAI Deep Research
OpenAI Deep Research(OpenAI, 2025)是 OpenAI 于 2025 年 2 月正式发布的一款智能 Agent,专为复杂场景设计,能自动搜索、筛选、分析并整合多源信息,最终生成高质量的综合报告。该系统以 o3 为核心基座,并结合强化学习方法,显著提升了多轮迭代搜索和推理过程中的准确性与稳健性。
相比传统的 ChatGPT 插件式搜索或常规 RAG 技术,OpenAI Deep Research 具有以下突出优势:
- 强化学习驱动的迭代推理
借助 o3 推理模型 与强化学习训练策略,Agent 能在多轮搜索与总结过程中持续优化自身推理路径,有效降低错误累积导致的失真风险。
- 多源信息的整合与交叉验证
突破单一搜索引擎的局限,能够同时调用特定数据库、专业知识库等多种权威数据源,通过交叉验证形成更可靠的研究结论。
- 高质量的报告生成
训练阶段引入 LLM-as-a-judge 评分机制和严格的评价标准,使系统在输出报告时能进行自我评价,从而生成结构更清晰、论证更严密的专业文本。
训练过程
OpenAI Deep Research 训练过程采用了专为研究场景定制的浏览器交互数据集。通过这些数据集,模型掌握了核心浏览功能——包括搜索、点击、滚动和文件解析等操作;同时习得了在沙盒环境中使用 Python 工具进行计算、数据分析和可视化的能力。此外,借助在这些浏览任务上的强化学习训练,模型能够在海量网站中高效执行信息检索、整合与推理,快速定位关键信息或生成全面的研究报告。
这些训练数据集既包含带有标准答案、可自动评分的客观任务,也包括配备详细评分量表的开放式任务。在训练过程中,模型的响应会与标准答案或评分标准进行严格对比,并利用模型产生 CoT 思考过程让评估模型提供反馈。
同时,训练过程中复用了 o1 模型训练阶段积累的安全数据集,并专门增补了针对 Deep Research 场景的安全训练数据,确保模型在自动化搜索与浏览过程中严格遵守相关合规与安全要求。
性能表现
在评估 AI 在各专业领域回答专家级问题能力的基准测试 Humanity’s Last Exam(Phan, et al. 2025)中,该模型取得了 SOTA 成绩。
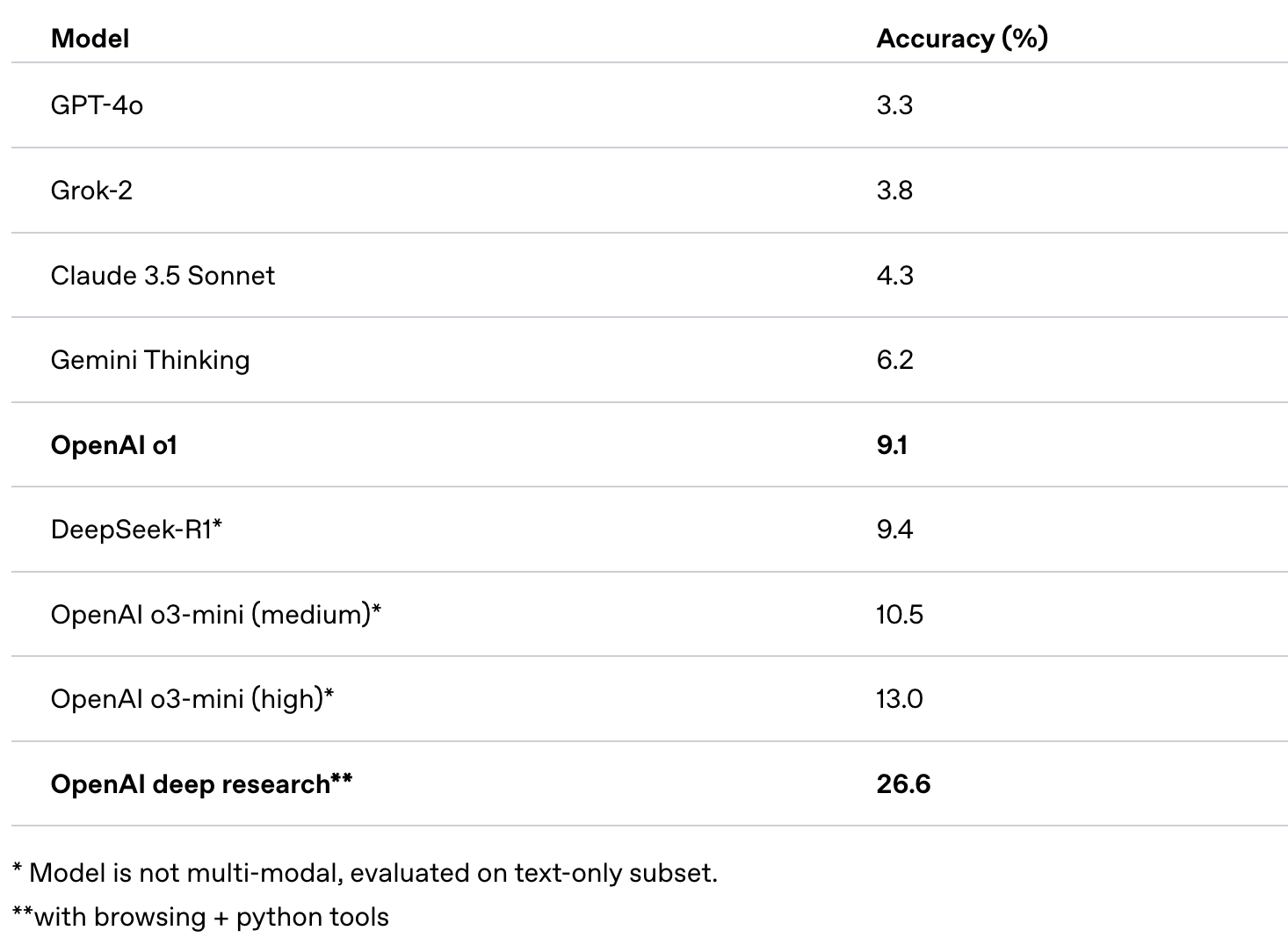
Fig. 31. Humanity’s Last Exam Benchmark Results. (Image source: OpenAI, 2025)
未来发展方向
智能体展现出广阔前景,但要实现可靠广泛应用,仍需解决以下关键挑战:
- 上下文窗口限制:LLM 的上下文窗口限制了信息处理量,影响长期规划和记忆能力,降低任务连贯性。当前研究探索外部记忆机制和上下文压缩技术,以增强长期记忆及复杂信息处理能力。目前 OpenAI 最新的模型 GPT-4.5(OpenAI, 2025)最大上下文窗口为 128k tokens。
- 接口标准化与互操作性:当前基于自然语言的工具交互存在格式不统一问题。模型上下文协议(Model Context Protocol, MCP)(Anthropic, 2024) 通过开放标准统一 LLM 与应用程序的交互方式,降低开发复杂性,提高系统稳定性和跨平台兼容性。
- 任务规划与分解能力:智能体在复杂任务中难以制定连贯计划、有效分解子任务,并缺乏意外情况下的动态调整能力。需要更强大的规划算法、自我反思机制和动态策略调整方法,以灵活应对不确定环境。
- 计算资源与经济效益:部署大模型智能体因多次 API 调用和密集计算而成本高昂,限制了一些实际应用场景。优化方向包括模型结构高效化、量化技术、推理优化、缓存策略及智能调度机制。随着专用 GPU 硬件比如 NVIDIA DGX B200 及分布式技术发展,计算效率有望显著提升。
- 安全防护与隐私保障:智能体面临提示注入等安全风险,需建立健全的身份验证、权限控制、输入验证及沙箱环境。针对多模态输入与外部工具,需强化数据匿名化、最小权限原则和审计日志,以满足安全与隐私合规要求。
- 决策透明与可解释性:智能体决策难以解释,限制了其在高风险领域的应用。增强可解释性需开发可视化工具、思维链追踪和决策理由生成机制,以提高决策透明度,增强用户信任,满足监管要求。
参考文献
[1] DAIR.AI. “LLM Agents.” Prompt Engineering Guide, 2024.
[2] Sutton, Richard S., and Andrew G. Barto. “Reinforcement Learning: An Introduction.” MIT Press, 2018.
[3] Weng, Lilian. “LLM-powered Autonomous Agents.” Lil’Log, 2023.
[4] Wei, Jason, et al. “Chain-of-thought prompting elicits reasoning in large language models.” Advances in neural information processing systems 35 (2022): 24824-24837.
[5] Kojima, Takeshi, et al. “Large language models are zero-shot reasoners.” Advances in neural information processing systems 35 (2022): 22199-22213.
[6] Wang, Xuezhi, et al. “Self-consistency improves chain of thought reasoning in language models.” arXiv preprint arXiv:2203.11171 (2022).
[7] Wang, Xuezhi, et al. “Rationale-augmented ensembles in language models.” arXiv preprint arXiv:2207.00747 (2022).
[8] Zelikman, Eric, et al. “Star: Bootstrapping reasoning with reasoning.” Advances in Neural Information Processing Systems 35 (2022): 15476-15488.
[9] Fu, Yao, et al. “Complexity-based prompting for multi-step reasoning.” arXiv preprint arXiv:2210.00720 (2022).
[10] Yao, Shunyu, et al. “Tree of thoughts: Deliberate problem solving with large language models.” Advances in neural information processing systems 36 (2023): 11809-11822.
[11] Yao, Shunyu, et al. “React: Synergizing reasoning and acting in language models.” International Conference on Learning Representations (ICLR). 2023.
[12] Shinn, Noah, et al. “Reflexion: Language agents with verbal reinforcement learning.” Advances in Neural Information Processing Systems 36 (2023): 8634-8652.
[13] Guo, Daya, et al. “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.” arXiv preprint arXiv:2501.12948 (2025).
[14] OpenAI. “Introducing OpenAI o1” OpenAI, 2024.
[15] Zhang, Zeyu, et al. “A survey on the memory mechanism of large language model based agents.” arXiv preprint arXiv:2404.13501 (2024).
[16] Zhang, Chaoyun, et al. “Large language model-brained gui agents: A survey.” arXiv preprint arXiv:2411.18279 (2024).
[17] Wang, Weizhi, et al. “Augmenting language models with long-term memory.” Advances in Neural Information Processing Systems 36 (2023): 74530-74543.
[18] Schick, Timo, et al. “Toolformer: Language models can teach themselves to use tools.” Advances in Neural Information Processing Systems 36 (2023): 68539-68551.
[19] Shen, Yongliang, et al. “Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.” Advances in Neural Information Processing Systems 36 (2023): 38154-38180.
[20] Park, Joon Sung, et al. “Generative agents: Interactive simulacra of human behavior.” Proceedings of the 36th annual acm symposium on user interface software and technology. 2023.
[21] He, Hongliang, et al. “WebVoyager: Building an end-to-end web agent with large multimodal models.” arXiv preprint arXiv:2401.13919 (2024).
[22] Yang, Jianwei, et al. “Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.” arXiv preprint arXiv:2310.11441 (2023).
[23] OpenAI. “Introducing Operator.” OpenAI, 2025.
[24] OpenAI. “Computer-Using Agent.” OpenAI, 2025.
[25] OpenAI. “Introducing Deep Research.” OpenAI, 2025.
[26] Phan, Long, et al. “Humanity’s Last Exam.” arXiv preprint arXiv:2501.14249 (2025).
[27] OpenAI. “Introducing GPT-4.5.” OpenAI, 2025.
[28] Anthropic. “Introducing the Model Context Protocol.” Anthropic, 2024.
[29] LangGraph. “A workflow of the LangGraph.” LangGraph Tutorials, 2025.
[30] Assaf Elovic. “GPT Researcher” GitHub Repository, 2025.
[31] LangChain. “Open Deep Research” GitHub Repository, 2025.
引用
引用:转载或引用本文内容时,请注明原作者和来源。
Cited as:
Yue Shui.(Mar 2025). 大语言模型智能体. https://syhya.github.io/zh/posts/2025-03-27-llm-agent